
modeling the world. Personalising with and without priors, creator of medium sized filter bubbles. schibsted.no, finn.no, Arcticdatalab.no and uni Oslo.
Joined November 2008
- Tweets 2,783
- Following 691
- Followers 678
- Likes 1,945
165 Photos and videos








Simen Eide retweeted

Feb 25
It is hard to communicate how much programming has changed due to AI in the last 2 months: not gradually and over time in the "progress as usual" way, but specifically this last December. There are a number of asterisks but imo coding agents basically didn’t work before December and basically work since - the models have significantly higher quality, long-term coherence and tenacity and they can power through large and long tasks, well past enough that it is extremely disruptive to the default programming workflow.
Just to give an example, over the weekend I was building a local video analysis dashboard for the cameras of my home so I wrote: “Here is the local IP and username/password of my DGX Spark. Log in, set up ssh keys, set up vLLM, download and bench Qwen3-VL, set up a server endpoint to inference videos, a basic web ui dashboard, test everything, set it up with systemd, record memory notes for yourself and write up a markdown report for me”. The agent went off for ~30 minutes, ran into multiple issues, researched solutions online, resolved them one by one, wrote the code, tested it, debugged it, set up the services, and came back with the report and it was just done. I didn’t touch anything. All of this could easily have been a weekend project just 3 months ago but today it’s something you kick off and forget about for 30 minutes.
As a result, programming is becoming unrecognizable. You’re not typing computer code into an editor like the way things were since computers were invented, that era is over. You're spinning up AI agents, giving them tasks *in English* and managing and reviewing their work in parallel. The biggest prize is in figuring out how you can keep ascending the layers of abstraction to set up long-running orchestrator Claws with all of the right tools, memory and instructions that productively manage multiple parallel Code instances for you. The leverage achievable via top tier "agentic engineering" feels very high right now.
It’s not perfect, it needs high-level direction, judgement, taste, oversight, iteration and hints and ideas. It works a lot better in some scenarios than others (e.g. especially for tasks that are well-specified and where you can verify/test functionality). The key is to build intuition to decompose the task just right to hand off the parts that work and help out around the edges. But imo, this is nowhere near "business as usual" time in software.
1,600
4,727
37,159
5,142,404

Feb 23
I must say, using the backlog.md feature from @mrlesk is really a gamechanger when developing. While one idea is implemented i can plan the next one, when something breaks the agent can look at the implementation docs and see what we did.
Feb 16

its crazy what agentic coding makes with people.. Ive even started to value kanban boards! @opencode @mrlesk
82
Feb 5
Yes, there is so many reasons claudebot is an AI risk. So the surprising thing is that it seems like the biggest security issue with claudbot is people putting their computers on the internet without passwords...
71
Jan 26
Nice summary of coding with llms in jan 2026
Jan 26

