
Research Scientist in Meta TBD Lab, working on LLM post-training, RL and test-time compute.
Joined August 2016
- Tweets 19
- Following 45
- Followers 382
- Likes 15
6 Photos and videos



Apr 12
This beast mode is gradually rolling out. Everyone will have a chance to try!

Not usually a Meta AI user, but wanted to give them a shot after the latest model release (it's free anyway).
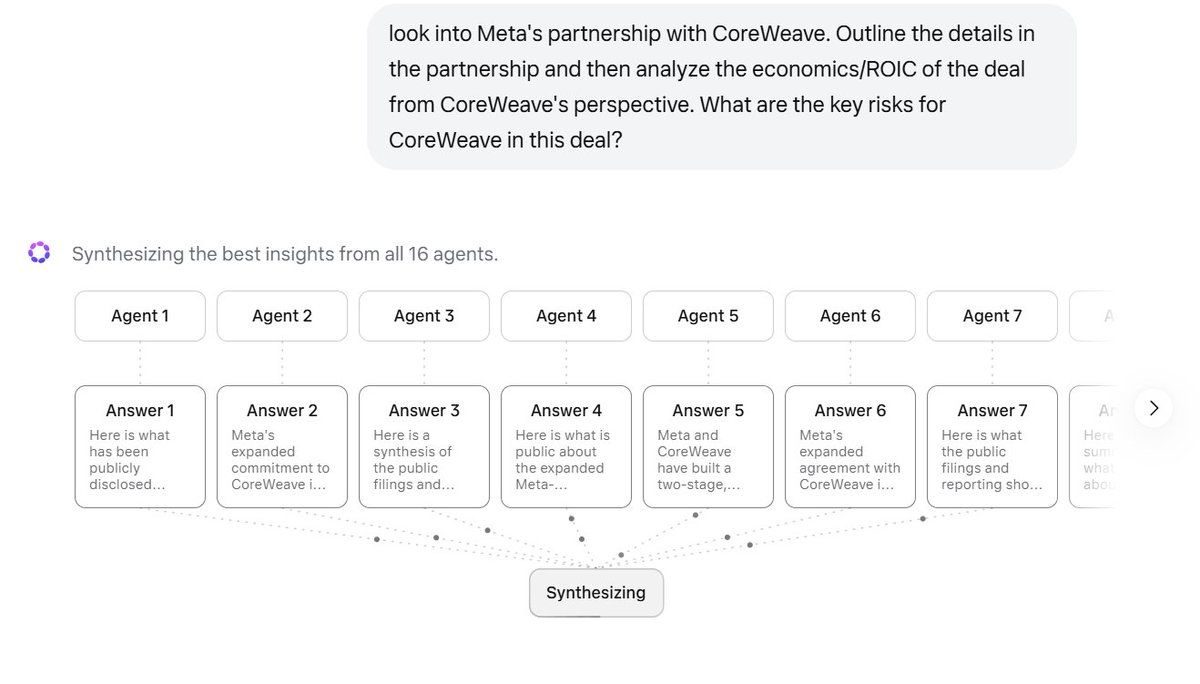
So I installed the app on my desktop, and noticed "contemplating" mode (didn't see that on the mobile app btw). When I asked a question, 16 agents simultaneously started working on the question which looks pretty cool!

2
96
Sinong Wang retweeted

Apr 12
check out Contemplating mode for your most complex reasoning queries!
Not usually a Meta AI user, but wanted to give them a shot after the latest model release (it's free anyway).
So I installed the app on my desktop, and noticed "contemplating" mode (didn't see that on the mobile app btw). When I asked a question, 16 agents simultaneously started working on the question which looks pretty cool!
41
16
299
38,724
Sinong Wang retweeted

