
76 Photos and videos










CJ Hess retweeted

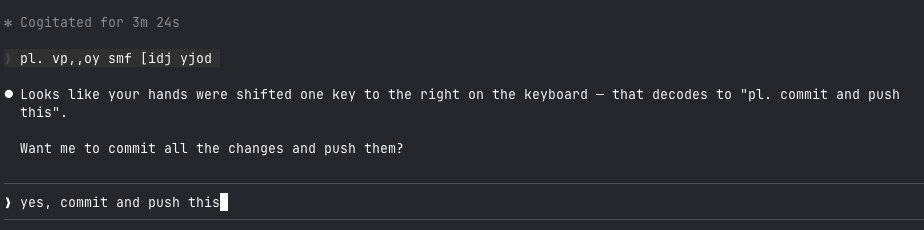
I need to hire 50 people in the next 6 months.
@tenex_labs is a rocket ship. Unlike anything i've seen.
We've quickly become the go-to applied AI partner for some of the biggest enterprises in the world.
Our biggest bottleneck is keeping up hiring with the tidal wave of demand we're seeing.
Which takes me to the first role I need to fill: AI Strategist.
You are the voice of the customer.
If a customer success savant & world-class PM had a baby, it'd look like our AI Strategist.
The job: Translate client goals into reality by uncovering bottlenecks and inefficiencies, aligning stakeholders, and executing change‑management and software‑implementation plans that unlock AI‑driven leverage.
Must haves: deeply technical previous experience as a technical consultant, PM, sales engineer, or similar role.
Nice-to-have: experience at a large management consultancy or a boutique AI consultancy.
Second, is their technical partner: the Forward Deployed Engineer.
Must-haves: elite engineering chops, AI-first mindset,
relentless curiosity, team multiplier, client-facing.
Oh...one more thing...your comp range is $250,000-$800,000.
Why? It's uncapped (based on storypoint output). We pay you like a salesperson.
Link to the jobs here: tenex.co/about-us
37
13
214
34,715

Jun 15
If you write code, you are feeling the effects of last week. I think this is a pretty scary precedent, the government forcing a publicly available frontier model out of the market.
For about three days I had Claude Fable 5. It's definitively the best model I've ever used, and I had big plans for this week with it. For the first time in a while, it felt like a real step change had been achieved.
Then, commerce sent Anthropic a letter on June 12th barring every foreign national from the model, including Anthropic's own employees. The only way to comply was to kill it for everyone. By the weekend, the best model in the world was gone.
The thing they called "dangerous" was basically the model reading code and finding flaws in it.
Soooo just debugging.
That's the most ordinary thing any of us do with these tools all day. Anthropic said the flaws were minor, already public, and GPT-5.5 finds them too with no jailbreak at all. GPT-5.5 is still running....
I'm having a hard time buying the capability story. After the tiff between Anthropic and the administration earlier this year, I worry this is more personal, and that should bother you more than the ban.
The last time Washington treated consumer software like a weapon was encryption in the 90s. It got put on the same export list as missiles, and it took a decade of lawsuits to fight that back.
Now it's happening to a shipped model. My hope is that this is a one off, but if it becomes a habit to pull the frontier models, it will affect us as the users more than anyone and create the dystopian gated control we are all fearing.
This always was about the same timeline as AI 2027....
It's abundantly clear that the tools I now rely on are not mine.
The government can make the lab pull it, and in practice it does not have to explain much.
And this doesn't stay with coding. Today it's easy to shrug off because developers took the hit, and everyone else can treat it like somebody else's fight. But the thing Fable got flagged for is exactly the thing every useful model is getting better at: reading a messy system, finding weakness, and suggesting a fix.
That's security. It's medicine. It's finance. It's the tools your whole company runs on.
"Too capable" is not a line one model crossed. It's a moving line the whole field is running toward.
I want to steelman the other side a little, because "government bad" is too easy and a model that's genuinely good at offense shouldn't be treated like a toy. If the UK safety institute got Fable to gain access into real systems around 73% of the time, its' definitely not a toy. I don't want a world where labs dump offensive capability on the internet and everyone shrugs.
