
Joined May 2008
- Tweets 8,237
- Following 169
- Followers 402
- Likes 27,028
263 Photos and videos













Pinned Tweet

4 Aug 2024
My experience with GitHub copilot over the past few months.
medium.com/sids-tech-cafe/gi…
#github #copilot #ai #programming #SoftwareDeveloper #LLM
2
1
1,773
Jun 13
A company IPO hitting $1 trillion is crazy. What voodoo financial engineering is this. $SPCX
44
Siddharth retweeted

Jun 9
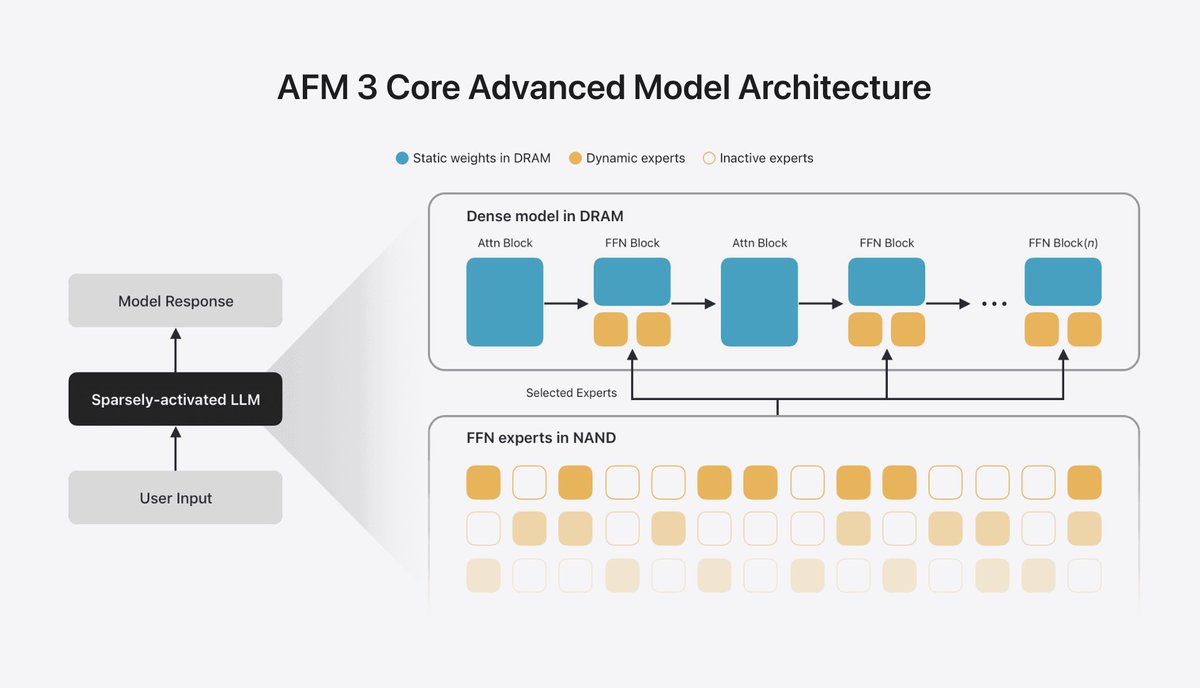
It's very cool that Apple shipped a 20B parameter on-device.
You can't put 20B parameters in RAM at any reasonable precision. To make it work they are using pretty exotic architecture by today's standards.
A small model predicts from the query (or prompt) which experts to load from Nand into RAM. The key distinction from a typical MoE is that you do this once per query and then generate all the tokens with the same experts (instead of switching the experts for every token).
77
297
3,197
225,563

Jun 9
Hey @OpenRouter - your models page is not working. It's throwing 401
openrouter.ai/models
1
1
52
Siddharth retweeted

Jun 8
312
1,144
7,338
1,839,218
Jun 7
It's good to read and understand countering view points on important subjects. I understand how everyone is hyped about AI Coding agents, and I use them and they are pretty cool! But let's read about this differing opinion, just to challenge our confirmation bias.
This is from @realGeorgeHotz Read it for fun, if nothing else.
geohot.github.io/blog/jekyll…
17
Siddharth retweeted

Over 55% of internet traffic is from bots, overtaking human traffic for the first time in history, per Cloudflare


78
382
2,754
1,441,005
Jun 7
Yes, the term "token anxiety" will soon enter the Psychology diagnostic and statistical manual, and there will be a few dozen papers on it.
Therapists are going to have a bright future.
21
Jun 7
The classic example: ask an LLM how many R’s are in “strawberry.” LLMs used to get it wrong. That’s not the model failing at counting. It’s the model not operating on letters directly, only token IDs that happen to spell out a word a human would split letter by letter.
0xkato.xyz/how-llms-actually…
18
Siddharth retweeted

Jun 6
Code volume does not represent productivity.

98
68
711
65,833
Siddharth retweeted

Jun 5
Massive output uptick due to agentic AI. Complete flat adoption.

466
974
7,321
2,417,441
Siddharth retweeted

Jun 6
What are your thoughts on @realGeorgeHotz post?
geohot.github.io/blog/jekyll…
15
2
41
9,803
Jun 6
Google Gemini is acting buggy today. It's cross referencing chats and producing hallucinations. It's giving Error 1099 consistently.
1
1
370