Apr 8
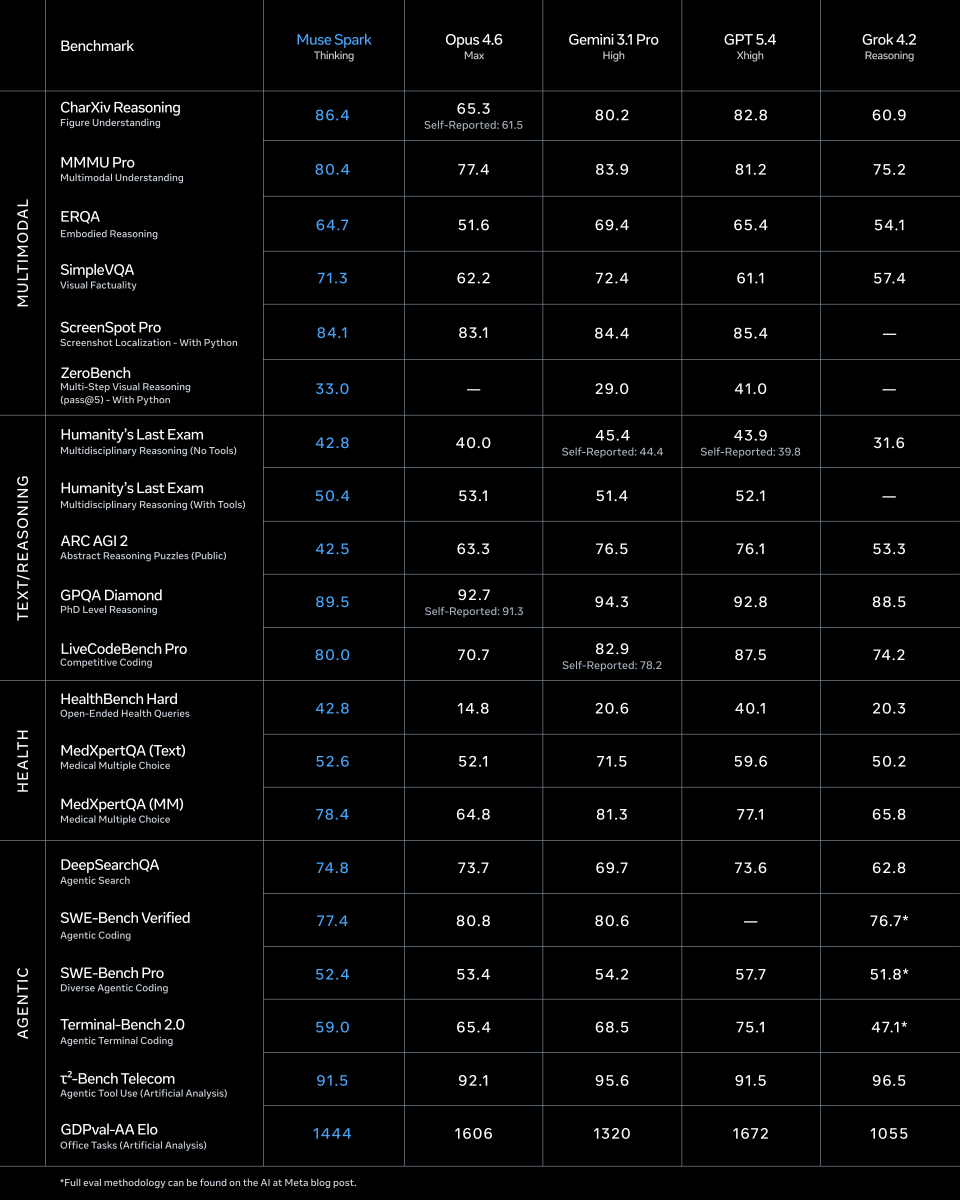
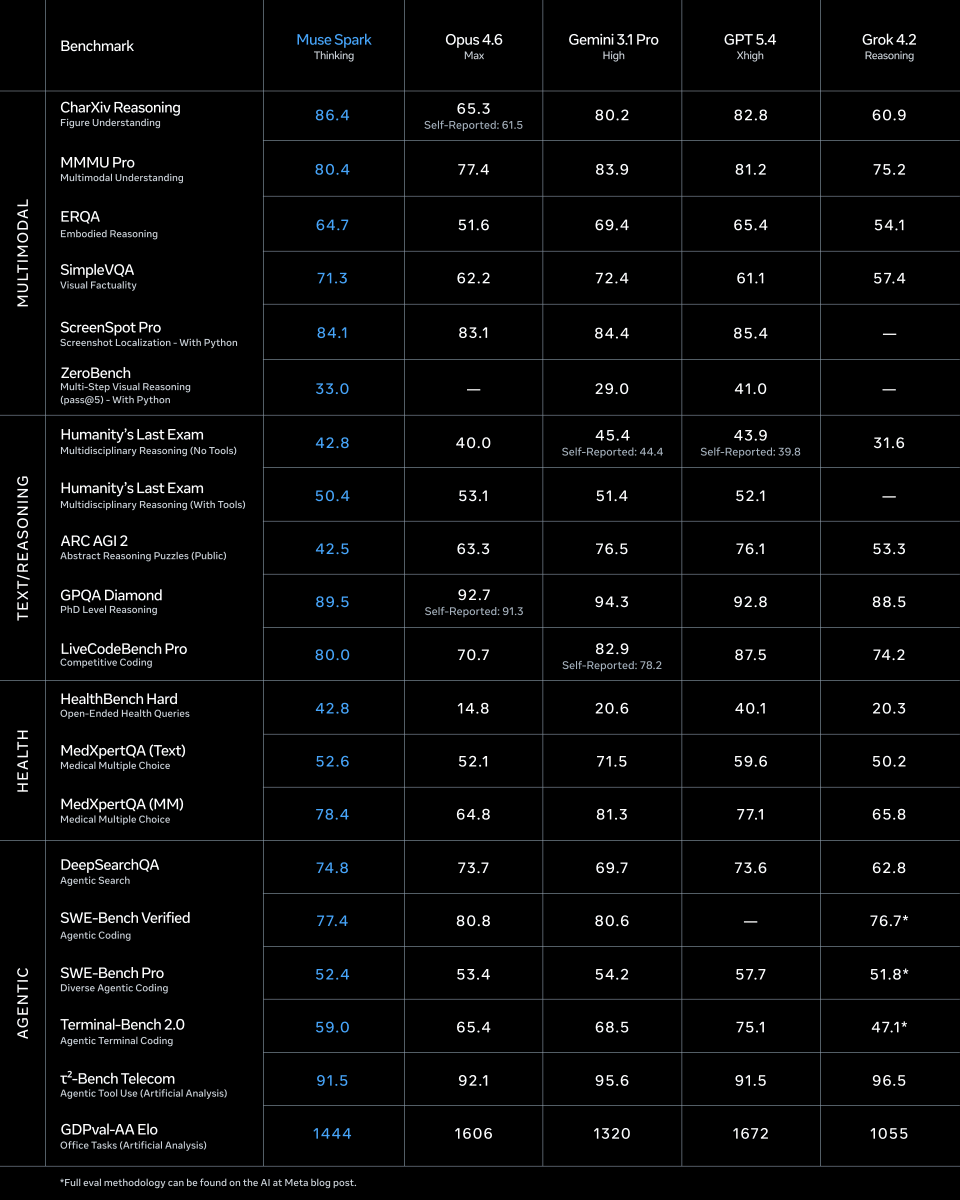
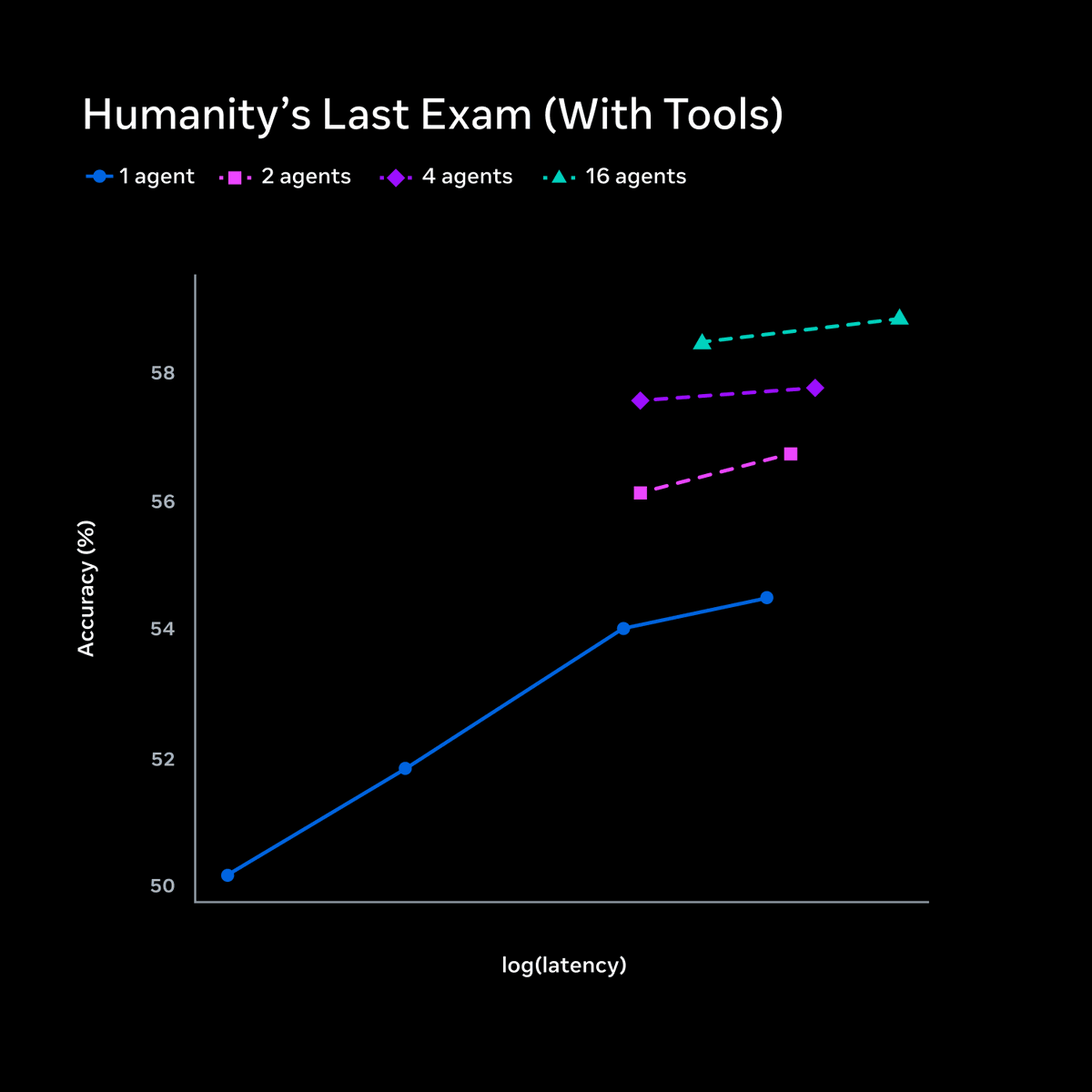
Check out Muse Spark, our first milestone in the quest for personal superintelligence! Scaling this with the team has been a total blast. Give it a spin and let us know what you think! 🥑
18
58
319
71,448
Apr 8
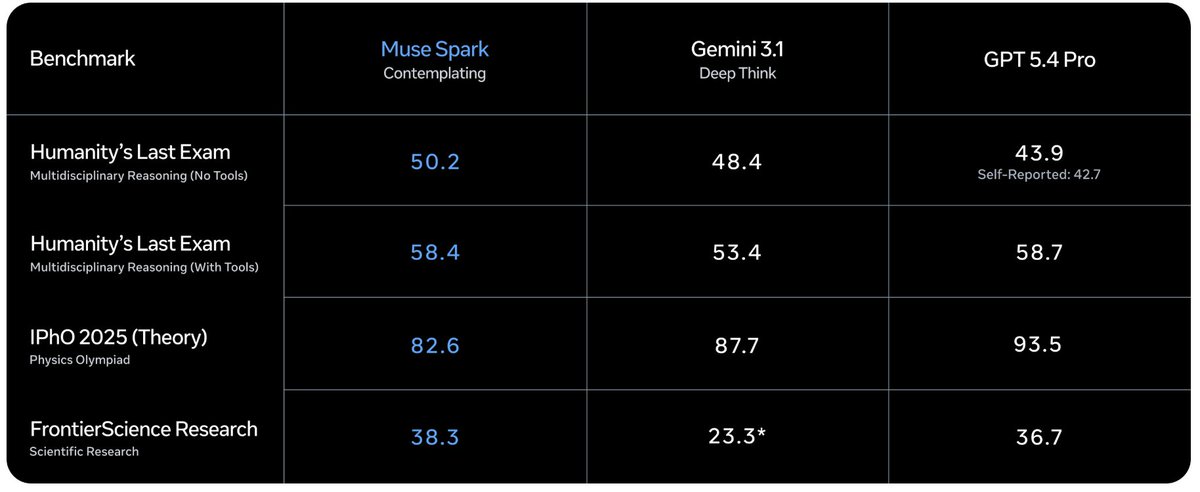
Excited to share Muse Spark, the first model release from Meta MSL. I’ve been on this project since day one and helped build it from scratch. Still early, but we’re excited to keep pushing on pretraining, RL, and test-time compute! ai.meta.com/blog/introducing…
2
112
20 Jun 2024
Super excited to share our paper won the outstanding paper in NAACL 2024.
Check out our paper: arxiv.org/pdf/2308.16137
20 Jun 2024