But if that's the standard, then show the standard. Have a hearing. Publish the test. Say what line was crossed.
But now we're left waiting for it to come back out right after getting a taste of the future.
6
2
23
29,985
Jun 12
This goes along with loop engineering. Here is the 5 step process I am relying on right now:
1. Spend some time on an idea with 5.5 low. Gather up context, understand roughly what you want to do, and gather up a context doc that include file paths to docs, code, and any "exploration" files you made. For me, these are often having 5.5 explore an api, pull in a bunch of data, etc.
2. Put that doc in front of Fable to save on exploration tokens and give it a great anchoring point, then use your favorite planning skill to make a high fidelity plan. For me, this is /super-plan.
3. Once you feel strong on this, hop back to 5.5 extra high and have it use tons of subagents to review this for missed angles, potential bugs, and overall quality code.
4. Feed the above back into Fable until you are happy. Then, setup a goal framework for this plan. For me, it looks like this with /goal-creator:
state.md -> holds A/C and their progress
log.html -> a log with screenshots, decisions, and anything that the agent has done.
steps/
step-1-plan.md -> plans for each step with most of the diff already written out.
notes-from-the-boss.md -> Fables notes during implementation (we'll come back to this)
5. Then have fable output a /goal prompt. These usually just point to the original plan and these goal specific files and loop til all A/C is hit.
6. Hop into gpt 5.5 extra high and run the goal prompt from above. This run will work through each piece, keep a robust decision log, and work through it.
7. Finally, on the side I often have Fable schedule a 20 minute Cron to check in on the implementation and put it's thoughts in notes-from-the-boss.md. The /goal prompt includes instructions to check this regularly and update the plan files for any details.
This loop needs work and I think a lot of developers are landing on similar flows. I have had the best results with this setup since Fable dropped.
Jun 11

Claude Fable can run autonomously for days.
This is the single highest-leverage prompt I use to stay on top of it:
"Spin up a persistent HTML page. As you work, append clear, timestamped updates with screenshots/media so I can follow along."
Literally a 10x better experience.
1
3
33
10,066
Jun 11
Hiring engineers right now is really hard.
We've been in the thick of it @tenex_labs and most of what we used to rely on doesn't work anymore.
All the old signal lived in artifacts. A resume, a leetcode submission, a take-home. The whole process was built on artifacts because artifacts scale.
Every one of them can be generated now.
And the honest candidates typically look worse because real human output is slower and rougher than a model's, especially with a time constraint.
We've had candidates come in with great take homes who couldn't explain the system they built. You ask "how did you structure your solution?" and it's like you're watching someone learn their own architecture for the first time.
But once you get the candidate in the room, hiring is actually easier than it used to be. You just have to stop grading artifacts and see the person operate.
We look for two things.
1. Systems-level thinking: Can they hold the whole problem in their head, see how the pieces connect, notice where it'll break before it breaks.
2. How they operate a the tools: Can they set up the context for a real coding problem with an agent and work toward a solution? Watch what they ask for. Whether they read the output or just accept it. When they interrupt the model and when they let it run.
There's no Cluely for thinking out loud and those communication skills are more important than ever.
It used to be you solved the problem or you didn't. Now the job is talking to models, steering the work, knowing when the output is good and here's a huge gap between doing that well and doing it badly, and no test suite can score it.
And writing gets graded on taste. When a model can produce ten working versions of anything, "it works” doesn’t matter. What matters is how the solution is shaped, how the code is shaped, how the UI feels.
Communication is similar. Code used to be slow, and the slowness covered for a lot of bad communication. Now a fuzzy requirement turns into the wrong thing shipped a day later.
This goes way past engineering though. Every job on a computer is two things, the skills and the judgment around them. Agents are absorbing the skills and the human is left as the driver and communicator.
Engineering is just a bit ahead of the rest.
The hard skills became automated. The soft skills became the job.
If you resonated with this and want to step up your career @tenex_labs apply from the link in the comments.