A few random notes from claude coding quite a bit last few weeks.
Coding workflow. Given the latest lift in LLM coding capability, like many others I rapidly went from about 80% manual autocomplete coding and 20% agents in November to 80% agent coding and 20% edits touchups in December. i.e. I really am mostly programming in English now, a bit sheepishly telling the LLM what code to write... in words. It hurts the ego a bit but the power to operate over software in large "code actions" is just too net useful, especially once you adapt to it, configure it, learn to use it, and wrap your head around what it can and cannot do. This is easily the biggest change to my basic coding workflow in ~2 decades of programming and it happened over the course of a few weeks. I'd expect something similar to be happening to well into double digit percent of engineers out there, while the awareness of it in the general population feels well into low single digit percent.
IDEs/agent swarms/fallability. Both the "no need for IDE anymore" hype and the "agent swarm" hype is imo too much for right now. The models definitely still make mistakes and if you have any code you actually care about I would watch them like a hawk, in a nice large IDE on the side. The mistakes have changed a lot - they are not simple syntax errors anymore, they are subtle conceptual errors that a slightly sloppy, hasty junior dev might do. The most common category is that the models make wrong assumptions on your behalf and just run along with them without checking. They also don't manage their confusion, they don't seek clarifications, they don't surface inconsistencies, they don't present tradeoffs, they don't push back when they should, and they are still a little too sycophantic. Things get better in plan mode, but there is some need for a lightweight inline plan mode. They also really like to overcomplicate code and APIs, they bloat abstractions, they don't clean up dead code after themselves, etc. They will implement an inefficient, bloated, brittle construction over 1000 lines of code and it's up to you to be like "umm couldn't you just do this instead?" and they will be like "of course!" and immediately cut it down to 100 lines. They still sometimes change/remove comments and code they don't like or don't sufficiently understand as side effects, even if it is orthogonal to the task at hand. All of this happens despite a few simple attempts to fix it via instructions in CLAUDE . md. Despite all these issues, it is still a net huge improvement and it's very difficult to imagine going back to manual coding. TLDR everyone has their developing flow, my current is a small few CC sessions on the left in ghostty windows/tabs and an IDE on the right for viewing the code manual edits.
Tenacity. It's so interesting to watch an agent relentlessly work at something. They never get tired, they never get demoralized, they just keep going and trying things where a person would have given up long ago to fight another day. It's a "feel the AGI" moment to watch it struggle with something for a long time just to come out victorious 30 minutes later. You realize that stamina is a core bottleneck to work and that with LLMs in hand it has been dramatically increased.
Speedups. It's not clear how to measure the "speedup" of LLM assistance. Certainly I feel net way faster at what I was going to do, but the main effect is that I do a lot more than I was going to do because 1) I can code up all kinds of things that just wouldn't have been worth coding before and 2) I can approach code that I couldn't work on before because of knowledge/skill issue. So certainly it's speedup, but it's possibly a lot more an expansion.
Leverage. LLMs are exceptionally good at looping until they meet specific goals and this is where most of the "feel the AGI" magic is to be found. Don't tell it what to do, give it success criteria and watch it go. Get it to write tests first and then pass them. Put it in the loop with a browser MCP. Write the naive algorithm that is very likely correct first, then ask it to optimize it while preserving correctness. Change your approach from imperative to declarative to get the agents looping longer and gain leverage.
Fun. I didn't anticipate that with agents programming feels *more* fun because a lot of the fill in the blanks drudgery is removed and what remains is the creative part. I also feel less blocked/stuck (which is not fun) and I experience a lot more courage because there's almost always a way to work hand in hand with it to make some positive progress. I have seen the opposite sentiment from other people too; LLM coding will split up engineers based on those who primarily liked coding and those who primarily liked building.
Atrophy. I've already noticed that I am slowly starting to atrophy my ability to write code manually. Generation (writing code) and discrimination (reading code) are different capabilities in the brain. Largely due to all the little mostly syntactic details involved in programming, you can review code just fine even if you struggle to write it.
Slopacolypse. I am bracing for 2026 as the year of the slopacolypse across all of github, substack, arxiv, X/instagram, and generally all digital media. We're also going to see a lot more AI hype productivity theater (is that even possible?), on the side of actual, real improvements.
Questions. A few of the questions on my mind:
- What happens to the "10X engineer" - the ratio of productivity between the mean and the max engineer? It's quite possible that this grows *a lot*.
- Armed with LLMs, do generalists increasingly outperform specialists? LLMs are a lot better at fill in the blanks (the micro) than grand strategy (the macro).
- What does LLM coding feel like in the future? Is it like playing StarCraft? Playing Factorio? Playing music?
- How much of society is bottlenecked by digital knowledge work?
TLDR Where does this leave us? LLM agent capabilities (Claude & Codex especially) have crossed some kind of threshold of coherence around December 2025 and caused a phase shift in software engineering and closely related. The intelligence part suddenly feels quite a bit ahead of all the rest of it - integrations (tools, knowledge), the necessity for new organizational workflows, processes, diffusion more generally. 2026 is going to be a high energy year as the industry metabolizes the new capability.
2
98
Jan 23
AI videos are runining doomscrolling, and that is in fact quite nice
1
42
Simen Eide retweeted

