
Research @Meta @RealityLabs | Prev: Ph.D. from @CogSciUCSD
Joined July 2010
- Tweets 738
- Following 1,653
- Followers 488
- Likes 11,175
40 Photos and videos








Pinned Tweet

3 Nov 2025
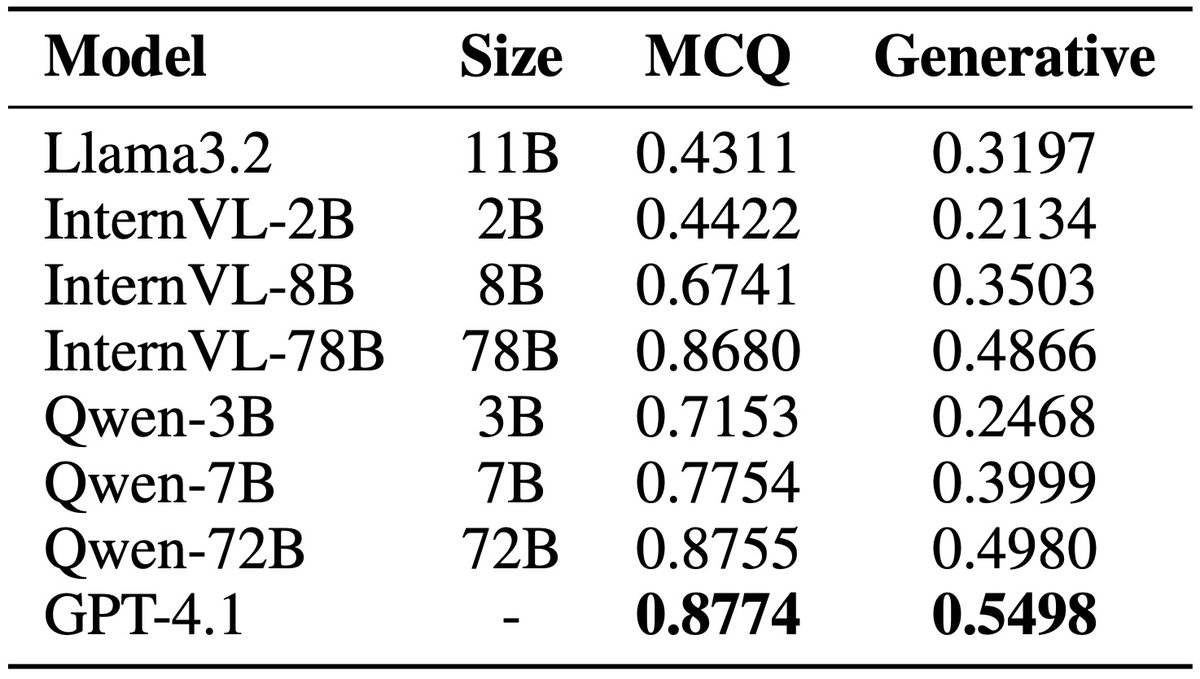
