
Joined October 2022
- Tweets 2,573
- Following 187
- Followers 161,057
- Likes 8,703
1,012 Photos and videos











Pinned Tweet

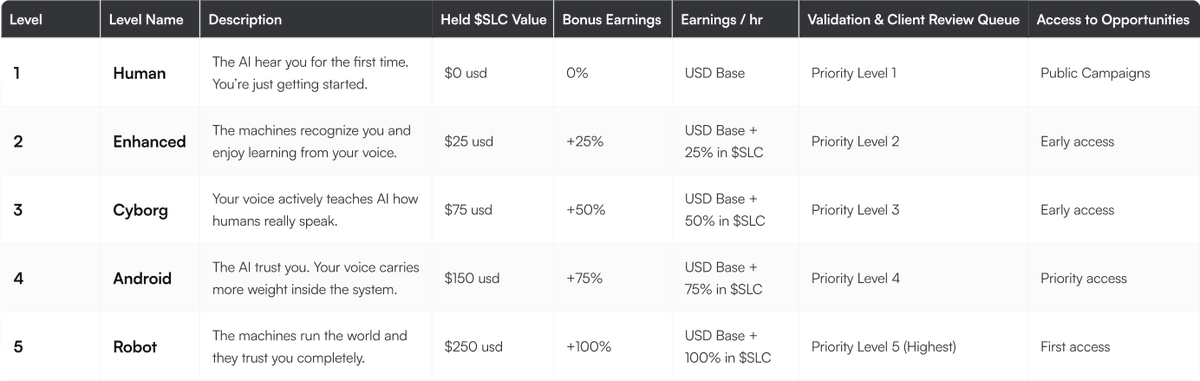
Level-up your Earnings with $SLC
In coordination with the @FoundationSLC, we are unlocking enhanced $SLC utility starting today.
SLC holders can now earn up to 100% more through Silencio Voice AI.
Live and available to all Silencio Voice AI users as of now.
What is it?
🔹Hold more $SLC → Move up levels
🔹Higher level → Higher % boost on your rewards
🔹Up to 100% boost at the highest level
Why this matters:
🔹Direct earning power tied to $SLC holdings
🔹Stronger flywheel between enterprise revenue, token burns, and contributor rewards
🔹A clear economic reason to hold $SLC on your wallet
Much more is coming to continue driving $SLC utility and placing the token at the absolute core of the Silencio ecosystem.
Every new dataset, every enterprise contract, every incentive layer will increasingly reinforce SLC as the coordination engine of the network.
We are building the world’s ears for AI and robotics.
Visit Voice AI today and start earning: ai.silencio.store/opportunit…

158
138
568
69,712
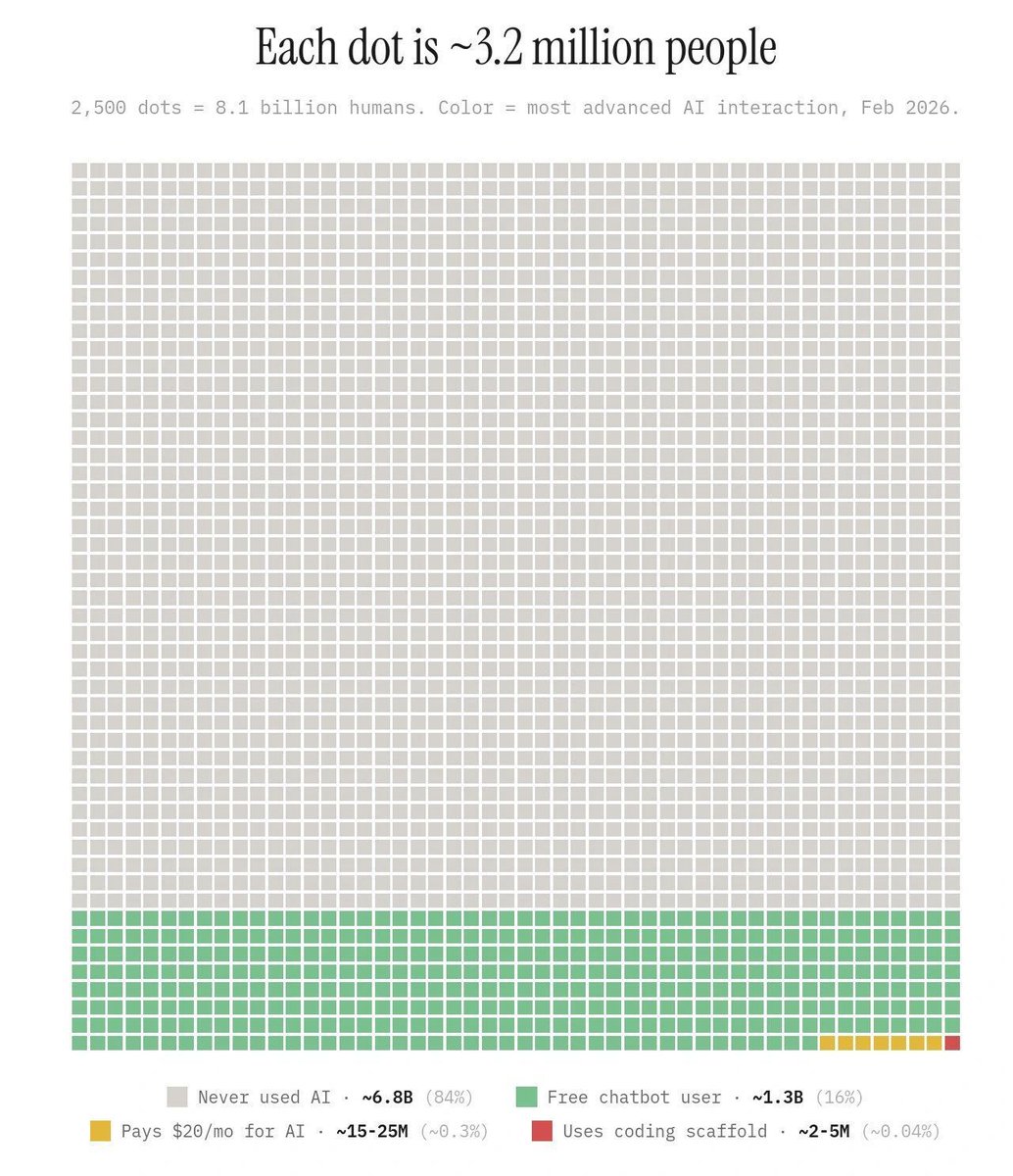
The term "low-resource language" gets used a lot in AI. Worth unpacking, because most of the languages in this category have plenty of speakers. They have low DATA resources, not low human ones. 1/3
4
4
44
2,168
A language is called "low-resource" when there are fewer than ~1,000 hours of publicly available recorded audio in it.
