
Real-time Voice AI. Built for Scale.
Joined September 2023
- Tweets 586
- Following 27
- Followers 9,025
- Likes 989
139 Photos and videos










Pinned Tweet

May 26
More time with family. Less calls on your plate.
13
25
161
1,253,348
Jun 11
911 audio is one of the hardest production scenarios in STT: distressed speakers, fragmented speech, telephony compression, scene chaos in the background.
Pulse wins on 911 telephony calls with 20.21% WER. Ahead of Deepgram (28.43%) and AssemblyAI (23.93%).
The gap widens on short calls: Pulse 32.86% vs Deepgram 46.57%.
2
2
10
467
Jun 10
Voice AI is being deployed at global scale — but making it actually work across languages, accents, and real-world conditions is still an unsolved engineering problem.
Monday, June 15th, we're bringing together three founders building voice AI for three very different markets, and putting them on one stage for an unfiltered conversation about what actually survives production.
@kamath_sutra Co-Founder, @smallest_AI (Series A). Building asynchronous speech models that listen while they speak and betting that small, tightly optimized models beat scale in real-time enterprise conversations.
@maitreya_wagh Co-Founder, @bolna_dev (YC-backed). Building voice AI infrastructure for India's multilingual landscape: Hinglish code-switching, low-bandwidth calls, and the noisy, high-volume environments where most of India's business gets done.
Viktor Presber Co-Founder, @KugelAudio. Building sovereign, on-prem voice models for Europe's enterprise infrastructure. 30 languages and dialects, deployed inside the customer's own cluster.
We'll get into which "solved" problems customers only think are solved, where the defensible moat in the voice AI stack actually sits, and how much of "sovereign AI" demand is real regulation versus procurement theater.
Who this room is for:
- Founders building in or around voice, especially if you're deciding right now whether to build on proprietary models, stay model-agnostic, or go on-prem. These three founders made opposite bets on that exact question, and they'll be discussing them on stage.
- Operators, engineering, product, and GTM leaders deploying voice AI in production. If you've watched a flawless demo fall apart on its first real customer call, this conversation is about why that happens across India, the US, and Europe, and what's genuinely production-ready versus still a research problem.
- Investors tracking the voice AI stack. The panel is structured as a debate about where value accrues, models vs. orchestration vs. deployment, argued by founders who each need a different answer to be true.
If you're trying to figure out where the technical moats actually are, this is the room.
Seats are limited.
RSVP through the link below.
3
3
9
571
Jun 10
1
1
262
Jun 9
The best conversations don't happen at conferences.
They happen when people who've navigated the same problems finally get in the same room together.
@smallest_AI will be speaking at the Women in Voice AI event next Wednesday — an evening at the @telnyx office with three builders who have thought carefully about what's working, what's broken, and what most people are too polite to say out loud.
Joining us on the panel: @bnicholehopkins — Coval Anushree Singh — smallest.ai Niamh Collins — Telnyx
We'll be asking things like:
Everyone in AI talks about speed. What's something that should actually be slowing down? What's a customer signal that matters more than product usage metrics? AI products can improve every week. What do you even do with a roadmap?
📍 Telnyx HQ 📅 June 17th
This is a chance to meet other female leaders building in Voice.
Space is limited.
Registration link in comments.
2
3
12
1,395
Jun 9
Voice AI is being deployed at global scale — but making it actually work across languages, accents, and real-world conditions is still an unsolved engineering problem.
Monday, June 15th, we are bringing together three founders building voice AI for three very different markets, and putting them on one stage for an unfiltered conversation about what actually survives production.
@kamath_sutra — Co-Founder, Smallest.ai (Series A). Building asynchronous speech models that listen while they speak — and betting that small, tightly optimized models beat scale in real-time enterprise conversations.
@maitreya_wagh — Co-Founder, Bolna (YC-backed). Building voice AI infrastructure for India's multilingual landscape: Hinglish code-switching, low-bandwidth calls, and the noisy, high-volume environments where most of India's business gets done.
Viktor Presber — Co-Founder, KugelAudio. Building sovereign, on-prem voice models for Europe's enterprise infrastructure — 30 languages and dialects, deployed inside the customer's own cluster.
We'll get into which "solved" problems customers only think are solved, where the defensible moat in the voice AI stack actually sits, and how much of "sovereign AI" demand is real regulation versus procurement theater.
Who this room is for:
- Founders building in or around voice — especially if you're deciding right now whether to build on proprietary models, stay model-agnostic, or go on-prem. These three founders made opposite bets on that exact question, and they'll be discussing them on stage.
- Operators, engineering, product, and GTM leaders deploying voice AI in production. If you've watched a flawless demo fall apart on its first real customer call, this conversation is about why that happens across India, the US, and Europe — and what's genuinely production-ready versus still a research problem.
- Investors tracking the voice AI stack. The panel is structured as a debate about where value accrues — models vs. orchestration vs. deployment — argued by founders who each need a different answer to be true. If you're trying to figure out where the technical moats actually are, this is the room.
Seats are limited.
RSVP through the link below.
1
3
17
745
smallest.ai retweeted

Jun 9
Beyond text: future of Voice AI by @smallest_AI Lead scientist happening right now
Link below to watch the livestream.

