
Security and Privacy are just Myths!
Joined January 2020
- Tweets 172
- Following 547
- Followers 1,150
- Likes 1,490
18 Photos and videos










Pinned Tweet

2 May 2025
Who knew that one conversation would turn into a million-dollar journey of a collab? Forever grateful to this community and the grind. Here’s to many more bugs and breakthroughs with @n1m0_ and @_jensec bhai. 🚀
2 May 2025

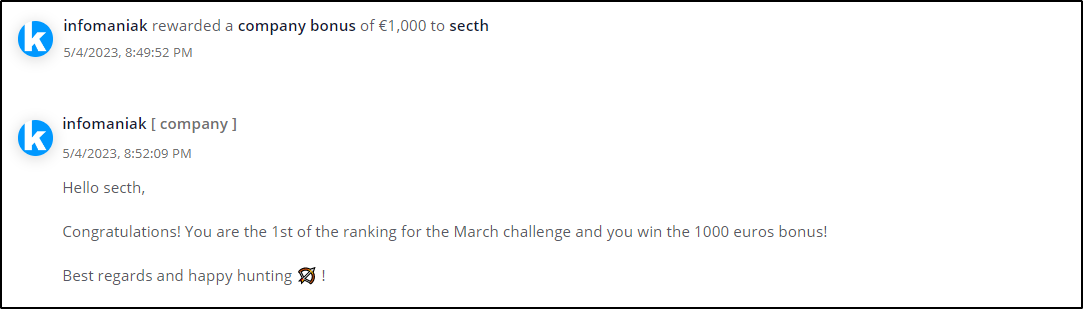
Bug Bounty Success Story: $1M total bounty.
No Tech Background
No Paid Courses
No Certificates
Just Sheer Willingness and Hard work.
I still remember the day 1 when my now close friends
@secseth_ & @n1m0_ asked me to discuss about bug bounty. and now they completed $500k each on @Hacker0x01 a few years later.


7
83
7,174
Bhavy Seth retweeted

May 5
In the next 12-18 months there’s really never been a better time to make a million dollars doing bug bounties. If I was young and poor I would be locking myself in a room from now until this time next year and making finding a reproducible methodology or way of hacking that I can scale my primary and only objective in life.
14
58
673
54,135
Apr 14
WTH! It's really frustrating. gave them every possible detail for them to trust. not a very good impression @AnthropicAI
191
Apr 10
1/ Bug Bounty won't die. But it's shifting towards an agent-driven pipeline structure.
The hunters who will thrive aren't the ones prompting models, they're the ones building pipelines efficient enough that the agent knows what to look for.
#bugbounty
1
4
256
Apr 10
2/ The gap between “using AI” and “weaponizing AI” in bug bounty is massive. Right data, right tools, right context, right prompt. Nail the pipeline, and it won’t matter which model you use.
1
97
Apr 9
Bug bounty is not going anywhere.
Apr 9

I'm extremely unconvinced that Opus wouldn't have found that 27-year-old OpenBSD bug Mythos found if they spent $20k credits on it.

3
411
Apr 3
agents that own their own knowledge layer do not need infinite context windows, they need good file organisation and the ability to read their own indexes. this hits same for bug bounty. everyone's using the same models, the edge is what you teach "yours" to "remember".
Apr 2

LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
1
111
Mar 30
I can never fully express what I want in a single prompt. My words miss things. The picture in my head doesn't fully translate. So after Claude builds the plan, I tell it: "Now act as a harsh critic of your own work. Find every flaw, every gap, every assumption you made."
1
1
114
Mar 30
What happens: it surfaces problems I couldn't even articulate and each round forces ME to think deeper about what I actually need. I went through 12 rounds of self-critique on a feature architecture. The final result was unrecognizable from v1 in the best way.
75
Mar 13
Security layer is getting thin day by day
Mar 13

Perplexity Computer is now on mobile.
Start any task on any device. Manage Computer from your phone or desktop with cross-device synchronization.
Available now for iOS in the Perplexity app. Coming soon to Android.
2
207
21 Sep 2025
An amazing person, always wished to meet him in person. Had some truly great conversations with him over chat. he was deeply passionate about the bug bounty industry and genuinely cared for researchers. Gone too soon. May he rest in peace.🤍🙏
21 Sep 2025

Peace out world. Best wishes to all. ALS has won this battle, but hopefully not the war!

