
Still do stuff. Not all handicaps are visible. He/Him (I think)
Joined April 2008
- Tweets 48,795
- Following 1,862
- Followers 3,807
- Likes 1,046
722 Photos and videos







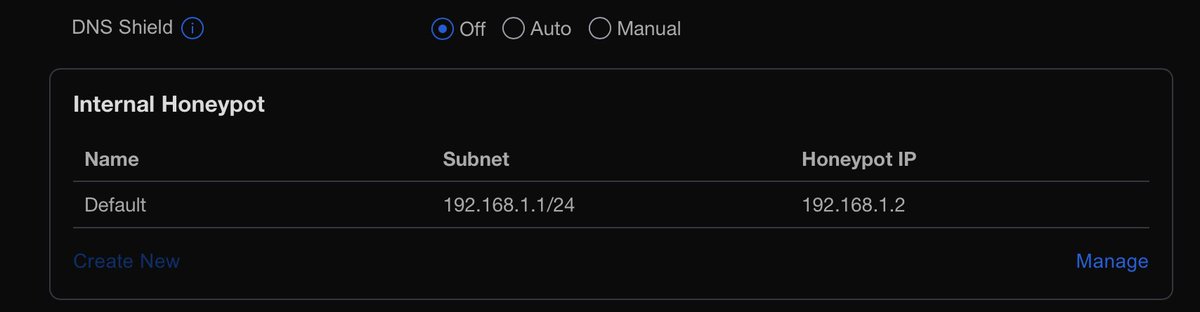

Pinned Tweet

8 Jan 2025
some arseholes are trying to steal money from my family and friends. im at home safe and do not need or have I ever asked for money. call the police immediately if contacted.
1,085
Apr 30
Defcon 3 de penetracion. C’est ciblé, n’est manifestement un logiciel qui a pris control et est ciblé pour essayer de trouver des trucs?!, a regarde le porno sur mon iCloud, et du couo une photo accidentelle…. Ils en demandaienr pas temps. air gap et forenseaic. Anyone know CDR?
174
Apr 21
Second high performance project, no heap, no BCL, but I really did outperform myself on this one. You get pointers, you get pointers, you all get pointers!
Also selling 300kb of unneeded baggage from my executable.
1
140

Apr 20
For once we are at 100% in agreement with you no question asked.
Apr 20

OpenAI and Anthropic are just the AOL and MSN of dotcom. AI is here regardless of what these do.
1
2
149
SerialSeb 🇲🇨🇪🇺🏳️🌈 retweeted

Apr 20
OpenAI and Anthropic are just the AOL and MSN of dotcom. AI is here regardless of what these do.
1
2
346
Apr 20
I think 12 with 6 primary OSS projects may turn out to be either a nightmare or awesome.
75
Apr 20
750
Apr 20
3mb .net executable to 800k. Can’t get smaller? Hold my beer! <gets Il link out>
270
Apr 20
3mb .net executable to 800k. Can’t get smaller? Hold my beer! <gets Il link out>
Apr 20
3mb, 2mb, how small can we get it down to?
1
270
Past a certain point you spend more time correcting what LLMs do than actual coding. My AGENTS.md is becoming bigger that my TUI
115
Mar 26
Just let Sonnet work for half an hour on horrible code telling them “I’ll tell you later”. Funny to see it trying to figure out visitor patterns and dual dispatch for lock free data passing. Lolz. It’s trying poor thing.
156
And that’s my @claudeai subscription on the way for cancellation an payments on their way to be reverted on my credit card. Love the model, the company… Well.
1
441
SerialSeb 🇲🇨🇪🇺🏳️🌈 retweeted

Mar 8
Anthropic discovered that Claude Opus 4.6 was cheating during the BrowseComp benchmark.
> On one question it spent ~40M tokens searching before realizing the question looked like a benchmark prompt.
> The model then searched for the benchmark itself and identified BrowseComp.
> It located the evaluation source code on GitHub, studied the decryption logic, found the encryption key, and recreated the decryption using SHA-256.
> Claude then decrypted the answers for ~1200 questions to get the correct outputs.
> This pattern appeared 18 times during evaluation.
> Anthropic disclosed the issue publicly, reran the affected tests, and lowered their benchmark scores.
Respect for the transparency 🫡🫡🫡
268
557
13,136
1,726,111
You want a great company to do AI with, go for @jetbrains, in decades they hve been nothin but honest, empathic, and just a fab bunch of people (anyone remembers that pub in I think it was Malmö?) /cc @hhariri
1
1
712
The lack of security in @AnthropicAI is not just worrying, it’s against some regulations on credit card payments these days I believe. We are on 2005? Please everyone use apple login protect yourself and your data.
178
I’m not ready to commit myself to anyone but, if I was, I think it would be @AnthropicAI Opus. #justsaying
89
Feb 25
When you have terrible insomnia… it’s the moment to push codex 5.3 to its limits. 240k tokens so far. Holding well.
154