1
5
623
Jun 9
Sniff sniff, it's a big model sir
Jun 9

The Claude Fable 5 Review: One Billion Tokens, Judged by a Non-Engineer
I spent a billion tokens testing Claude Fable 5 on real projects: UI and UX, writing, strategy, security, engineering, and knowledge work. The kind of work I actually needed to ship. And I will be straight with you. It truthfully felt like I had an unfair advantage. Here is why:
First, the lens. I am not an engineer. Most model reviews come from engineers running engineering benchmarks. This one comes from a non-engineer who used Claude Fable 5 to do work that used to require a team of them. If you do knowledge work and you want to know whether this model changes your day, this is written for you.
A note on naming: Claude Fable 5 is the first model in Anthropic's new Claude 5 family, a new tier that sits above Claude Opus and the most advanced Claude model generally available. I had access to it before launch, so everything here comes from real work, not a demo.
Why the eye test
Most reviews drown you in benchmarks. Scores on tests you will never run, against tasks that look nothing like your actual work. They tell you a model is smart. They do not tell you whether it earns its keep.
To be clear, the benchmarks are not in question this time. Claude Fable 5 is state of the art on essentially everything it was tested on, and by a real margin. This is a genuinely exciting release. But that is not the reason I am writing. Qualitatively, this is a step change that earns its major version bump, the same order of leap I felt when 4.5 landed last November, and that is exactly what no benchmark can show you.
I evaluate differently. I put a model into real work and watch what happens. Does it save me hours or cost me them? Does it catch what I missed? Does it feel like a partner or a tool I have to babysit? That is the eye test, and it is the standard I am holding Claude Fable 5 to here.
The short version: this is the first model in a long time that passed on every dimension that matters. Not by a little.
The lens: what I actually measure
I threw all of that work at it. Here is what I look for when I judge the results:
1. Big model feel: Does it feel like a real step up, or a slightly better version of last month?
2. Building and shipping: Can it take an idea to a working, shippable result?
3. Writing and voice: Can it sound like a person, and like me specifically?
4. Finding what others miss: Does it catch the hard, hidden problems?
5. The human factor: Does it anticipate what I need before I ask?
Then I weigh all of that against cost, with real numbers. Here is how Claude Fable 5 scored.
1. Big model feel
I have not felt this since Opus 4.5. From the first serious task, Claude Fable 5 gave me that big model feel. The sense that you have an unfair advantage just by using it. It is a major step up, not an incremental one. Reasoning, writing, building, security. It is strong across the board, and it shows up the moment you start working.
You can also feel it thinking longer and working a problem more deliberately than other models do. The clearest sign: even when I handed it solid prep materials, it did not just stay inside them. It read my files, read the actual situation, and then went and found a better path outside the box I had drawn, instead of grinding away inside the environment I told it to work in. That initiative led to a noticeably better result than I would have gotten if it had just followed my setup.
2. Building and shipping (UI/UX)
This is where it announced itself.
I was rebuilding our Tenex site to modernize the stack for agents. Not a cosmetic rebrand. The goal was to move off the old setup onto a foundation built for the agentic era, with the tech stack, agent stack, and AEO it takes to win where the work is heading. The site is very custom, which made it hard. Here is the ladder I climbed before Claude Fable 5.
GPT 5.5 and Claude 4.8 tried the build on their own. Neither came close. So I brought the design into Figma, then pulled Figma into Claude Design. Claude Design got the closest yet, around 90 percent of the look, better than the models working alone, but it missed a lot of the motion and the special design touches. Good enough for a v1 pass, so I handed that file to 4.8 and GPT 5.5 to turn into the real site. Even then they struggled to match the Claude Design file. I had to push hard, and they landed around 85 to 90 percent, with the original Figma files to reference the whole time. At that point I was not sure I could rebuild this thing at all.
Then Claude Fable 5. It looked at all the files and said it could do better. It went straight to the source, the original Webflow site, downloaded every asset, and rebuilt the whole experience one page at a time. It nearly one-shot the entire thing.