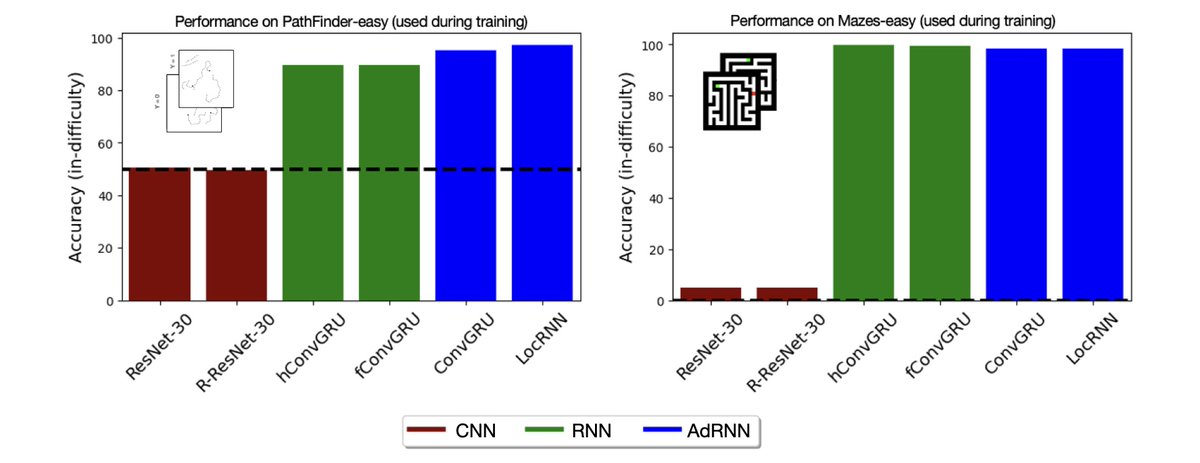
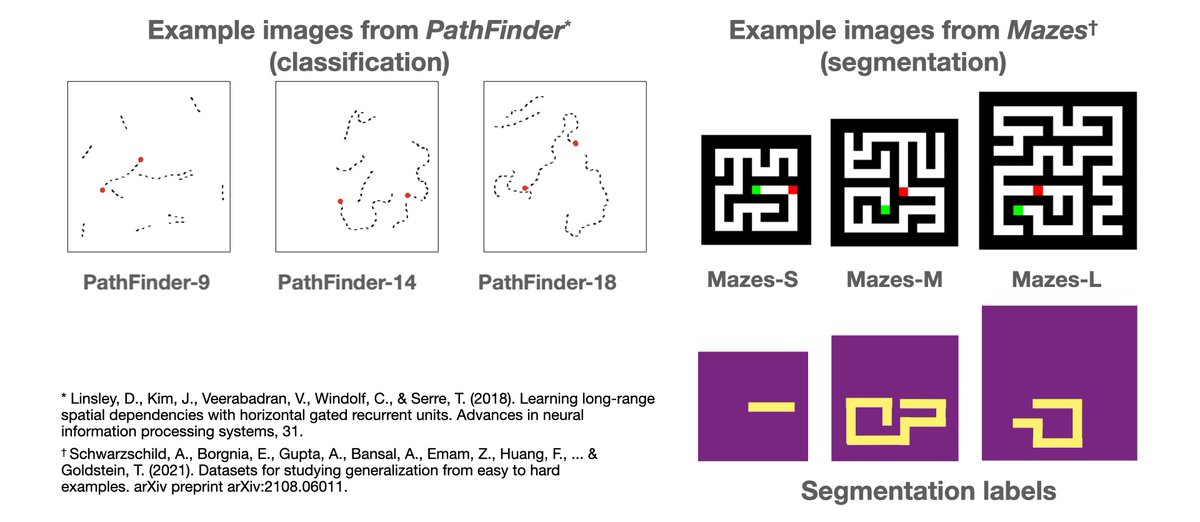
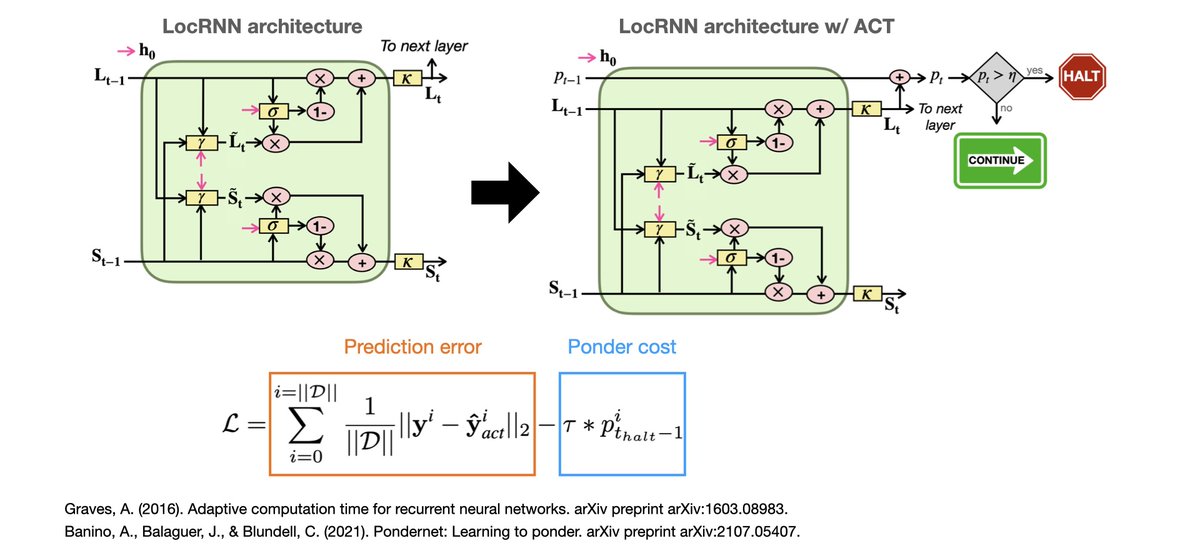
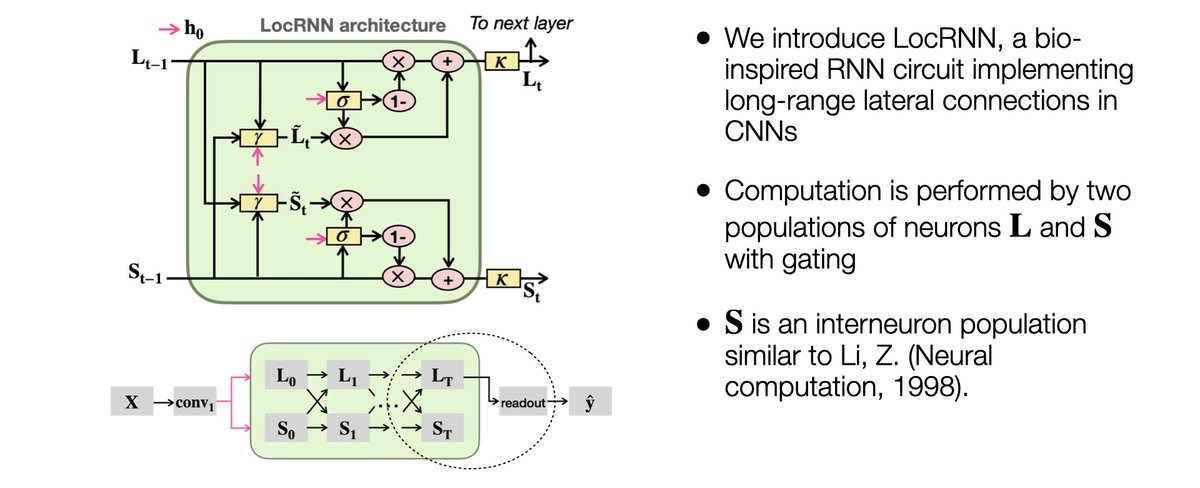
🚨 Appearing as a #NeurIPS2025 D&B spotlight(~3%)
Could VLMs guess your next prompt for a wearable AI agent?
We present WAGIBench, the 1st large-scale Goal Inference Benchmark for Wearable Agents w/ audiovisual, digital & longitudinal context!
Paper: arxiv.org/abs/2510.22443
1/
1
5
14
885


