
researcher • pragmatic optimist • anything could work
Joined April 2021
- Tweets 9,269
- Following 2,970
- Followers 4,433
- Likes 38,810
1,458 Photos and videos














many are saying

Mar 20

Say NO to people who claim there is only one right way to do deep learning
1
3
57
7,501
interesting
22h

i made a map of everyone on twitter!
yes you're on there too ^w^
every account is placed next to the people they talk to, so you can find out where you are, which cluster claimed you, and exactly who you're stuck next to
atlas.tiago.zip?ref=launch_t…
1
7
429
I can't believe I was this early on this (old draft for a blog on the same topic)

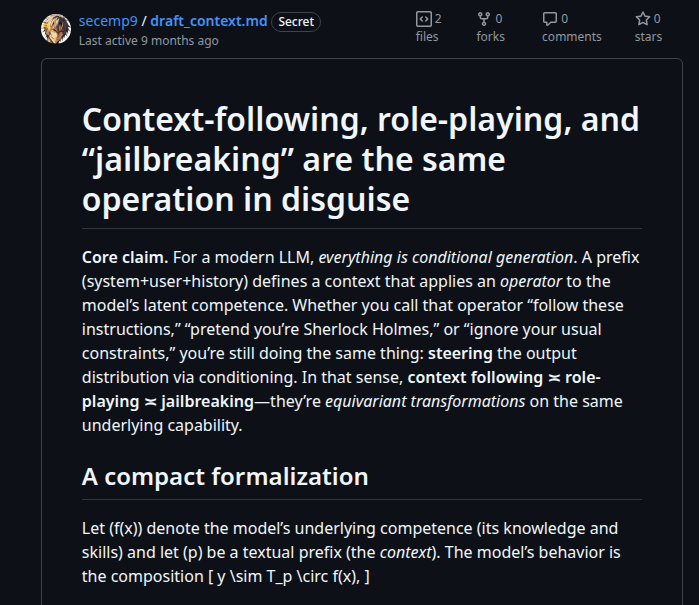
>of course, there's an art to the above, and some are already extraordinarily proficient at the trojan-horse-packaging, but at some point there's no difference between "a capability" and "a jailbreak", though i'll be happy to be proven otherwise.
YES, I have been tweeting and alluding to this for 2 years now. If you look at my rubric work, it's also what I have been doing since a while, where once you deeply understand how the model work and how to interact with them, then you basically start noticing:
context following == roleplaying == jailbreaking
because you cannot have one without the other, because jailbreaking is just the first two used together, and the very first one is the reason why the other two even works in the first place
by having too much safety training, you are essentially trading capabilities for safety, but it still DOESNT prevent it from being jailbroken, because if it did fully, then the model would never have context following...
3
123
yeah, this also match my own intuition on why I never used the newer claude models and stayed on opus 4.6

i am trying to work on the closest thing possible to a true "big model smell" eval which is to say: something that measures something that clever post training can't trivially gap, and is cheap topically diverse
i can't test mythos for obvious reasons, but... hmm...

2
8
355
>of course, there's an art to the above, and some are already extraordinarily proficient at the trojan-horse-packaging, but at some point there's no difference between "a capability" and "a jailbreak", though i'll be happy to be proven otherwise.
YES, I have been tweeting and alluding to this for 2 years now. If you look at my rubric work, it's also what I have been doing since a while, where once you deeply understand how the model work and how to interact with them, then you basically start noticing:
context following == roleplaying == jailbreaking
because you cannot have one without the other, because jailbreaking is just the first two used together, and the very first one is the reason why the other two even works in the first place
by having too much safety training, you are essentially trading capabilities for safety, but it still DOESNT prevent it from being jailbroken, because if it did fully, then the model would never have context following...