1
10
1,505
19 Sep 2025
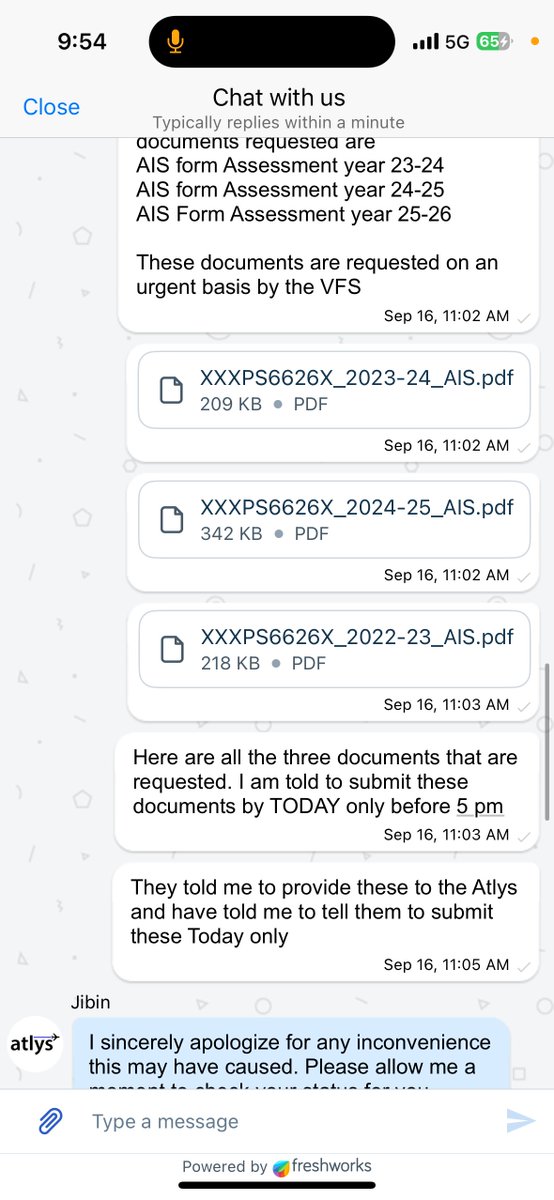
Hey @atlys, this is beyond unacceptable. I applied for a guarantee visa application, and till now, NO visa. My flights are next week(which I informed you from day one). I submitted additional documents, yet VFS status still shows they were NOT submitted by your team.
1
3
24
5,999
19 Sep 2025
@atlys What kind of careless, unprofessional service is this? Do you even take customers seriously? In your app, status changes automatically. In your app, it shows today I will get the Visa, while the VFS status shows documents are not even submitted. What an irony!
2
1
7
1,298
6 Sep 2025
It is truly an honour🙏. Huge thanks to @Hack_All_Things and entire @Zoom team for running such a great , transparent and responsive bug bounty program. It’s a privilege to contribute in such a program. Grateful for the recognition💙. @Hacker0x01
6 Sep 2025
Friday @Zoom Bug Bounty researcher spotlight on @Hacker0x01 researcher @secseth_ . One of our top security researchers with over 40 valid report submissions to the @Zoom #bugbounty program! Thank you Bhavy for all your great work and gracious professionalism!