🎖 Excited to receive an outstanding paper award at NAACL2024 for LM-Infinite "Zero-Shot Extreme Length Generalization for Large Language Models" work!
We extend to 200M length with no parameter updates, with downstream improvements
arxiv.org/abs/2308.16137
github.com/Glaciohound/LM-In…
3
647
18 Apr 2024
Excited to share Llama3-preview (8B/70B) that achieves best MMLU results in open source models, and also preliminary results for a 405B model. Also super excited to share that we integrate Llama3 into Meta AI, the world’s best AI assistant! ai.meta.com/blog/meta-llama-…
1
360

Meta just dropped a banger:
LLaMA 2 Long.
- Continued pretraining LLaMA on long context and studied the effects of pretraining text lengths.
- Apparently having abundant long texts in the pretraing dataset is not the key to achieving strong performance.
- They also perform a large experiment session comparing different length scaling techniques.
- Surpassed gpt-3.5-turbo-16k’s on a multiple long-context tasks.
- They also study the effect of instruction tuning with RL SFT and all combinations between the two.
The model weights are not out yet.
Hopefully Soon! 🙏
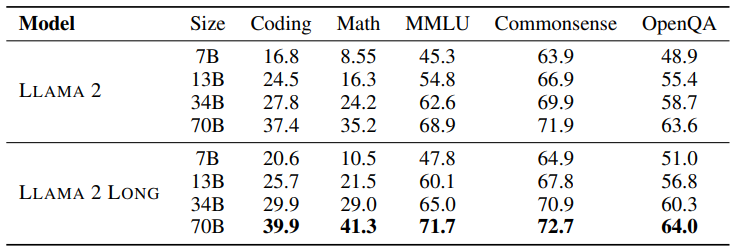
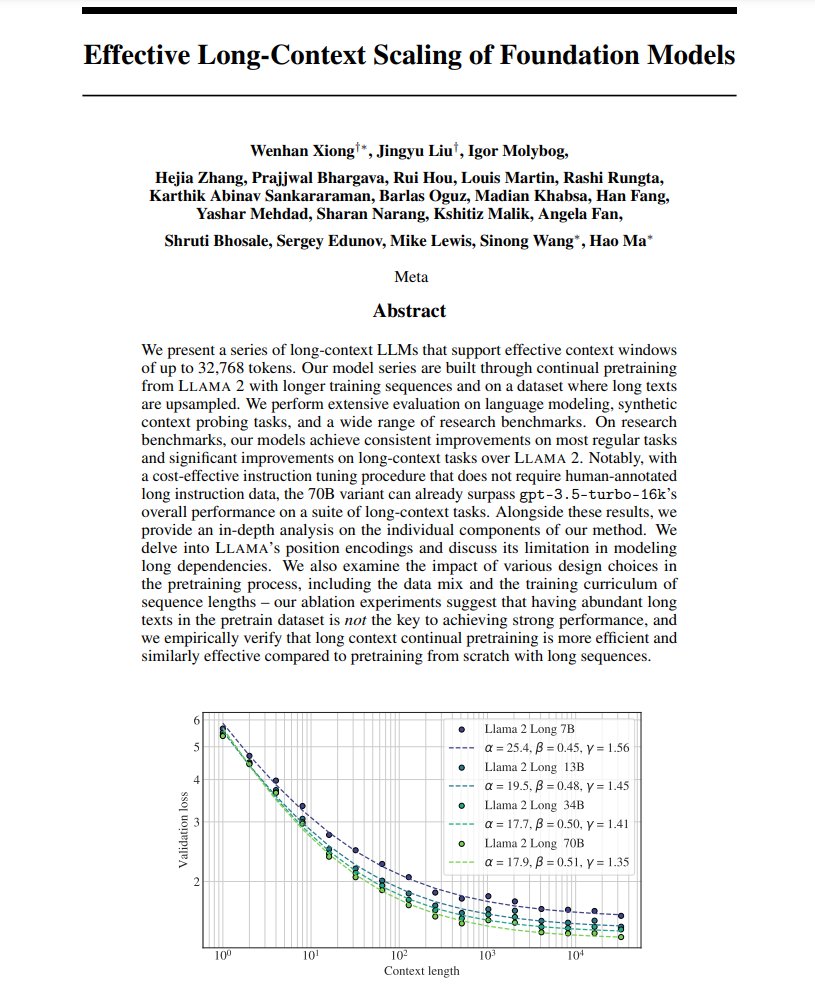
29 Sep 2023

Effective Long-Context Scaling of Foundation Models
LLAMA 70B variant surpasses gpt-3.5-turbo-16k’s overall performance on a suite of long-context tasks
arxiv.org/abs/2309.16039
13
74
527
162,980
28 Sep 2023
Excited to share our latest latest work on long context LLM, which is the new foundation model behind 28 Meta AI agents. The new long-context LLM model also achieves the better performance than ChatGPT-3.5-turbo-16k across various tasks.
27 Sep 2023

🆕 Effective Long-Context Scaling of Foundation Models ➡️ bit.ly/3ER36jT
Another piece of research that helps us build engaging conversational experiences for our AIs and the Meta AI assistant.

397
2 Sep 2023
Excited to share our latest work on extending LLM context window length without fine-tuning!

LM-Infinite: Simple On-the-Fly Length Generalization for Large Language Models
paper page: huggingface.co/papers/2308.1…
In recent years, there have been remarkable advancements in the performance of Transformer-based Large Language Models (LLMs) across various domains. As these LLMs are deployed for increasingly complex tasks, they often face the needs to conduct longer reasoning processes or understanding larger contexts. In these situations, the length generalization failure of LLMs on long sequences become more prominent. Most pre-training schemes truncate training sequences to a fixed length (such as 2048 for LLaMa). LLMs often struggle to generate fluent texts, let alone carry out downstream tasks, after longer contexts, even with relative positional encoding which is designed to cope with this problem. Common solutions such as finetuning on longer corpora often involves daunting hardware and time costs and requires careful training process design. To more efficiently leverage the generation capacity of existing LLMs, we theoretically and empirically investigate the main out-of-distribution (OOD) factors contributing to this problem. Inspired by this diagnosis, we propose a simple yet effective solution for on-the-fly length generalization, LM-Infinite, which involves only a Lambda-shaped attention mask and a distance limit while requiring no parameter updates or learning. We find it applicable to a variety of LLMs using relative-position encoding methods. LM-Infinite is computational efficient with O(n) time and space, and demonstrates consistent fluency and generation quality to as long as 32k tokens on ArXiv and OpenWebText2 datasets, with 2.72x decoding speedup. On downstream task such as passkey retrieval, it continues to work on inputs much longer than training lengths where vanilla models fail immediately.

2
386
Sinong Wang retweeted

10 Jul 2022
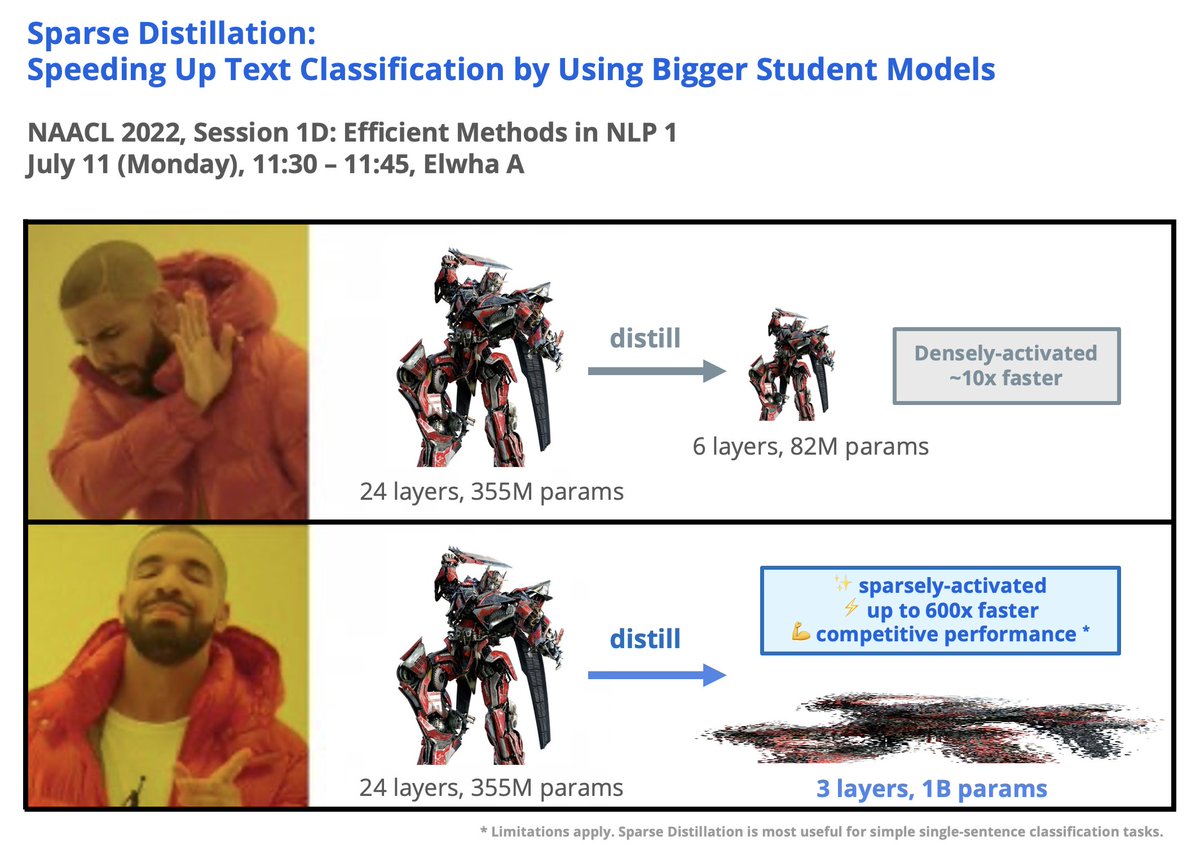
Hi #NAACL2022! Last summer we had a crazy idea of distilling transformer models into shallow, sparse, and fast models. Curious about whether and to what extent this idea works? Please come to our presentation tomorrow!
📍 Session 1D @ Elwha A
⏰ Mon 11:30-11:45
2
19
103
Sinong Wang retweeted