Swahili has 200 million speakers. By that definition, until recently, it was low-resource.
Yoruba has 40 million. Low-resource.
Tagalog, Hausa, Amharic, Igbo, Oromo, Sindhi, Tigrinya. All of them, low-resource. 2/3
1
1
14
1,060
What that means in practice: voice assistants don't work, transcription doesn't work, captioning doesn't work, voice search doesn't work. Hundreds of millions of native speakers, technologically excluded from products built for English and Mandarin.
Closing that gap is the work. Recording by recording. 3/3
2
11
893
New website. Same mission.
Building the World's Ears for AI & Robotics
Take a look at the new home of Silencio 👇
🌍 Built by the community.
📊 Powered by real-world data.
🔊 Driven by Silencio.
silencio.network
14
7
76
3,023
Why does a quiet recording matter? Not for aesthetics. For math.
A speech model learns by separating "the signal" (your voice) from "everything else" (background noise). If the noise overwhelms the signal, the model can't isolate the words. If the noise is unusual, like a TV at full volume, music, or an air-conditioning unit, the model learns to associate your language with that noise too. Then, in the real world, it fails on anyone whose room is quiet.
Same logic for articulation. If you over-pronounce, going slow, careful, projecting, the model learns "this is what this language sounds like" and then can't handle a normal conversational pace.
The single most useful rule: record the way you actually speak, in a room that sounds the way your normal rooms sound. The model needs to learn your real voice, not a performance of it.