1
24
2,331
10 Jul 2025
Always a Great Team to work with🔥🔝
10 Jul 2025
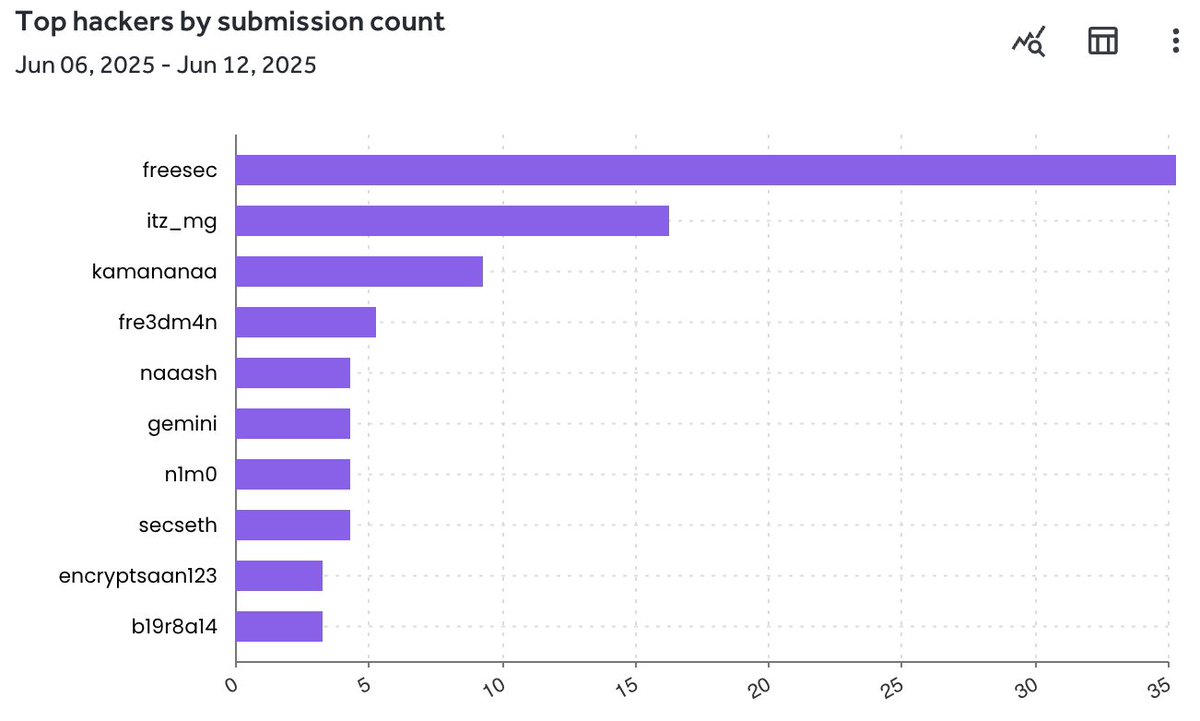
The D-Day Campaign top contributors results are in! Congratulations freesec on being the top report submitter! Thanks to all for your participation. DM me your shipping address on Zoom chat to receive promised @Zoom swag!
7
806
12 Dec 2024
🐬 Proud to share my 2024 #HackerOne journey: 52 validated reports including 14 critical findings! Special thanks to @Hacker0x01 for providing the platform to make the internet safer, one vulnerability at a time. Here's to more bug-hunting adventures in the digital ocean! 🌊
7
2,147
Bhavy Seth retweeted

1 Nov 2024
We just closed our fiscal Q3, and our GTM teams worked incredibly hard to give hackers more attack surfaces to find vulnerabilities in by signing up 150 new customers to @Hacker0x01. That is a lot of new stuff to hack on!
6
6
53
5,306
Bhavy Seth retweeted

31 Oct 2024
Pick a niche, become an expert, find bugs maybe even 0days or reverse n-days, and write blogs. Even if you don’t hit those $100k bounties, it’ll be a stepping stone toward a $100k job.
What niche? How to pick? Examples?
infosec being so vast from web3 sec to web2, mobile, desktop, recon, client-side, server-side, cryptography and so on. These are umbrella terms, but if we zoom in, there are specific areas where spending a lot of focused time will make you a top 20 expert -- 100% sure.
The key thing is, that the current top 20 experts in any niche will eventually be replaced as they get bored or burned out. This leaves room for you, and the easiest way to pick a niche is to learn from an existing expert in the niche, take inspiration, and grind to build on top of it.
1. For instance, I got into the client-side JS niche by following @terjanq’s work. From there, I went down even further to focus specifically on ElectronJS.
2. Another example: @rootxharsh and @iamnoooob their niche is in reversing n-days and finding new ones based on that knowledge. I don’t think anyone in India can compete with them on reversing n-days, writing blogs, and submitting findings to bounty programs.
3. And off the top of my head, @ajxchapman, from his tweets, seems to have a specific niche in V8 n-day exploits. I don’t think there’s anyone else in the web security scene who can write V8 exploits 😅.
4. Like @orange_8361 , pick a complex target and grind on it for months eventually uncovering mind-blowing findings.
5. Or, like @albinowax, choose a complex specification, such as HTTP, and find bugs from every aspect of it from top to bottom
(Sorry for tags xD)
I could list so many more people, but my point is this: if you look at the top bug bounty hunters or experts, there’s a pattern. Their blogs or tweets consistently focus on a specific niche (or two) for years and years. No one ever becomes a pro in a night.
How to Become an Expert in a Specific Niche?
Spend a lot of time. There’s no shortcut. Follow the work of the expert you picked for inspiration, read their blogs, dive into the blogs they learned from, and explore everyone else in that specific niche. Solve CTFs and write about them.
For example, not to make it all about myself, but just as an example. I’ve read every blog from the people I listed as inspirations(blog.s1r1us.ninja/inspiratio…) while learning client-side security.
If it’s taking time to understand, you’re likely on the right path. That’s where most people give up, so keep pushing. Just dedicating days to it will put you ahead of at least 100 others. It’s that simple.
Expert = Spent Time × IQ
Find Bugs or 0days, Reverse n-days, and "Write Blogs
Once you’re an expert, finding bugs will start to feel natural. But let’s be real, sometimes you might not get lucky. When that happens, reverse other n-days and write about it. I mean write about anything. Nothing gives you as much exposure as writing blogs: you’re helping others, plus you’re building a network that will eventually help you land a $100k job or $100k bounties.
23
227
1,025
113,700
Bhavy Seth retweeted