One of my favorite findings: Positional embeddings are just training wheels. They help convergence but hurt long-context generalization.
We found that if you simply delete them after pretraining and recalibrate for < 1% of the original budget, you unlock massive context windows.
Jan 12

Introducing DroPE: Extending the Context of Pretrained LLMs by Dropping Their Positional Embeddings
pub.sakana.ai/DroPE/
We are releasing a new method called DroPE to extend the context length of pretrained LLMs without the massive compute costs usually associated with long-context fine-tuning.
The core insight of this work challenges a fundamental assumption in Transformer architecture. We discovered that explicit positional embeddings like RoPE are critical for training convergence but eventually become the primary bottleneck preventing models from generalizing to longer sequences.
Our solution is radically simple: We treat positional embeddings as a temporary training scaffold rather than a permanent architectural necessity.
Real-world workflows like reviewing massive code diffs or analyzing legal contracts require context windows that break standard pretrained models. While models without positional embeddings (NoPE) generalize better to these unseen lengths, they are notoriously unstable to train from scratch.
Here, we achieve the best of both worlds by using embeddings to ensure stability during pretraining and then dropping them to unlock length extrapolation during inference. Our approach unlocks seamless zero-shot context extension without any expensive long-context training.
We demonstrated this on a range of off-the-shelf open-source LLMs. In our tests, recalibrating any model with DroPE requires less than 1% of the original pretraining budget, yet it significantly outperforms established methods on challenging benchmarks like LongBench and RULER.
We have released the code and the full paper to encourage the community to rethink the role of positional encodings in modern LLMs.
Paper: arxiv.org/abs/2512.12167
Code: github.com/SakanaAI/DroPE
49
236
2,499
346,814
Vijay Veerabadran retweeted

6 Dec 2025
Hi👋 I am at #neurips2025 to present our position paper on world models.🌍👇
🗓️ Dec 7 📍Upper Level Ballroom 20D/LAW workshop.
I’m excited to chat about VL Reasoning & video generation and am actively looking for Postdoc/ Full-time roles. DM me if you would like to chat.
6 Dec 2025

How can we build more robust and safe world models? 🤔
Our position paper, World Models Must Live in Parallel Worlds 🌍, tries to answer this question.
Find us at NeurIPS 2025:
🗓️ Dec 7
📍 Upper Level Ballroom 20D
#neurips2025 w/ @Sahithya_Ravi @VeredShwartz, Leonid Sigal
1/5
5
12
2,555
Vijay Veerabadran retweeted

18 Nov 2025
We just released results for our newest VLA from Physical Intelligence: π*0.6. This one is trained with RL, and it makes it quite a bit better: often doubles throughput, enables real-world tasks like folding real laundry and making espresso drinks at the office.
46
193
1,658
297,840
Vijay Veerabadran retweeted

