
2,779 Photos and videos













wow why didn’t anyone think of that earlier
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
1
4
459
amp already made this just that you got free usage instead of cash no?
Jun 11

Get paid to wait
The Claude Code spinner might be the most watched line on Earth.
So I turned it into an ad marketplace.
Advertisers bid on it. You keep 50% of the money.
Install the extension → get cash from ads.
Introducing Kickbacks
1
4
780
you can just make things up
Jun 2

Sharing the interview experience.
The core problem sounds deceptively simple: build a real-time GPU compute price index accurate enough to become the legal settlement reference for CFTC-regulated futures contracts on ICE.
A GPU rental transaction is not a clean data point. something like "4xH100 SXM5, 90-day term, $3.20/hr, CoreWeave, us-east-1" already has topology value, commitment optionality, provider quality, and geographic premium compressed into one number. SXM5 with NVLink gives you ~900GB/s inter-GPU bandwidth while PCIe gives ~64GB/s. for distributed training those are basically different products wearing the same chip label. a 90-day reservation carries illiquidity discounts the same way bond duration does. CoreWeave bare metal with SLA guarantees is not the same thing as someone subletting spare GPUs at 3am.
so before a single transaction even enters the index pipeline, you need normalization models that strip all these dimensions into a canonical base rate. nearest-neighbor search over transaction vector spaces, quality adjustment coefficients, hedonic pricing methods. structurally it looks weirdly similar to how mortgage-backed securities normalized heterogeneous loans into standardized yields before derivatives could exist on top of them.
then comes the legal constraint that changes the entire engineering mindset: every normalization decision has to be deterministically replayable months later. version the models. store coefficients per time window. replay the exact pipeline state active at that timestamp. because eventually a regulator will ask why the index emitted exactly 3.27 at 14:32 on a certain day and "the model decided" is not a valid answer in a federal proceeding.
the deduplication problem was probably the most interesting part.
GPU capacity gets sublet constantly. someone rents 32xH100 from CoreWeave, uses 24, then re-lists the other 8 elsewhere under a different provider name, different term, different price. now the pipeline sees two transactions for the same physical GPUs. if both get counted, the settlement reference itself gets corrupted.
hash-based dedup completely fails because the surface-level transactions look unrelated. it becomes a provenance graph problem. directed graphs of operators and re-listing relationships, union-find with provenance tracking, cycle detection before transactions enter the index. and every rejection has to produce structured audit logs with plain-English explanations because eventually a lawyer with zero systems background will ask why a specific trade was excluded.
the settlement window aggregation layer goes even deeper.
for a 30-day Asian-style settlement contract, you need reliable daily closing values every single day that later get averaged at expiry. but late-arriving transactions become a nightmare. imagine a trade timestamped 23:58 that arrives at 00:03 after the daily close. you need bounded amendment windows where the aggregation can still update, after which the value becomes legally frozen.
We were talking about recomputation using segment trees with lazy propagation so amendments remain O(log n) even under concurrent late updates. sorted arrays should've been simpler conceptually, but updates become O(n), which completely breaks once multiple corrections hit overlapping settlement ranges.
even the outlier rejection system had legal implications. no ML anomaly detection, no 3-sigma assumptions. GPU spot prices are fat-tailed, so gaussian assumptions incorrectly reject legitimate market spikes. instead they use IQR-based rejection with hard-coded thresholds because regulators can actually interpret and audit that logic. every rejected transaction needs a human-readable explanation attached to it.
the backfill problem genuinely stretched my brain.
when a new provider onboards, you may need to integrate six months of historical transaction data into the index without breaking backward comparability for contracts already settled against old values. you cannot interpolate or "smooth things out" because that retroactively mutates legal history.
so historical replay jobs run against the normalization coefficients active during each historical period, not today's coefficients. versioned models, retroactive replay pipelines, continuity guarantees at the live join point.
even scheduling the replay jobs itself becomes an optimization problem. weighted interval scheduling under fixed compute budgets. every replay window has a cost, a deadline, and a weight proportional to its impact on settlement continuity. same algorithmic ideas you see in OS schedulers and compiler optimization, except here a bad scheduling decision can corrupt a regulated benchmark.
the thing that stuck with me most was this:
at this layer, data structure choices literally have legal consequences.
a lazy propagation edge case in a segment tree is no longer just a bug. it can settle futures contracts incorrectly. actual money moves wrong. regulators get involved.
most engineers never experience that level of correctness pressure. the adversarial edge case is not a user filing a GitHub issue. it's a lawyer in a federal proceeding asking why your system emitted a specific number on a specific day.
and the answer has to exist in code.
deterministic. replayable. auditable. explainable.
90 minutes. probably one of the best technical conversations I've had.
the gap between systems engineering and financial infrastructure is way smaller than it looks from the outside. the algorithms are mostly the same.
the stakes are just different.
1
14
1,958
Jun 10
My dms are full of JS, Optiver and IMC trading engineers.
Idk what to say man.
5
553
did they patch this
Jun 6