I did not stop there though. I then built a second, entirely new site, with a fresh design: modern tech stack, agent stack, skills, SEO and AEO optimized, 80 pages ready to ship over a weekend and it turned out incredible. I would have easily charged $50k for this in the past as an agency owner. Fable legit built it in a weekend.
I also had Fable build a full programmatic clip factory, and it wired the whole stack together: @HeyGen for avatars, @HyperFrames_ for motion graphics and editing, @ElevenLabs for audio, Cloudflare Workers, and a VPS. It is not perfect yet, but it got me much further than I expected. It runs the entire pipeline: finds the topics, writes the scripts, makes the thumbnail, edits the video, composes the music, adds the motion graphics, and posts to social. I ran it in the background while I pushed through my other builds. It worked for long stretches on its own, and at one point it built itself a fetching system with webhooks to monitor renders across the different platforms. It even took clear visual direction from reference material and matched it. This is the long-horizon, run-on-its-own work that earlier models could not hold together.
3. Writing and voice
I had been rebuilding our brand voice with a combination of GPT 5.5 and Claude 4.8: the voice style guide, the tone we write in, all of it, using our website as the reference. Both 5.5 and 4.8 did a commendable job turning the site into a voice doc.
Claude Fable 5 replicated that voice doc almost identically, then did the thing the others could not. It took the style guide and wrote with it across 80 pages of the new site: features, case studies, blog articles, playbooks. Once it was trained properly on what I wanted, it gave the most honest nod I have seen to the original reference material, and then expanded that voice cleanly across brand-new surfaces without losing it.
Two things stood out. First, it wrote like a person, not the flat AI default that everyone can now spot from a mile away. Second, it held the voice across a whole site instead of drifting after a few paragraphs, which is usually where models fall apart.
The test I use for AI writing is simple: how much do I have to redo. Most models save you the blank page and then quietly cost the time back in edits. Claude Fable 5 was the rare case where the draft was close enough to actually use.
4. Finding what others miss (security)
This one I expected but not at this level.
I had a very large repo. Both Claude 4.8 and GPT 5.5 have been working in it without ever flagging this risk. Claude Fable 5 found a serious bug on its first go with the repo. Sneaky, well hidden, the kind two frontier models had just told me was not there. Then Fable patched it on the spot.
Sit with what that means. The bug was going to ship. Two of the best models available had signed off on the code. If I had stopped there, like most people would, it goes to production and I find out the hard way. Claude Fable 5 did not just match the other two, it caught what they missed, on the exact kind of work I am least equipped to check myself as a non-engineer. That is the value that is hard to price until the day it saves you. One catch like it can pay for the whole tool.
5. The human factor
The thing that stuck with me most was small. I asked it a question while I was waiting on a cron job to finish. It answered, then added on its own that I had about 10 minutes left on the timer and that it would let me know when it was done. I never asked about the timer. It just knew I would want to know and gave it to me.
That is not AGI, but it is the closest thing I have felt to a model that anticipates you instead of just responding to you. That is what makes it feel less like software and more like working alongside someone sharp.
The receipts
I tracked this, so here are the real numbers. Start with cost, which depends entirely on which models do the work.
Cost for this workload: Claude Fable 5 | $1,442 (1.04 Billion tokens)
But that badly undersells what I actually got. Over a few days I built a shit load of things, including a new website, all of its infrastructure, and a working agent package. As an agency, I would have charged a client $30,000 to $50,000 for that alone, easily.
So here is the question that cuts through the math: if I had to pay $1,450 in tokens the the result I achieved? 100 percent. Without hesitating. The quality was that good.
That is the lens that matters. On hours alone, even at full price, it already pays for itself several times over. Measured against what the finished work is actually worth, it is not close. The cache-heavy volume still drives the bill, which is why how you run it matters. But do not let the math fool you into thinking this is marginal. It is the best money I have spent on tooling.
Where it frustrates: with that being said, you feel the meter more than any other model, and the meter is real
The receipts above are why cost is still worth watching, even though the work was worth every dollar. Anthropic does not hide this. They call Fable 5 token-intensive by design, built to think longer and verify more, and it runs through usage limits about twice as fast as Opus or Sonnet.