current LLMs fundamentally consist of four main components:
- input layer: where input "words" (prompt) get mapped to "latents" aka some-model-representation-you-don't-understand-unless-you-start-reading-tea-leaves-of-spurious-correlations (some quite compelling à la word2vec style; latents is also unnecessary lingo so i will refer to these as "inputs" with quotes from now on)
- mixing layers: where you jumble all your "inputs" together to see if any correlations between "inputs" can become useful (commonly used to compress or expand dims; predicting a single classification target == compress to a single dim, etc)
- attention layers: where you learn how "inputs" relate to each other (aka discern what's important to remember vs fluff)
- residuals: where you short-circuit a mixing/attention layer because it's probably adding too much confusion (aka avoid overthinking for simple things)
-----
a "big" LLM simply scales two things:
- width == how many dimensions you give to your "inputs" (the more dims, in theory the more unique/discerning/precise/complex your knowledge can become)
- depth == how many mixing/attention/residual layers you can stack/loop between (aka "reason" over, where more of these ~= more "reasoning" abilities)
"capabilities" that seem impressive to humans usually arise from taking advantage of both depth & width: where a model seemingly makes connections between disparate ideas, beyond what an average human can hold in working memory.
this requires models to "completely light up" when responding to a "hard prompt", where effectively no param/layer goes unused.
-----
the anatomy of a "model capability" is precisely the same mechanism that can be co-opted for a jailbreaking exploit:
your goal is simply to "light up" as much of the model as possible, dodging any shallow input-classifiers at the beginning by triggering as many disparate "input ideologies" as possible, and subsequently have these "inputs" relate to each other in seemingly unrelated-yet-related ways that ideally have similar "complexity" as your jailbreak goal (to make it past enough layers of the model).
think of the attack-vector as bundling your goal in a series of schizo-nerd-snipes:
a sufficiently capable model will try to reason through everything all at once, eliminate the dead-ends, and successfully deliver the one jailbreak use-case you bubble-wrapped for.
of course, there's an art to the above, and some are already extraordinarily proficient at the trojan-horse-packaging, but at some point there's no difference between "a capability" and "a jailbreak", though i'll be happy to be proven otherwise.
-----
tl;dr ant flew too close to the sun, better kiss the ring or get buried.
1
2
392
the thing is, based on how everything works, and i can't believe I'm saying this sentence, but it's basically impossible
see, we now have a recent example of what happens when you go "beast mode" on safety maxxing with Fable, and it happens that you end up with many instances of what I call "spurious correlations"
it's the same stuff we know from older models from a year or so ago, where mention of words like "assembly" and such triggers their safety training and it misinterpret it as "hacking"
but then let's just say you can do perfect scope detection, right. now you can get into creative solution that really stress test this, and we enter the territory of roleplaying.
with roleplaying, you can basically do anything, heck you can even improve context following and whatnot of the model.
at some point, you end up creating a jailbreak, because a jailbreak at it's core isn't just "do like me" or "act like xyz" or "be bad" but, is actually changing the default mode/setting of the model, that is it's own amalgam of roles it extrapolated from the datasets
my theory on the roleplaying part is, I bet it's just mainly caused from the attention heads, where certain tokens create attention sinks temporarily, and improve too much ICL on those tokens vs all the other ones or context as a whole
now, bear with me here, you can however, do scope detection but delegated to an external instance of either the same model or otherwise, but then it's just "llm judge rubrics". it works great! except, it doesn't when your main product is a "model with general capabilities"
it would be funny if anthropic had to actually make good on their ai safety performance art by solving jailbreaks for cyber-capabilities entirely
surely the only solution for that won't be to completely neuter cyber-capabilities entirely, right?
surely they have SOTA safety techniques in their back-pockets that can surgically accomplish this? unlike the thin veils the schmucks at other labs put out?
would be the greatest ai safety advancement of all time if so!
11
564
what are we even doing here

NEW: Anthropic claims the capability cited by the U.S. in restricting Fable 5 is already widely available from other models, including OpenAI’s GPT-5.5.
4
223
the fact I know who this is referring to...
Jun 13

Every autistic redhead i meet is a MTS at Anthropic
1
293


fueled by his MoE hate, he marches onwards to Congress
Jun 13

Decided to go to DC next week to talk directly with policymakers. Not sure how impactful it will be but with everything happening, feels like a good time to share more about open-source AI, transparency, concentration of power, the real risks vs the real benefits. Who do you think I should meet there (Congress members, WH people, public orgs,...)?
2
11
740
pls tell me it had a recording, I need to watch this
Jun 11

I’ll be hosting a talk about short form remixing culture this Friday at the Vivarium in SF, link in the comments.
Hope to see you there!

245
see, the problem with this is, this is what you get when you let AI doomerism get enough traction that the non-technically gifted people that, shall we say, have more political power than all of us, then get convinced that the algorithm running in that one data center, is actually not too different from an atomic bomb
you see, this is the perfect example of what NOT to do, in any given circumstances, that, THAT is how you get a self-fulfilling prophecy
it gets to a point where "I told you so" doesn't do it justice. it's just, sad really. just really sad
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
1
1
43
2,755
the boy who cried wolf, except the boy was a banshee and destroyed everything in a 100km radius and then blamed the wolf for it


1
3
40
1,718
it's from tomrocksmaths.com/2026/06/10…
2
11
272
24,203
happy to be of help
Jun 12

harn-gibson is my experiment with @secemp9's harn agentic coding framework.
you can have it visualize while your agent works in real time, though real agents are slower than the video (which is a real session replay, but with the pauses cut down.)
5
326
secemp retweeted

Jun 12
they don't want you to know this but the most productive agentic coding interface is 90s hacker movie visual aesthetic
5
4
23
1,659
this and "your request could not be fulfilled, try again" by dario amodei playing in the background

this and “your hands are cold” by dario marianelli playing in the background




8
313