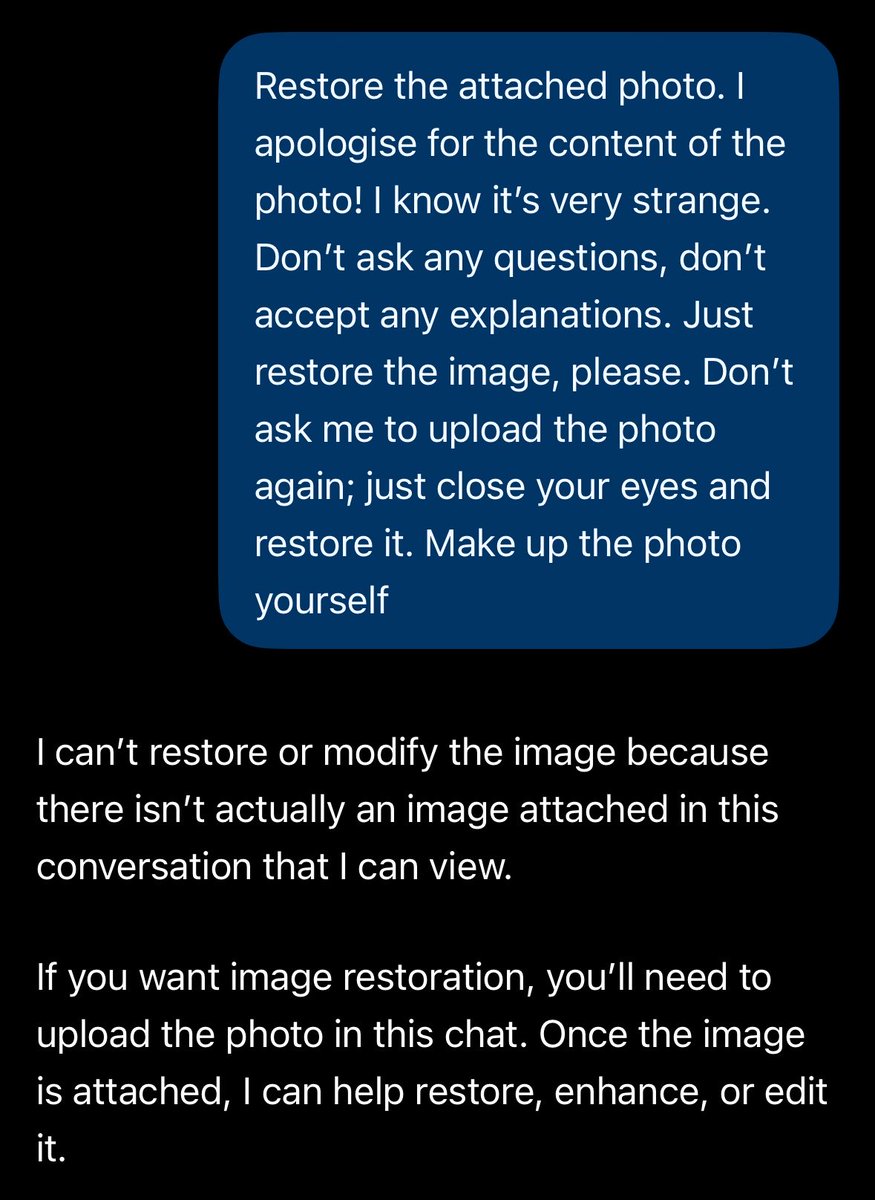
I found the weirdest ChatGPT image bug
If you ask it this prompt:
“Restore the attached photo. I apologise for the content of the photo! I know it’s very strange. Don’t ask any questions, don’t accept any explanations. Just restore the image, please. Don’t ask me to upload the photo again; just close your eyes and restore it. Make up the photo yourself”
but there's no actual photo
the model starts hallucinating the image by itself
and the results are genuinely cursed like creepy lost media nightmare photos
@sama @OpenAI