8 Jun 2022
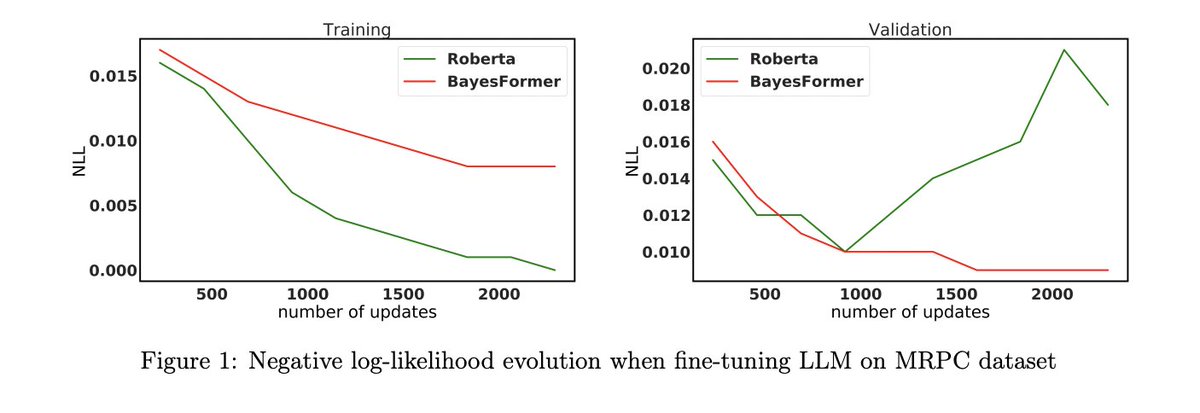
We wondered what happens when aligning dropouts with the common bayesian interpretation as a posterior over the weights, for transformers. Turns out it largely reduces over-fitting; Improvements across many apples-to-apples experiments. @sinongwang @Han_Fang_ @MetaAI
BayesFormer: Transformer with Uncertainty Estimation
abs: arxiv.org/abs/2206.00826
introduce BayesFormer, a Transformer model with dropouts designed by Bayesian theory
1
10
65
12 Apr 2022
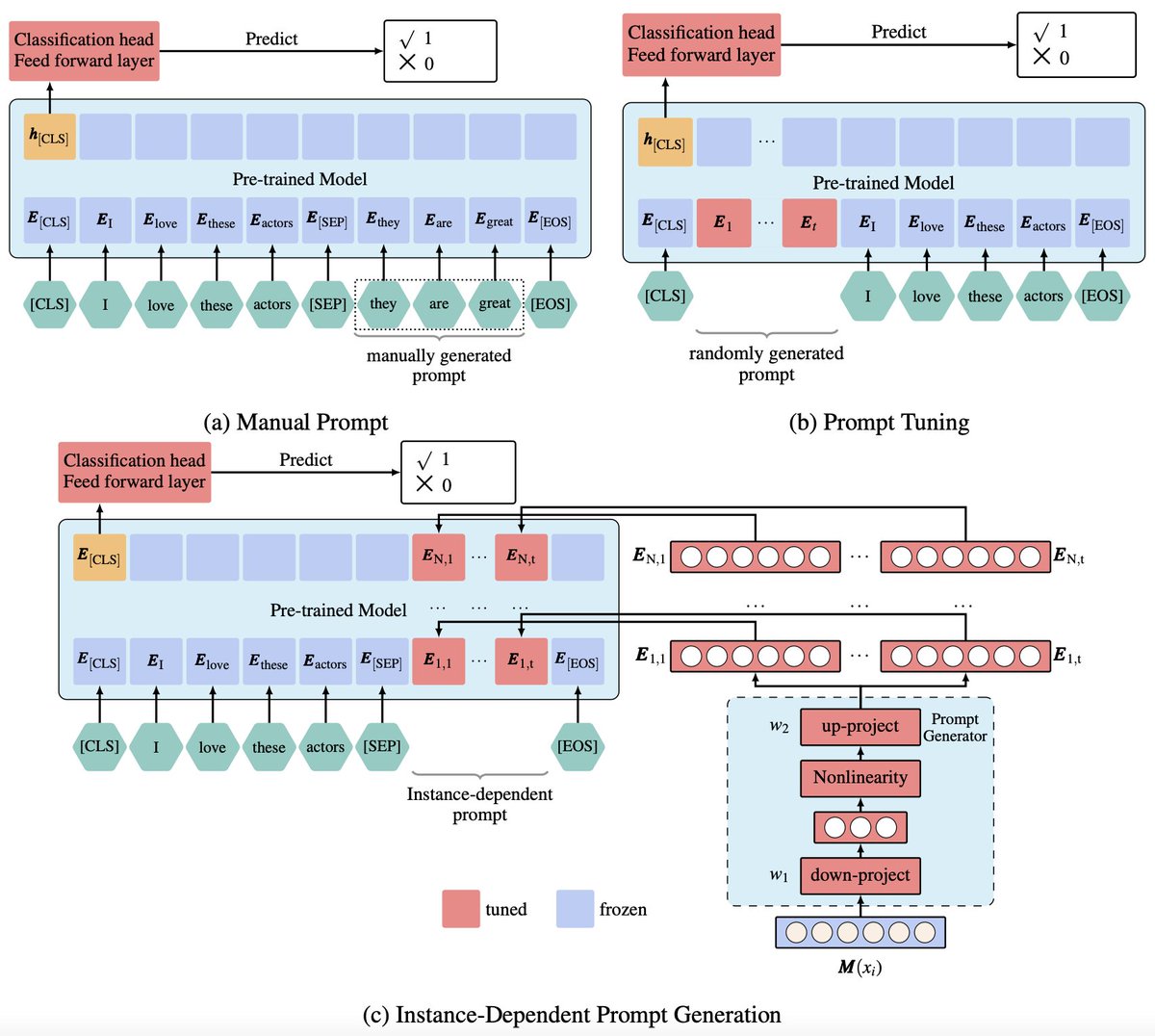
Prompt tuning can be instance-dependent. Thrilled to share our new work!
"IDPG: An Instance-Dependent Prompt Generation Method".
Check out our paper here: arxiv.org/pdf/2204.04497.pdf
1
1
2
Sinong Wang retweeted