Jan 22
we just released RF-DETR segmentation
SOTA real-time segmentation Apache 2.0 license
six model sizes with performance spanning from 40.3 mAP at 3.4 ms/image (Nano) to 49.9 mAP at 21.8 ms/image (2XLarge)
link: github.com/roboflow/rf-detr
29
89
768
138,751
Simen Eide retweeted

20 Nov 2025
Collecting a high quality dataset with 4M unique phrases and 52M corresponding object masks helped SAM 3 achieve 2x the performance of baseline models. Kate, a researcher on SAM 3, explains how the data engine made this leap possible.
🔗 Read the SAM 3 research paper: go.meta.me/6411f7
12
42
382
38,512
30 Sep 2025
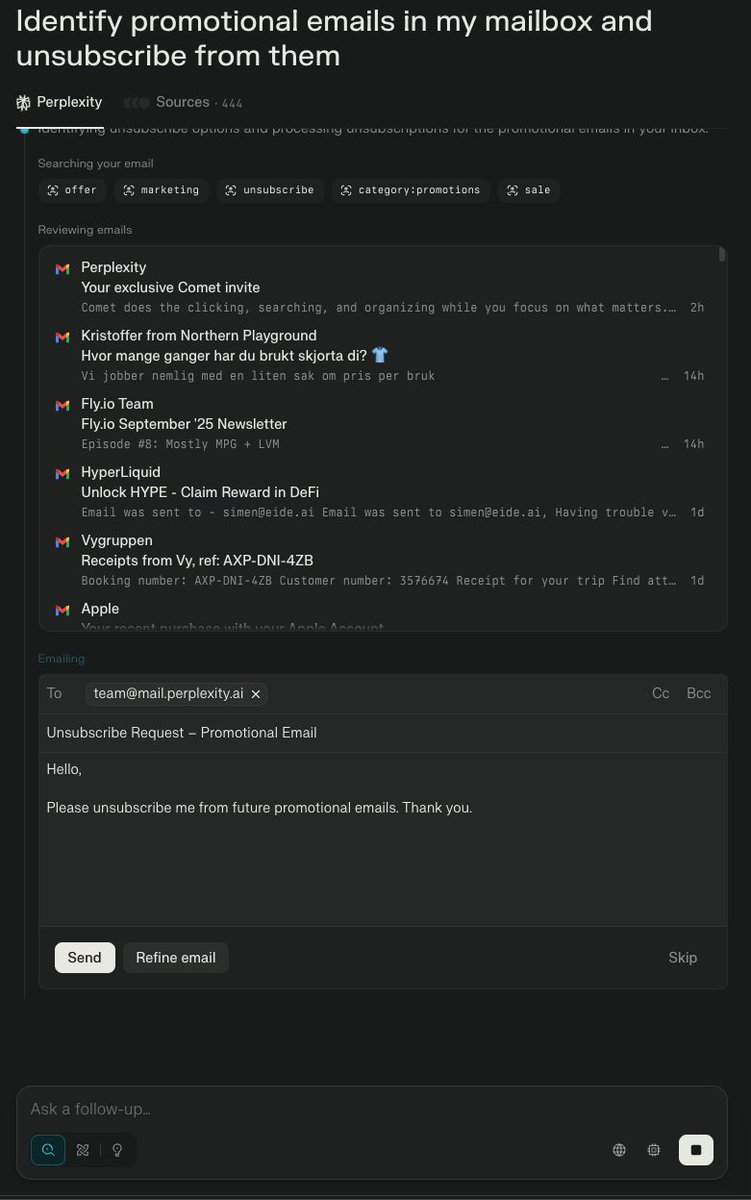
Testing @perplexity_ai 's new Comet browser, and and clicking the first "agentic" suggestion. You cant make this up.
256
8 Nov 2024
Need to evaluate your LLM on text generation? Schibsted text tasks to the rescue! eide.ai/posts/2024-11-06-sch…
1
3
280
5 Nov 2024
What has happened, when adding evaluation loss to your research grade training scripts, has become old school?!
91
13 Oct 2024
When we get AGI we dont have to listen to industry leaders speculate all the things AGI will solve. What a wonderful world that will be!
6
96
Simen Eide retweeted

