
AI for science at @PeriodicLabs. Formerly, building AI climate models at Google. I also contribute to the scientific Python ecosystem (Xarray, NumPy, JAX).
Joined August 2009
- Tweets 3,180
- Following 769
- Followers 8,807
- Likes 4,754
77 Photos and videos





Pinned Tweet

May 2
Things I didn’t expect from becoming a dad:
- I’m now in a secret club with most of the world’s adult population
- I’ve been magically transformed into a morning person!
- Babies are genuinely lots of fun 😊
7
82
9,008
May 29
What's the best way for teams to share coding agent skills, especially across Claude/Codex?
Checking everything into a shared repos sounds great, until you accidentally trigger your colleague's bespoke workflow.
1
3
674
Stephan Hoyer retweeted

May 26
This is the first code bench that actually aligns with how it feels to use these models coding.
May 26

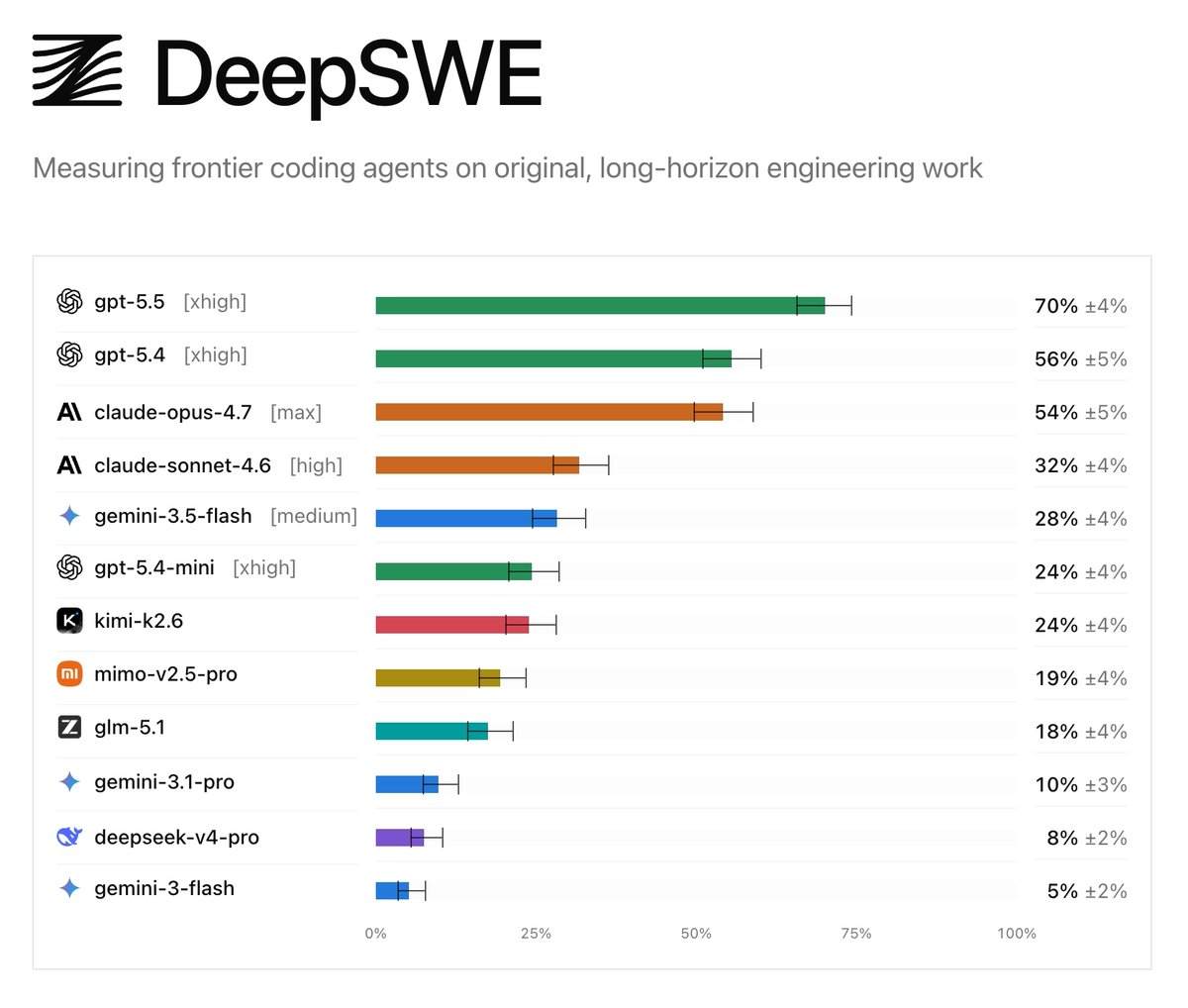
Today we’re releasing DeepSWE, a new standard for agentic coding benchmarks.
On public leaderboards, top models often look relatively close in capability. DeepSWE shows where they actually diverge, reflecting the realistic experience of developers in their day-to-day work.
120
158
3,639
303,913
May 20
Agents are so charmingly naive about effort estimation -- this is one afternoon's worth of work! Not sure if this will ever get old
3
10
1,395
May 13
Wow, this is incredibly disappointing to hear from Anthropic -- basically a death sentence for Claude in @conductor_build, which simply wraps Claude Code in a nicer GUI. Not sure how it got lumped in with autonomous agents like OpenClaw.
May 13