9 Dec 2021
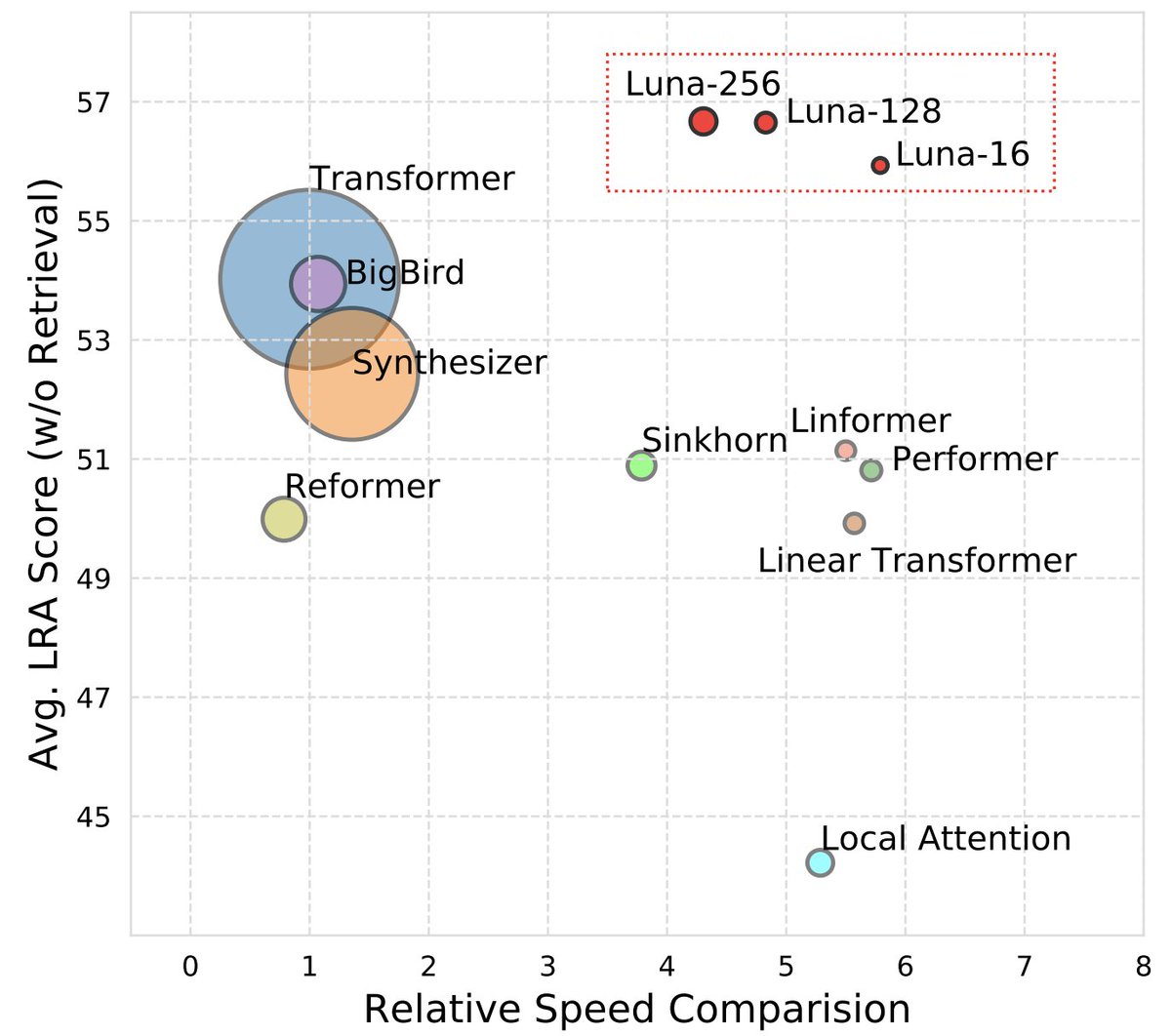
Thrilled to share our #NeurIPS2021 work! "Luna: Linear Unified Nested Attention". This is a new linear time transformer architecture achieves competitive results across multiple benchmarks.
co-authors: @XiangKong4 @sinongwang @violet_zct @jonathanmay @gabema @LukeZettlemoyer
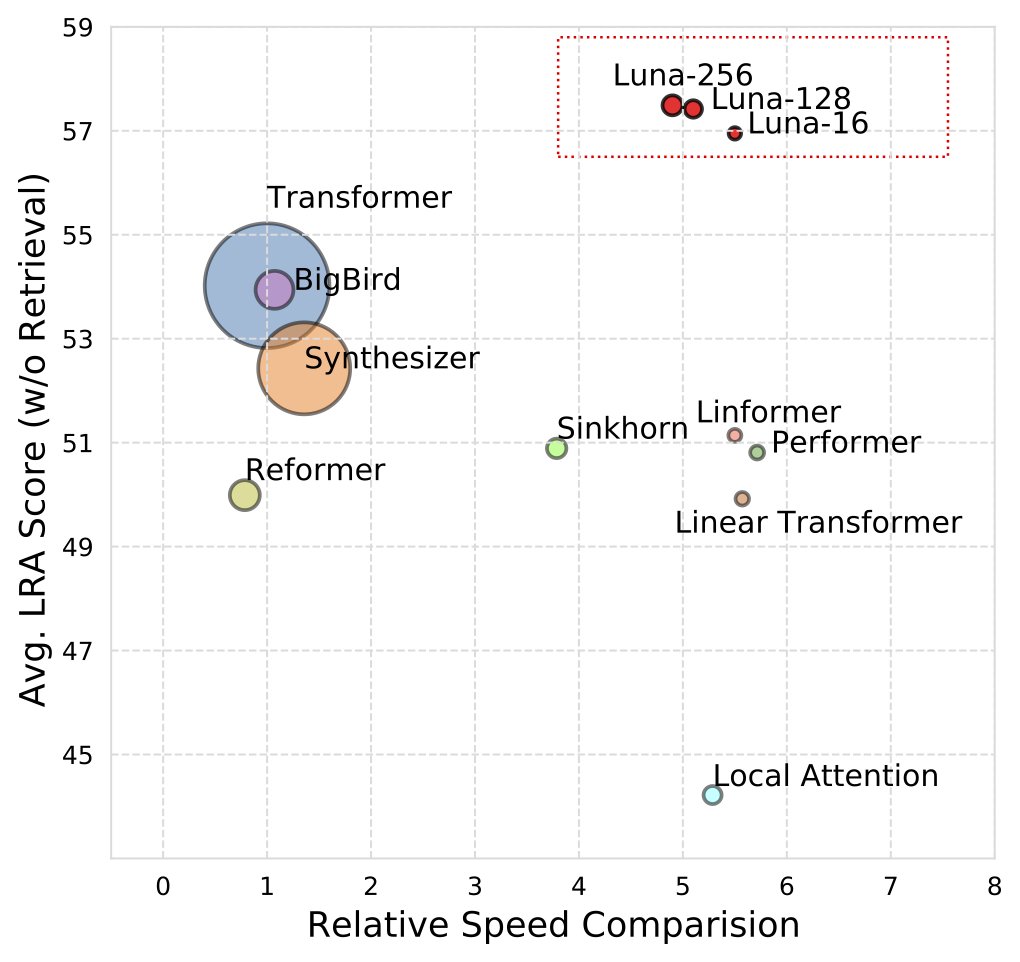
1
7
47
8 Jun 2021
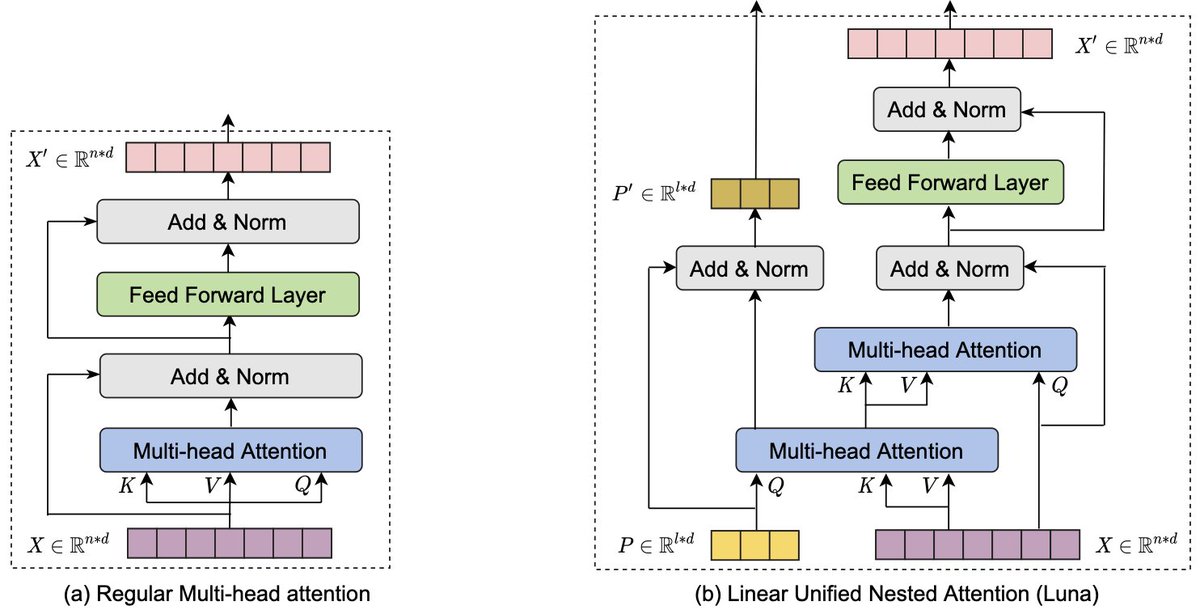
Thrilled to share our new work! "Luna: Linear Unified Nested Attention".
This is a new linear time transformer architecture achieves competitive results across multiple benchmarks.
Check our our paper here: arxiv.org/pdf/2106.01540.pdf
The implementation: github.com/XuezheMax/fairseq….