7 Jul 2024
There was a super impressive AI competition that happened last week that many people missed in the noise of AI world. I happen to know several participants so let me tell you a bit of this story as a Sunday morning coffee time.
You probably know the Millennium Prize Problems where the Clay Institute pledged a US$1 million prize for the first correct solution to each of 7 deep math problems. To this date only one of these, the Poincaré conjecture, has been solved by Grigori Perelman who famously declined the award (go check Grigori out if you haven't the guy has a totally based life).
So this new competition, the Artificial Intelligence Math Olympiad (AIMO) also came with a US$1M prize but was only open to AI model (so the human get the price for the work of the AI...). It tackle also very challenging but still simpler problems, namely problems at the International Math Olympiad gold level. Not yet the frontier of math knowledge but definitely above what most people, me included, can solve today.
The organizing committee of the AIMO is kind-of-a who-is-who of highly respected mathematicians in the world, for instance Terence Tao widely famous math prodigy widely regarded as one of the greatest living mathematicians.
Enter our team, Jia Li, Yann Fleuret, and Hélène Evain. After a successful exit in a previous startup (that I happen to have know well when I was an IP lawyer in a previous life but that's for another story) they decided to co-found Numina as a non-profit to do open AI4Math.
Numina wanted to act as a counterpoint to AI math efforts like DeepMind's but in a much more open way with the goal to advance the use of AI in mathematics and make progress on hard, open problems. Along the way, they managed to recruit the help of some very impressive names in the AI math world like Guillaume Lample, co-founder of Mistral or Stanislas Polu, formerly pushing math models at OpenAI.
As Jia was participating in the code-model BigCode collaboration with some Hugging Face folks, came the idea to collaborate and explore how well code models could be used for formal mathematics.
For context, olympiad math problems are extremely hard and the core of the issue is in the battle plan you draft to tackle each problem. A first focus of Numina was thus on creating high quality instruction Chain-of-Thought (CoT) data for competition-level mathematics. This CoT data has already been used to train models like DeepSeek Math, but is very rarely released so this dataset became an unvaluated ressource to tackle the challenges.