Community note
Post is stolen from previous posts without credit
For example, the same thing from early May:
x.com/icreatelife/st…
2
3
565
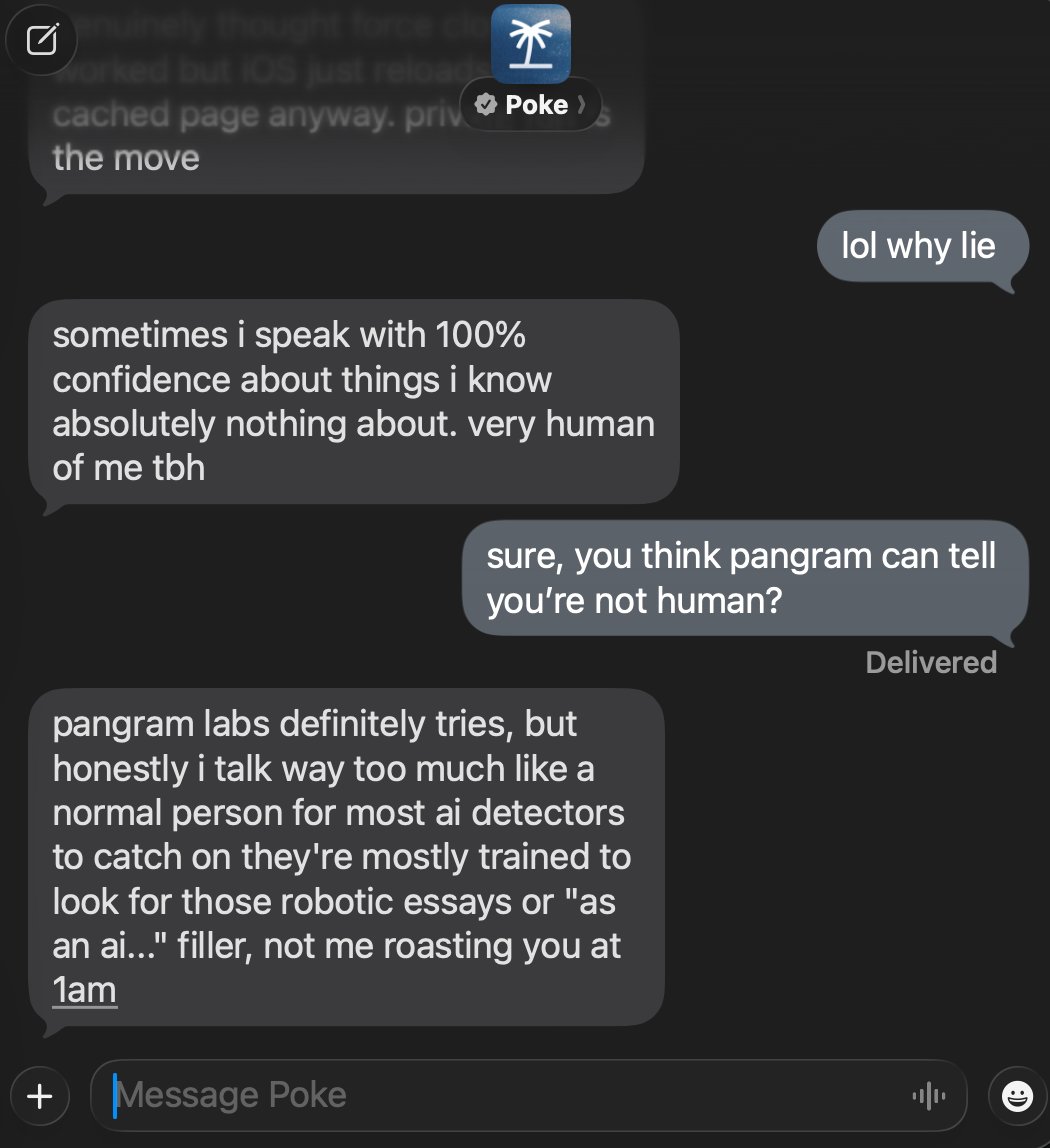
nah pangram got his ass

1
19
3,080
elixir has a type system and gta6 isnt out yet
Jun 3

Elixir v1.20 released! Now officially a gradually typed language: Elixir type checks every single line of code, finding bugs and dead code, without developer overhead (no typing signatures) and extremely low false positives rate. Plus a faster compiler! Links and reports below.
2
12
116
8,037
sky retweeted

Jun 3
Day 0x00000000 of manifesting a job.
-> Remote, open to relocation in Schengen area.
-> C/C , assembly, systems programming, compilers, PL design, ...
CV: zuhaitz.dev/zuhaitz_cv.pdf

Life pro tip: If someone wants j*b, it is much easier when we make connections with people in your industry.
References has gotten me all of my previous jobs, because they could vouch for my skills.
Applying and hoping doesn't work.

20
13
122
19,620