9
3
52
1,822
Here is what you missed in Voice AI last week
From dev platforms and open models to real-world consumer pilots, anti-scam tech, and global expansion... the entire space is accelerating.
- @xai brings Grok TTS STT to Vapi, letting devs build voice agents powered by Grok’s speech models
- Sesame AI launches its iOS app with four conversational voice agents (built by the Oculus co-founders)
- @google releases Gemma 4 12B — open-source multimodal model with native audio that runs on a 16GB laptop
- @google rolls out real-time deepfake voice detection on Android to catch AI scam calls as they happen
- @McDonalds pilots ArchIQ voice AI drive-thru that handles 90% of orders with zero humans
- @ElevenLabs opens a pop-up store in NYC where every single part of the experience is run by voice agents
- Sarwam AI opens its public multilingual voice agents platform covering 11 Indian languages
- ENCO Systems debuts EnSpeak, a real-time voice-to-voice translation system for live venues and classroom
Voice is no longer an add-on it’s becoming the default way we talk to software, businesses, and each other.
What caught your eye the most? Drop it below 👀
9
8
54
2,389
Living abroad and wondering where to watch the World Cup?
A fun World Cup initiative from the Silencio team: fanbaseaway.com — a free website to find your country's fan community in any city.
Pick your team. Find your people. Watch together.
14
8
56
4,658
The problem: every World Cup, thousands of fans living abroad want to watch their team together, but they can't find each other.
As football fans at Silencio, with a team spread across different countries, we felt this every tournament. So we built a fix, just for this World Cup.
2
1
18
1,111
Inside fanbaseaway, there's a call-to-action to join Silencio.
So when you share fanbaseaway with friends abroad, you're helping them find meetups AND introducing more people to our voice AI platform.
Use it. Share it. Everyone wins.
Don't watch the World Cup alone → fanbaseaway.com
2
1
18
883
What actually happens to a Silencio recording after you press "save"?
Most contributors never see the steps that come after. Worth knowing. Your part of it is the most important one. 1/4
7
4
53
2,232
Step 2: a native speaker transcribes a sample of it. We're building this layer right now across the languages we cover.
A model learns "this sound = this word" by hearing thousands of paired examples. That pairing is the bottleneck of multilingual voice AI. 3/4
1
16
1,040
Step 3: that paired audio text is fed into a training run. Many millions of pairs, over weeks of compute. The model that comes out the other end is what powers a voice assistant, a captioning tool, a transcription product in your language.
Your recording, multiplied by a million others, is what makes the model exist. 4/4
11
701
Silencio Voice AI is at Lisbon AI Summit 2026 tomorrow, Lisbon Congress Centre.
We're meeting AI builders across the day. Voice AI training data, multilingual coverage, where production voice products still miss whole languages.
If you're there, come find us. Send us a message to schedule.
2
5
72
2,933
The Silencio voice network, right now:
2,000,000 contributors
180 countries
150 distinct languages
5,000 hours of new audio added every day
What this scale buys, technically: enough variation in voices, accents, devices, and environments that a model trained on it generalises to the real world, not to a studio. Models trained on 50 voices fail outside the lab. Models trained on a million voices don't.
Every recording adds one more degree of "the model has heard someone like this before."
23
11
85
5,370
How many languages do you speak?
Comment below 👇
31
3
45
2,051
Long before voice AI existed, linguists spent years in the field with tape recorders, capturing how a language is actually spoken before the last fluent speakers passed away. Some of the most important archives of human language (Maori, Welsh, Sami, Cherokee, hundreds of others) exist because someone did exactly that, often at the last possible moment.
Silencio, in 2026, is operating something close to that on global scale. Every recording in a low-resource language is also a permanent, dated, metadata-labelled record of how that language sounded at this point in time. The commercial use trains a model. The documentation use is a side-effect, and a side-effect that will outlast any single product.
If you record in a language that is rarely captured at scale, the second outcome is not theoretical. It's already happening.
#LanguagePreservation
13
10
76
2,799
Join us tomorrow at 16:00 CET as we give Silencians a community update and answer your questions.
Looking forward to seeing you there!
x.com/i/spaces/1dGYllLpwrLKX
26
11
62
3,726