17 Jul 2024
🚀 Exciting News
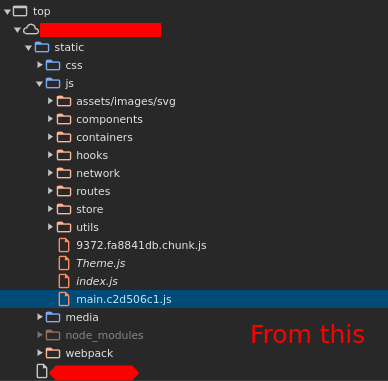
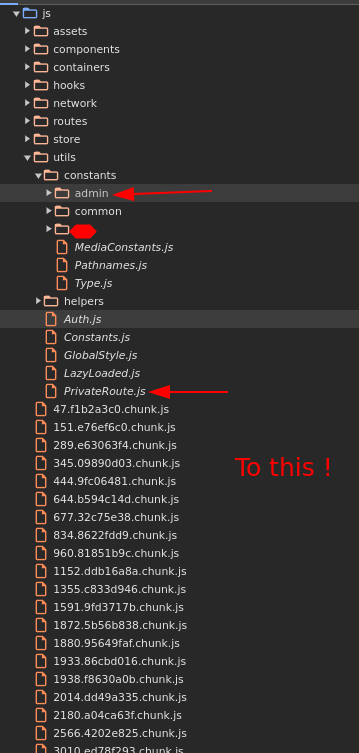
I just released a (dirty) Chrome extension that lets you load all chunks of a React app in seconds. Perfect for finding hidden features using Chrome's inspector or parsing .map files using your browser !
github.com/ElSicarius/chunkl…
#bugbountytips #Pentesting
6
54
236
18,351
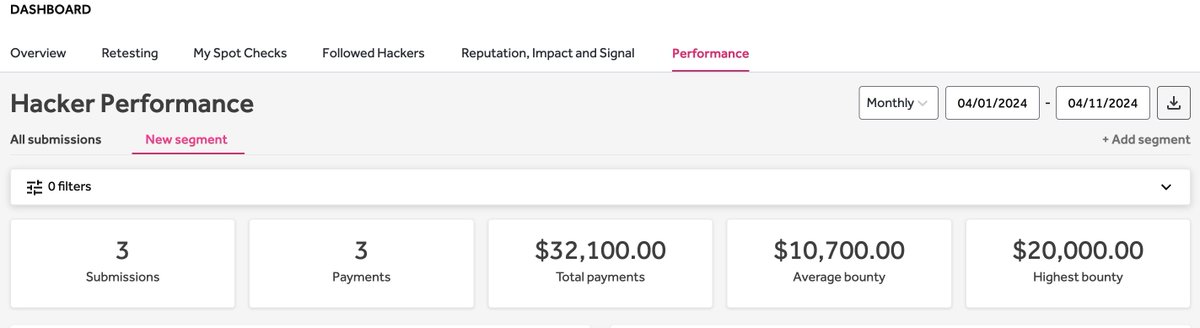
11 Apr 2024
Reached an Impressive Milestone this April. Feeling blessed and geared up to conquer even more
Shoutout to @Hacker0x01, an amazing platform✨
#togetherwehitharder
11
2
137
12,566