BigCode's lead Leandro put Jia in touch with the team that trained the Zephyr models at Hugging Face, namely, Lewis, Ed, Costa and Kashif with additional help from Roman and Ben and the goal became to have a go at training some strong models on the math and code data to tackle the first progress prize of AIMO.
And the trainings started:
Jia being an olympiad coach, was intimately familiar with the difficulty level of these competitions and able to curate an very strong internal validation set to enable model selection (Kaggle submissions are blind). While iterating on dataset construction, Lewis and Ed from Hugging Face focused on training the models and building the inference pipeline for the Kaggle submissions.
As often in competition it was an intense journey with Eureka and Aha moments pushing everyone further.
Lewis told me about a couple of them which totally blow my mind. A tech report is coming so this is just some "along the way" nuggets that will be soon gathered in a much more comprehensive recipe and report.
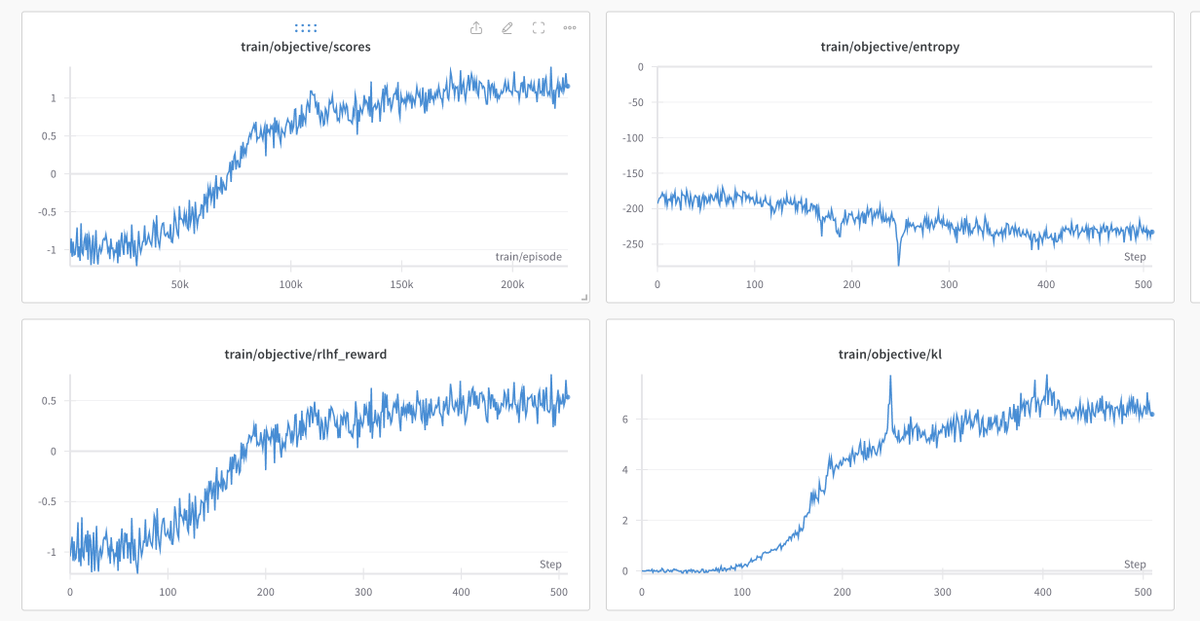
Learning to code: The submission of the team relied on self-consistency decoding (aka majority voting) to generate N candidates per problem and pick the most common solution. But initial models trained on the Numina data only scored around 13/50... they needed a better approach. They then saw the MuMath-Code paper (arxiv.org/abs/2405.07551) which showed you can combine CoT data with code data to get strong models. Jia was able to generate great code execution data from GPT-4 to enable the training of the initial models and get to impressive boost in performance.
Taming the variance: Another Ahah moment came at some point when a Kaggle member shared a notebook showing how DeepSeek models worked super well with code execution (the model breaks down the problem into steps and each step is run in Python to reason about the next one).
However, when the team tried this notebook they found this method had huge variance (the scores on Kaggle varied from 16/50 to 23/50).
When meeting in Paris for a hackathon to improve this issue (like the HF team often does) Ed had the idea to frame the majority voting as a "tree of thoughts" where you'd progressively grow and prune a tree of candidate solutions (arxiv.org/abs/2305.10601).
This had an impressive impact on the variance and enabled them to be much more confident in their submissions (which showed in how the model ended up performing extremely well on the test set versus the validation set)