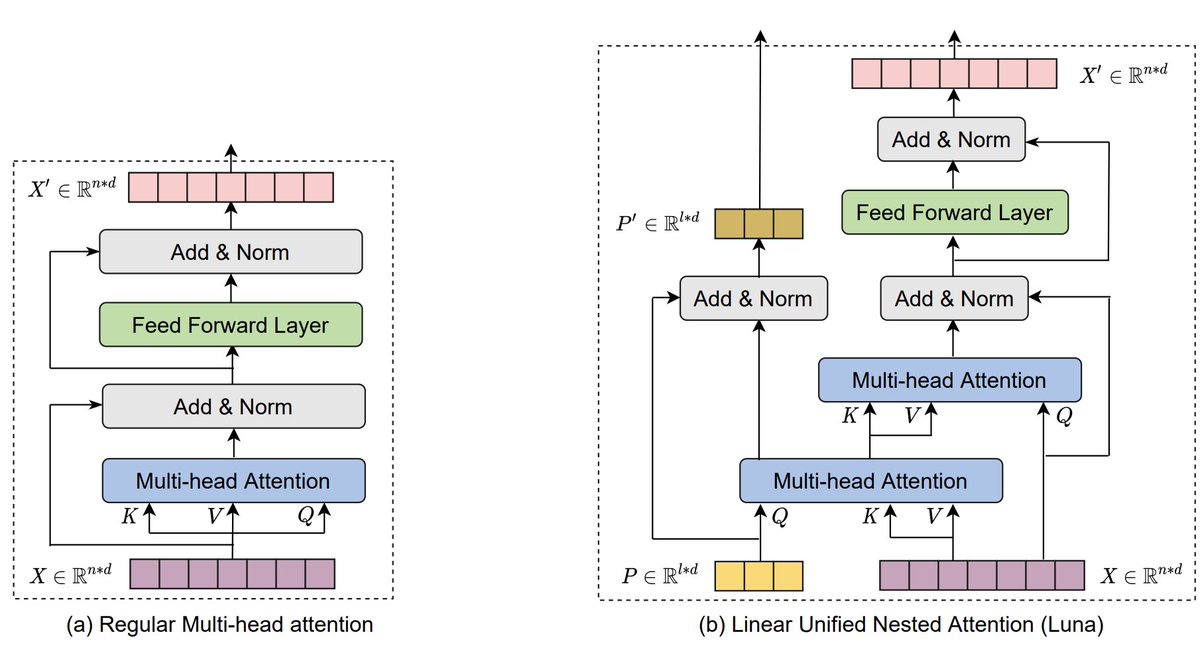
1
10
39
3 May 2021
You don't need a 175B GPT-3 for few shot learning. All you need is entailment! Check out our new preprints: arxiv.org/pdf/2104.14690.pdf
In short, we propose a new method turning small LM into better few shot learner.
@Han_Fang_ @MadianKhabsa @hanna_mao @gabema
3
16
88
17 Jun 2020
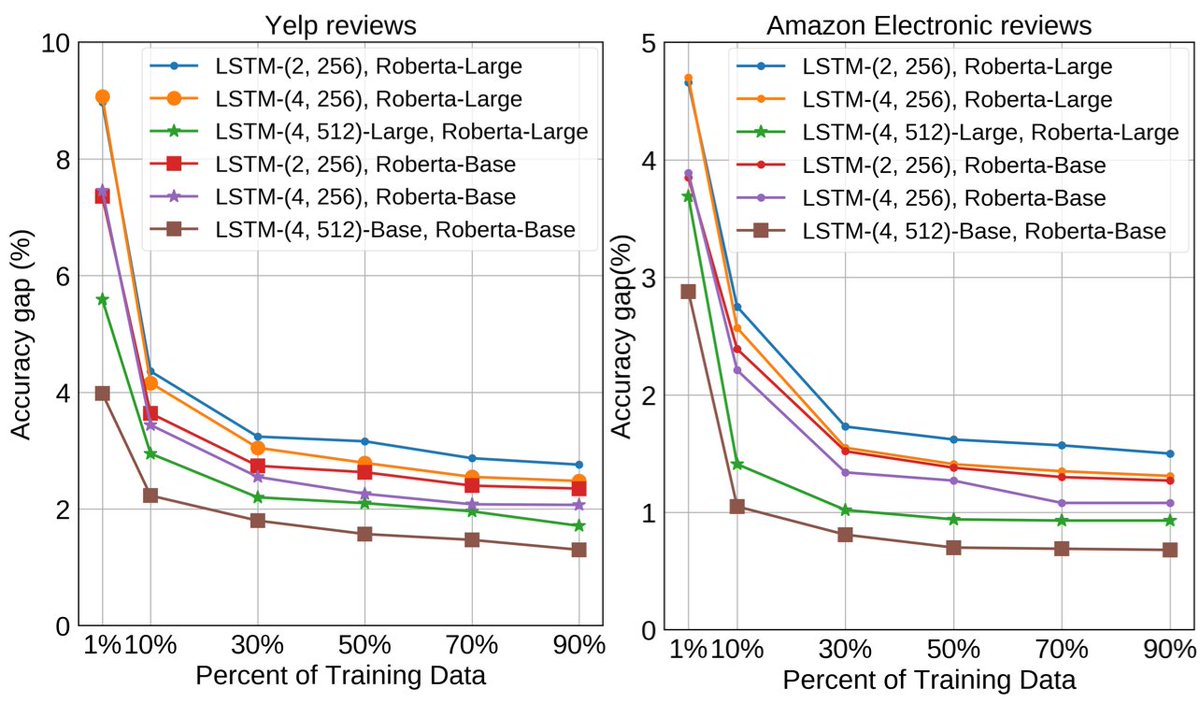
SOTA in NLP is typically achieved by LM pretraining followed by finetuning. Our recent paper in ACL shows that pretraining has a diminishing return as the number of training examples increases, and LSTM can be within 1 percent of BERT models.
Link: arxiv.org/pdf/2006.08671.pdf
4
54
243
Sinong Wang retweeted