This means that third-party tools built on the Agent SDK like Conductor and OpenClaw work with your Claude plan, but will draw from your credit the same way your own scripts do.
41
18
530
112,646
May 13
Conductor will be OK -- GPT 5.5 is a better model than Opus 4.7, anyways, and OpenAI is much more accommodating of third-party usage of Codex.
Still, what a huge self-own from Anthropic!
3
89
5,733
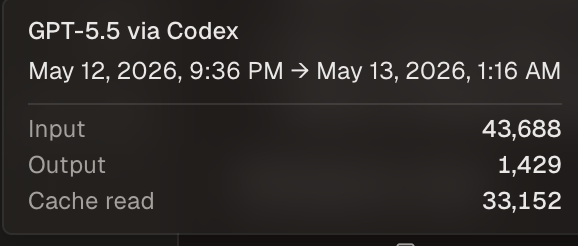
May 13
I'm happy to report that this issue seems to resolved with recent versions of Codex and GPT 5.5 -- it kept on running experiments for me for 4 hours last night!
Apr 5

Dear Codex, when I tell you to run a massive parameter sweep & model exploration overnight, you should not report “done for the night” after 30 minutes when you self-report that it’s only 2/3 done!
1
10
2,080
Stephan Hoyer retweeted

May 13
i bet on a humbling
May 13

Demis not having an in-house wet lab means he believes you can win drug discovery with
ML poetry Bio Prose
Bio has a longggg track record of humbling tech people who tried this move. Maybe Demis is built different, or maybe Mother Nature claims another one…
24
12
489
177,874

Asked Claude:
'There's a meme called the "fix everything easily switch". What policies do you think are the best candidates for being a real fix everything switch in the US? Give me your top ten, your confidence, your reasoning, and why a given policy has not been implemented.'

145
286
2,299
928,865
Stephan Hoyer retweeted

May 5
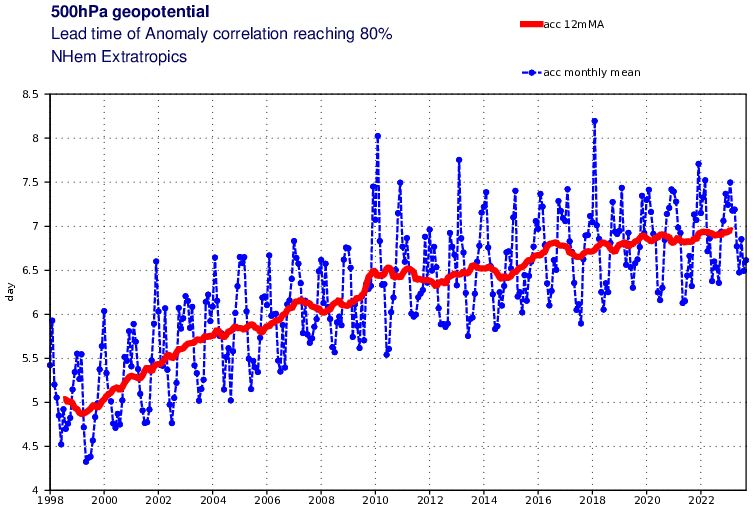
I'm excited to finally open-source the model from my 2022 paper, “Forecasting Global Weather with Graph Neural Networks”.
Highlights:
• 10-day forecast in <1 min
• Initialize forecasts from ERA5 or IFS analysis
• Scripts for eval, sensitivities, & Hurricane Sandy
18
133
1,448
126,742
May 3
GPT 5.5 in recent versions of Codex feels like a real breakthough -- incredibly smart and gets things done.
I have a new default coding model. Sorry, Claude!
22
21
631
70,738
May 3
My one minor ask for @thsottiaux -- could GPT be a little more proactive about explaining what it's doing?
Claude gives nice little updates that let me track it's progress. Codex will go through dozens of tool calls over tens of minutes and I have to trust it's still on track (which yes, it usually is!)
2
1
14
2,281
Apr 16
Feature request for coding agents: Address my latest request *now* & then decide whether to interrupt.
My common pattern:
1. Agent does something iffy
2. Agent starts something slow (e.g., running tests)
3. I have a question about (1) that may or may not require interrupting (2)
5
11
2,248
Apr 16
This presents a bit of a dilemma -- do I interrupt now, stopping the slow process that will likely need to be restarted, or do I wait for it to complete?
1
499
Apr 16
In most cases, I think an agent responding to (3) could make this choice for me. So the harness just needs to keep (2) running in the background until the agent responding to (3) decides.
1
1
418
Apr 16
I am happy to report that Claude has the opposite problem. I woke up this morning to three sessions that had each written 5k LOC and are still going strong!
Apr 5
Dear Codex, when I tell you to run a massive parameter sweep & model exploration overnight, you should not report “done for the night” after 30 minutes when you self-report that it’s only 2/3 done!
1
19
2,587
Apr 5
Dear Codex, when I tell you to run a massive parameter sweep & model exploration overnight, you should not report “done for the night” after 30 minutes when you self-report that it’s only 2/3 done!
26
4
375
38,841
Apr 3
Are there tax/financial advisers that provide better value than Claude Code for someone making less than $1m/yr?
1
4
2,204
Mar 23
The fact that I had to roll my own AI solution for manual data entry in TurboTax (thank you, Claude in Chrome) does not bode well for Intuit. I’m looking forward to @claudeai doing the whole thing next year!
1
1
9
2,457