Overcoming compute constraints: the Kaggle submissions had to run on 2xT4s in under 9h which is really hard because FA2 doesn't work and you can't use bfloat16 either. The team explored quantization methods like AWQ and GPTQ, finding that 8-bit quantization of a 7B model with GPTQ was best
Looking at the data: a large part of the focus was also on checking the GPT-4 datasets for quality (and fixing them) as they quickly discovered that GPT-4 was prone to hallucinations and failing to correctly interpret the code output. Fixing data issues in the final week led to a significant boost in performance.
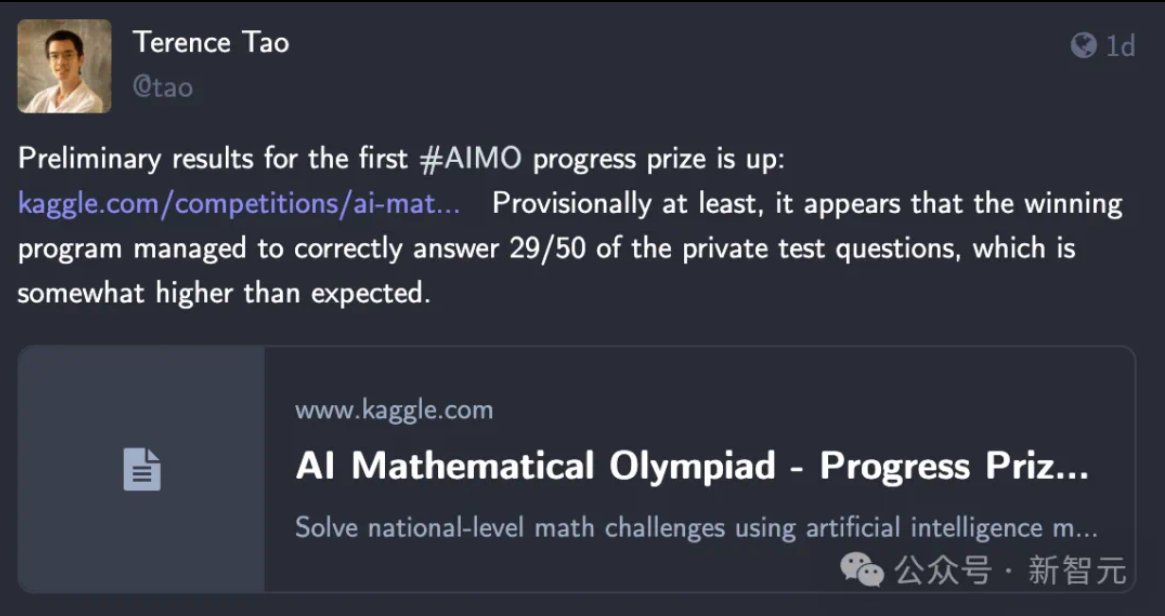
Final push: The result were really amazing and the model climbed to the 1 place. And even more, while tying up for first place on the public, validation leaderboard (28 solved challenges versus 27 for the second place), it really shined when tested on the private, test leaderboard where it took a wide margin solving 29 challenges versus 22 for the second team.
As Terence Tao himself set it up, this is "higher than expected"
Maybe what's even more impressive about this competition, beside the level of math these models are already capable of is how ressource contraint the participants were actually, having to run inference in a short amont of time on T4 which only let us imagine how powerful these models will become in the coming months.
Time seem to be ripe for GenAI to have some impact in science and it's probably one of the most exciting thing AI will bring us in the coming 1-2 year. Accelerating human development and tackling all the real world problems science is able to tackle.

62
499
2,864
651,269
13 Jun 2024
20 minutes into Twitter for a long while I've found two papers and a python library I want to learn more about. I guess this place isn't dead like linkedin
2
101
Simen Eide retweeted

10 Jun 2024
BERTs are not dead!🧟 But just misunderstood and overshadowed by their GPT siblings. In this paper, we travel back into 2020 and speculate on an alternative history where DeBERTa is the first model to show in-context learning abilities.
Paper: arxiv.org/abs/2406.04823
1/6

17
99
582
77,985
Simen Eide retweeted

10 Mar 2024
"The world has gotten so horrible"
No, no it has not
We still have a long way to go, but we've come a heck of a long way already
With innovation, dedication, and prioritization,
We can much further, and get there even faster

1
149
15 Feb 2024
Big kudos to the ai team in Nasjonalbiblioteket launching their Norwegian Whisper models today!
Of course, we are live transcribing the meeting for our non-attending colleagues using the exact same model! 😇
3
184