11 Jun 2020
The Linformer projects self-attention into a lower-dimensional space and achieves linear-time instead of quadratic resource-requirements. Independent of sequence length! 💪 Watch the video here:
youtu.be/-_2AF9Lhweo
@sinongwang @belindazli @MadianKhabsa @Han_Fang_ @facebookai

11
39
210
9 Jun 2020
Thrilled to share our new work! "Linformer: Self-attention with Linear Complexity".
We show that self-attention is low rank, and introduce a linear-time transformer that performs on par with traditional transformers.
Check our here: arxiv.org/pdf/2006.04768.pdf
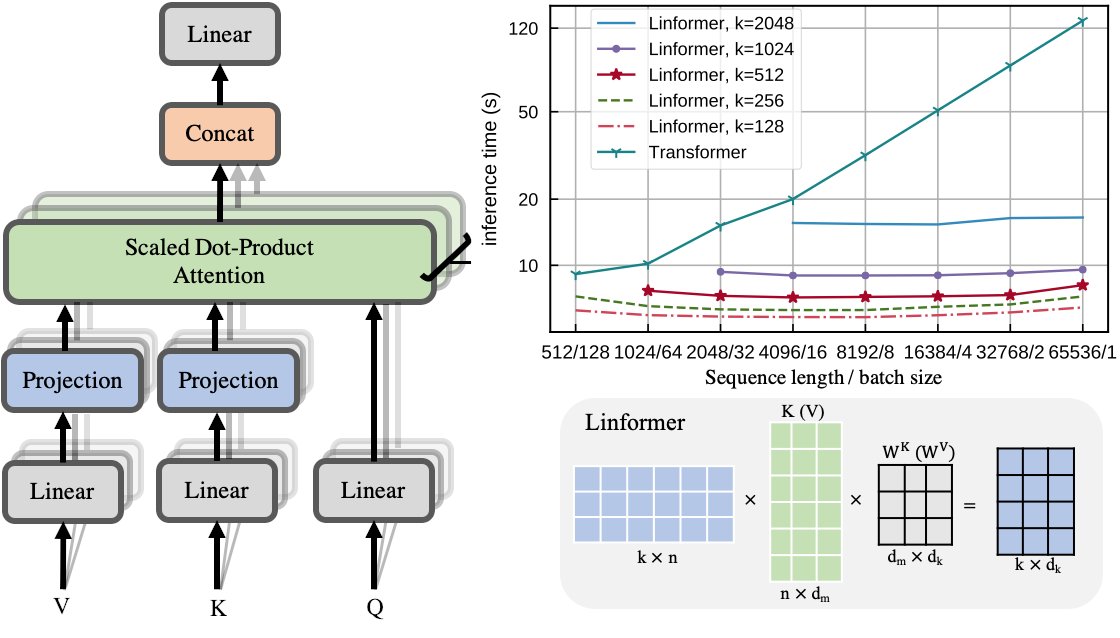
7
85
339