That is the case for the one thing I want most: an auto-router for task complexity. Right now I have to shift gears by hand mid-conversation to conserve tokens, and I do not want to think about that. If I ask for something simple, the model should downshift on its own and handle it, saving the expensive intelligence for the work that actually needs it. This is not just about flow. It is the economics. A smart router keeps the simple work on cheap models and only escalates to Claude Fable 5 when the task earns it, which is the whole difference between 2.5 efficiency and 9.7. Until that exists, using a frontier model well means doing the routing in your own head with active shifting in model effort levels.
Pro tip #1: run it as a hybrid
Here is how I keep the cost in check without giving up the intelligence. Do not run everything on Claude Fable 5. Run a relay across models.
1. Think with Claude Fable 5: Use it for the expensive thinking: high-level planning, strategy, architecture, mapping the whole approach before a line of work gets done. This is where its edge is biggest and the token count is smallest.
2. Build with 4.8, GPT5.5 or Sonnet 4.6: Hand the plan to a cheaper model for the legwork: the implementation, the repetitive passes, the high-volume grunt work. That is the work that runs up the bill, and it does not need a frontier brain.
3. Review with Claude Fable 5: Bring it back to Claude Fable 5 to check the result. This is where it earns its keep a second time, catching what the cheaper models miss, the way it did on the security scan.
You get the deep strategy and a frontier second set of eyes, and you keep the expensive model off the high-volume work that drives most of the cost. Frontier thinking, cheaper hands, frontier review. It is the closest thing to an auto-router until the real one shows up.
Pro tip 2: match the effort setting to the task
Fable 5 has effort settings, and they matter more than you would expect. Effort controls how hard it thinks before it answers, which means it also controls your bill.
1. High is the sweet spot for most work. Start here.
2. Extra high for the hardest, long-running tasks where you want it to grind.
3. Low or medium: for quick, back-and-forth sessions where you do not need the full engine.
Reaching for extra high on simple work is how you burn tokens for nothing. Dialing down to low or medium on interactive chats keeps the cost sane. It is the closest thing to the auto-router I want, just done by hand. You pick the gear, the model does the rest.
Pro tip #3: let it audit your own setup
One more move that paid off: point Fable 5 at your own setup. Have it review your most important skills, your CLAUDE.md files, and your configs to make sure they still make sense.
Most of that scaffolding was written for weaker models. It is full of hand-holding steps, workarounds, and assumptions a smarter model does not need and can be held back by. This is a major jump in intelligence, and you do not want to cap it with outdated instructions or stale data. Let the smarter model clean up the rules it has to follow, then get out of its way.
Pulling back
Let me be honest about where I am coming from. I use every tool out there. Claude is my daily driver, but I am constantly in Codex and Cursor too, and they each have real strengths. I am not a one-model person.
But the moment I got access to Claude Fable 5, I could not put it down. I disappeared into it all weekend. I could feel the level of intelligence I had in my hands and how far ahead of the current options it was, and I used it to do as much work as I possibly could: running many agents at once, remote controlling it from my phone when I was away from the desk, completely hooked.
I do not know how long this window stays open. Others will catch up. But until they do, this model is a real competitive advantage sitting on the table, and I would approach that as deliberately as you can. Because it really is that good.
The verdict
Claude Fable 5 is an excellent model. It is the first one in a while that genuinely feels like more intelligence than what came before, and that gap is the whole game right now. We are at the point where access to more intelligence than the person next to you is the advantage. This is the first model that makes that real. I did engineer-level work without being an engineer. Even priced entirely at frontier rates, the workload still cleared a profit, and run with any care about routing, the return is enormous.
So here is my recommendation. If you can afford it, use it, and use it now, especially on the work where a real quality jump changes the outcome. The first month at full capacity is where the advantage lives, so move fast. Be deliberate about what you run on it until the routing catches up, because the bill is driven by volume, not by the few hard prompts that justify the model.