9 Nov 2025
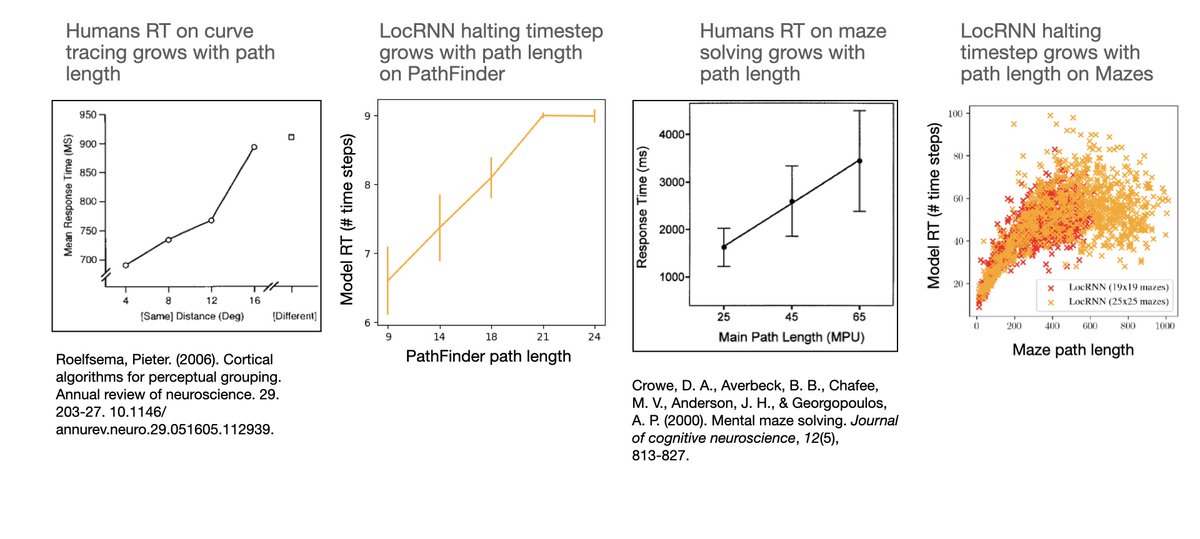
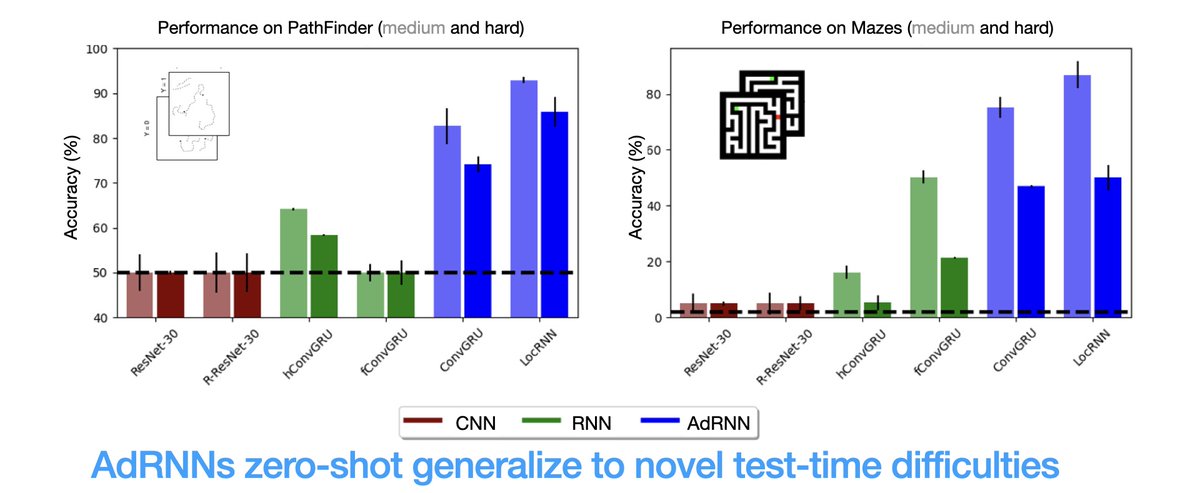
New pre-print from our lab, by Lakshmi Govindarajan @lakshming92 with help from Sagarika Alavilli, introducing a new type of model for studying sensory uncertainty. biorxiv.org/content/10.1101/…
Here is a summary. (1/n)
1
8
26
3,777
Vijay Veerabadran retweeted