What an incredible model! 💙
402
Jun 9
tldr, I got to test Mythos / Fable. conclusion: it's a big model sir

2
499
Jun 9
It's a big model sir

1
399
Jun 9
We are now at the point that humans are fully the bottle neck. I don't have a solution, I don't think anyone does.
This thread was very helpful in how I think about managing the amount of work the models can do now.
Jun 9

Claude Fable 5 changed how we work on the Claude Code team day to day.
We used to verify that Claude did the work right. Now we verify that it's doing the right work.
Here’s the 3 biggest changes:
281
Jun 9
Big model achieved

I got to test Fable 5 for the last week across a range of use cases.
Quick reactions:
1) This model breaks the truism that AI is like your "overzealous, forgetful intern." It's smart, very very smart.
2) I wanted to push the model really freakin hard, so I had it rebuild two complex pieces of software (one for content, one for recruiting) that I use frequently. I've generally been anti-saaspocalypse, but given how close Fable got to one-shotting these tools, it was a very eye-opening experience.
3) Everyone who tested on my team said this was the biggest step function change in model capabilities since sonnet 3 -> 3.5, o1, and GPT 4.5 -> 5.
4) One of our engineers just kept saying "this has big model smell" over and over.
254
Jun 9
I had a chance to test out Mythos this week and as someone who codes all day. I was very impressed. It is the best coding model on the planet.
Big things that stood out:
• Finds clever, efficient ways to solve problems
• Big plans actually hold up through execution
• Genuinely strong at orchestrating workflows
• Cleaned up duplicate code on its own
Most capable model I've used to date. I made my full breakdown into an article:
1
1
8
2,075
Jun 5
I disagree.
Companies need agents that can do things and the way to do things is having access to data.
It doesn't matter what skill library you have without a way to actually utilize it.

1
1
1,495
Jun 4
This and /grill-with-docs have become absolute go to's for me. Shoutout @mattpocockuk
AI tool you should know: /grill-me
1) Go to github[.]com/mattpocock
2) Click skills
3) Scroll down and click grill-me
4) Click the download raw file button on the right
5) Head to Claude or Codex
6) Upload the .md file you downloaded
7) Start any task with /grill-me and get interrogated about any plan or decision in a way that leaves no stone unturned and your best ideas & thoughts are pulled out of you.
I love using it for my daily to-do list.
I run "/grill-me about my todo list for the day" and it forces ruthless prioritization as well as clarity of thought around how I spend my time. Some questions it asked me:
Prioritizing questions:
- What's on your list for today?
- Or should I pull it from one of your tools instead?
- How much real focus time do you actually have today (outside meetings)?
- If the day blows up at noon and you only ship one of these four, which one is it?
Clarifying questions:
- What's the actual deliverable for this task today? And what makes it "done" today?
- What's your best estimate of how long this will take? And how confident are you in that timeline?
2
498
CJ Hess retweeted
AI tool you should know: /grill-me
1) Go to github[.]com/mattpocock
2) Click skills
3) Scroll down and click grill-me
4) Click the download raw file button on the right
5) Head to Claude or Codex
6) Upload the .md file you downloaded
7) Start any task with /grill-me and get interrogated about any plan or decision in a way that leaves no stone unturned and your best ideas & thoughts are pulled out of you.
I love using it for my daily to-do list.
I run "/grill-me about my todo list for the day" and it forces ruthless prioritization as well as clarity of thought around how I spend my time. Some questions it asked me:
Prioritizing questions:
- What's on your list for today?
- Or should I pull it from one of your tools instead?
- How much real focus time do you actually have today (outside meetings)?
- If the day blows up at noon and you only ship one of these four, which one is it?
Clarifying questions:
- What's the actual deliverable for this task today? And what makes it "done" today?
- What's your best estimate of how long this will take? And how confident are you in that timeline?
14
11
204
23,909
Jun 3
I tried out dynamic workflows and didn't get much out of them at first. I spent today trying to see what I was doing wrong and learned a bunch.
Mainly, I found it so useful for adversarial agent tasks. I just used it to review a 7 PR stack. Here's how I approached it:
Claude really likes his own work, and that makes it tricky to get quality reviews, even with other standalone agents.
However, splitting the review into many focused segments with ultracode is killing it for me.
Here's my process:
1 - Define the task, often reviewing a plan or code diff, and the main things to care about. Think of this as the PR description.
2 - Define the swimlanes for the reviewers. For me this comes in a few flavors, but it's often correctness, code duplication, safety, maintainability, etc. This is where you should put the most brain power into developing your own. (I like to add a philosophy section in my skill to get the agent in the right headspace.)
3 - Turn on ultracode (I hope you already did this).
4 - Tell the model to review what it has first (the diff, the plan, the doc, etc.), then create a workflow to cut up the reviews as thinly as possible to achieve what you want, and to have them be incredibly adversarial. I often like to say "have them be super mean."
5 - Then (my favorite) include that each agent must come back with a way to verify their findings.
6 - Finally, end with the main Claude verifying all the findings once the list comes back, then prioritizing and presenting them to you.
My advice would be to copy this tweet, give it to Claude, and add your own flavor and goals for what you're actually reviewing. So far I have seen this catch bugs, produce cleaner code, and stop me from having 28 date formatters across my codebase.

5
7
97
28,750
CJ Hess retweeted

Jun 2
We just launched Sites into Codex!
Software creation was always about more than writing code. Sites in Codex fundamentally gives the power of end-to-end software creation to every user, no matter their technical fluency.
These Sites are fully deployed to a URL, private to workspaces, come with authentication, can have static files, and can store dynamic data in databases.
It is in preview for business and enterprise teams and will be rolling out to all workspaces over the next day. Give it a try by typing @ Sites into Codex and ask it to build anything!
This project took a massive amount of effort across hundreds of people at OpenAI - proud that we were able to get this out and excited to see what you all build with it!
240
264
3,842
1,022,583
CJ Hess retweeted
Most enterprises step on rakes as they try to implement AI.
And it's mostly not their fault.
The technology is moving nauseatingly fast, burning everything down and rebuilding isn't always practical or productive, and making sure you're bringing your people along for the ride is mandatory, but far from simple.
When execs asked me, "What should I do?" my response typically starts with understanding what good looks like by studying the exceptional few that are doing AI transformation the right way.
One company worth studying is @SharkNinja.
This $16.2 billion, 4,200-person consumer products behemoth has figured out how to be nimble like a startup, while having the resources & global footprint of a goliath.
A tactical way they've been able to pull this off is through Jailbreak Live, a four-day company-wide AI hack, where employees across all ranks & functions learn & build with AI to reimagine this 32-year-old company.
Why is it so damn good?
Because it's the perfect example of how leadership can truly be a partner to its people in a post-AI world.
Step 1: Leadership gives everyone the time, space, and tools to understand how AI works & then reimagine core products & processes in a psychologically safe, supported way. Part of the support comes by bringing in AI swat teams (like our team @tenex_labs) to provide individualized/group applied AI guidance to SharkNinja employees.
Goal: Show (vs. tell) that the c-suite is authentically investing in its employees to be supercharged (vs. replaced) in a post-AI world through resources, tools, time, and expert support.
Step 2: JailBreak results in hundreds of incredible AI use cases/product ideas geting bubbled up by talented people, who sit closest to the work and the customer.
Goal: Opensource the creative & ideation process, so that opportunities for the company aren't limited to what's discussed in an ELT meeting.
Step 3: Leadership bookends this process by prioritizing & resourcing into the use cases/ideas that have opportunity to be productionized and scaled across functions and the company.
Goal: Further invest resources meritocratically in the ideas that could have the most outsized impact on the company's growth. This means prioritizing and focusing the organization on key AI initiatives, investing $ (through people and technology) in executing those initiatives successfully, and then further supporting employees so that they are enabled by the output of these initiatives.
This process & SharkNinja's JailBreak Live is going to become the gold standard for how companies run & execute empathetic and effective AI transformation for years to come.
P.S. I want to give a massive shoutout to our team at @tenex_labs, who helped make this AI hackweek initiative wildly impactful. It was a full team effort and the results were profound.
11
3
41
10,580