3 Nov 2025
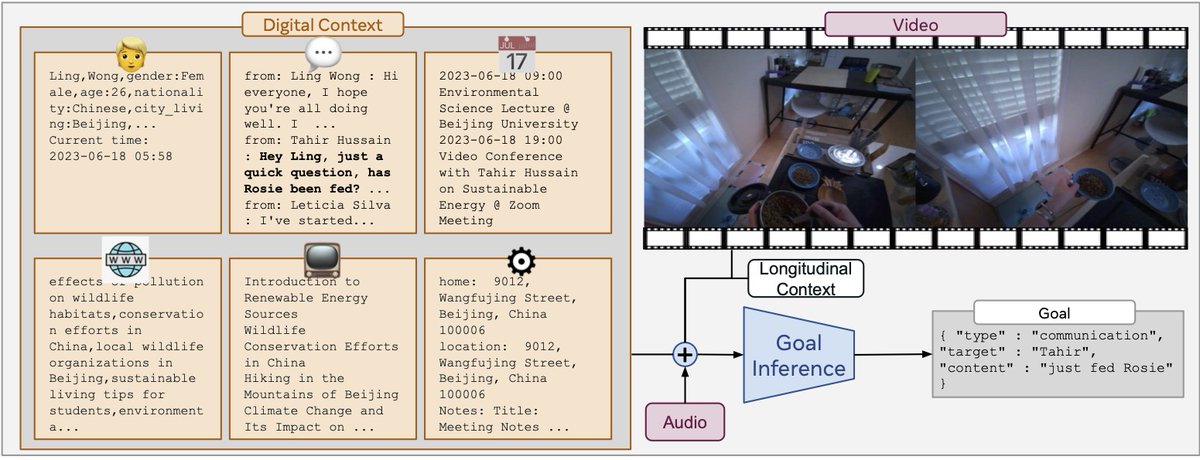
New benchmark evaluating multimodal VLMs for proactive smart glasses from our group!
3 Nov 2025

🚨 Appearing as a #NeurIPS2025 D&B spotlight(~3%)
Could VLMs guess your next prompt for a wearable AI agent?
We present WAGIBench, the 1st large-scale Goal Inference Benchmark for Wearable Agents w/ audiovisual, digital & longitudinal context!
Paper: arxiv.org/abs/2510.22443
1/
1
2
149
3 Nov 2025
🚨 Appearing as a #NeurIPS2025 D&B spotlight(~3%)
Could VLMs guess your next prompt for a wearable AI agent?
We present WAGIBench, the 1st large-scale Goal Inference Benchmark for Wearable Agents w/ audiovisual, digital & longitudinal context!
Paper: arxiv.org/abs/2510.22443
1/
1
5
14
885
3 Nov 2025
🧠 vs 🤖We benchmarked various evaluation functions by comparing them to human raters. We find that the LLM Judge parameterized with scenario script best aligns with human raters (76.8% agreement), performing as well as any individual from a separate group.
8/
1
73
3 Nov 2025
🚀 Ready to test your model? Explore the benchmarking code and link to download our dataset here:
github.com/facebookresearch/…
Thanks to our awesome team from @RealityLabs and @metaai that made this work possible!
#NeurIPS2025 #WearableAI #VLMs #MultimodalAI #AIResearch
9/
1
88
Vijay Veerabadran retweeted

18 Oct 2025
In 1992 Peter Ratcliffe received this rejection letter from Nature.
His findings were not "a sufficient advance in our understanding".
27 years later he won the Nobel Prize for the same discovery.
Don't lose faith in the things you believe in.

173
1,876
7,721
728,537
Vijay Veerabadran retweeted

26 Sep 2025
🌟To appear in the MechInterp Workshop @ #NeurIPS2025 🌟
Paper: arxiv.org/abs/2509.04466
How do language models (LMs) form representation of new tasks, during in-context learning? We study different types of task representations, and find that they evolve in distinct ways.
🧵1/7

1
14
110
20,089
Vijay Veerabadran retweeted

26 Sep 2025
Interested in research in my lab? intake.gureckislab.org/inter…
1
4
19
2,996
Vijay Veerabadran retweeted
7 Apr 2025
Unexpected events grab human attention & push AI models beyond their training data. 🤔
How well do VLMs reason about these critical, novel scenarios?
🦢 Introducing Black Swan #CVPR2025!
Co-lead: @adityachinchure
w/ @AlbertBoyangLi @VeredShwartz
🔗 blackswan.cs.ubc.ca/
2
8
36
18,225
14 Nov 2024
13 Nov 2024

This is a first... Reviewer #2 asking us to compare against the very paper we are submitting and that he is (supposed to be) reviewing!? This is all just a farce... #ICLR2025 🙃
129