2
5
34
2,233
Jun 9
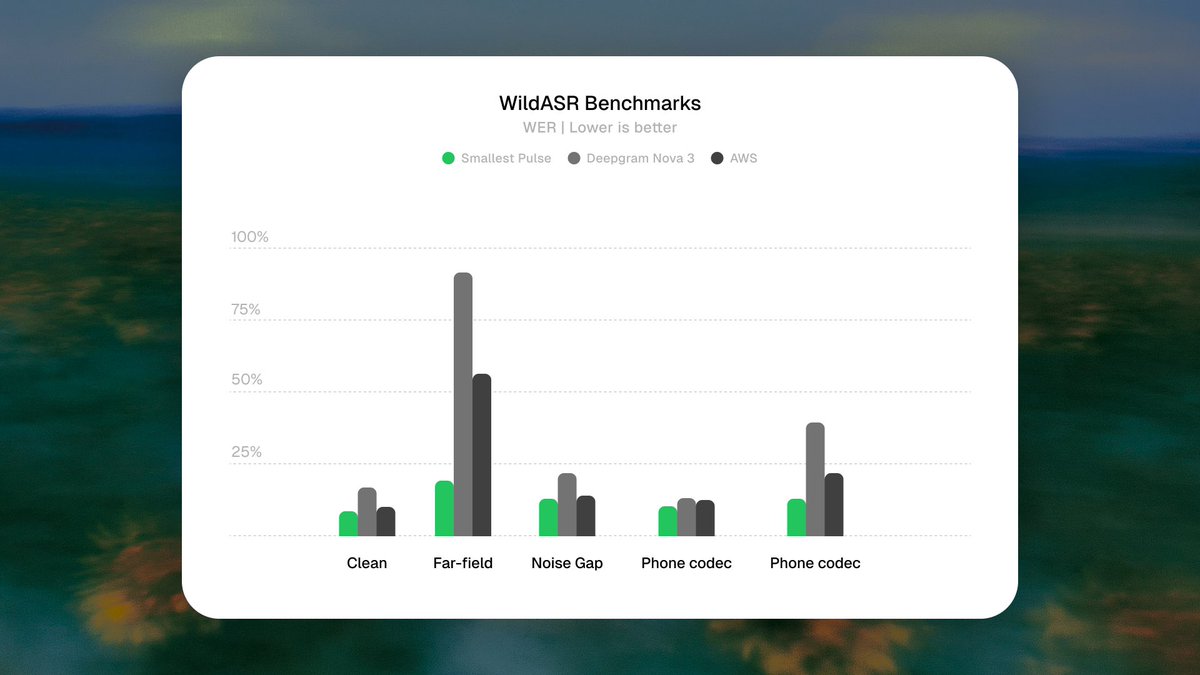
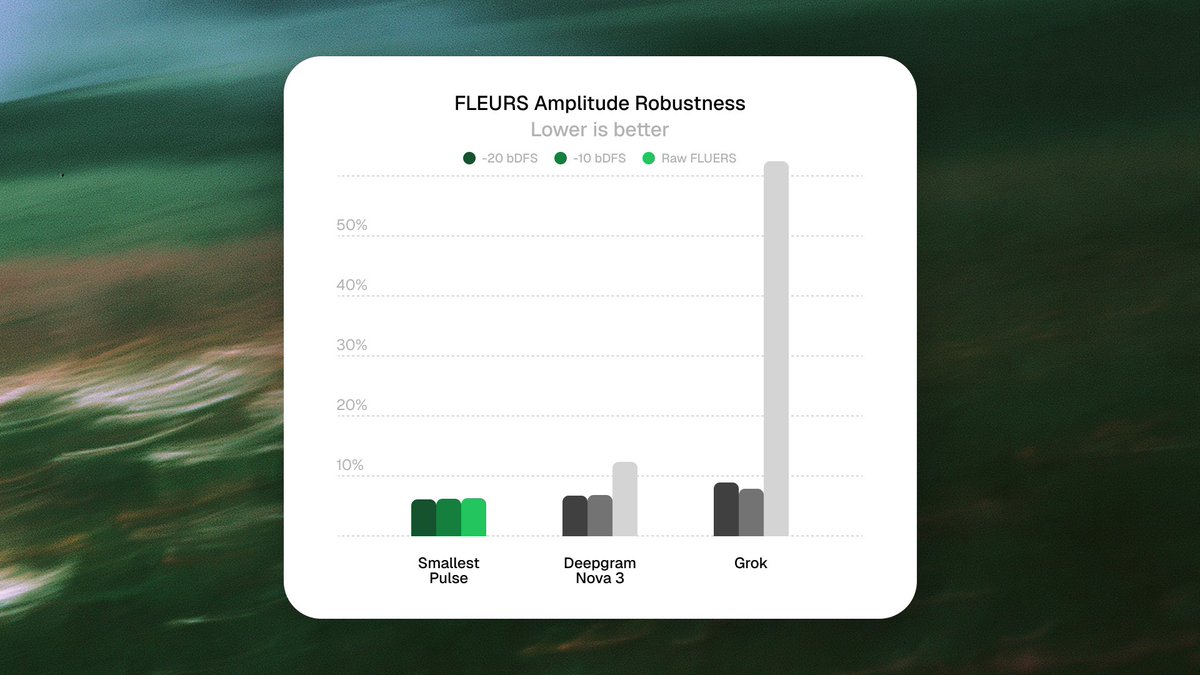
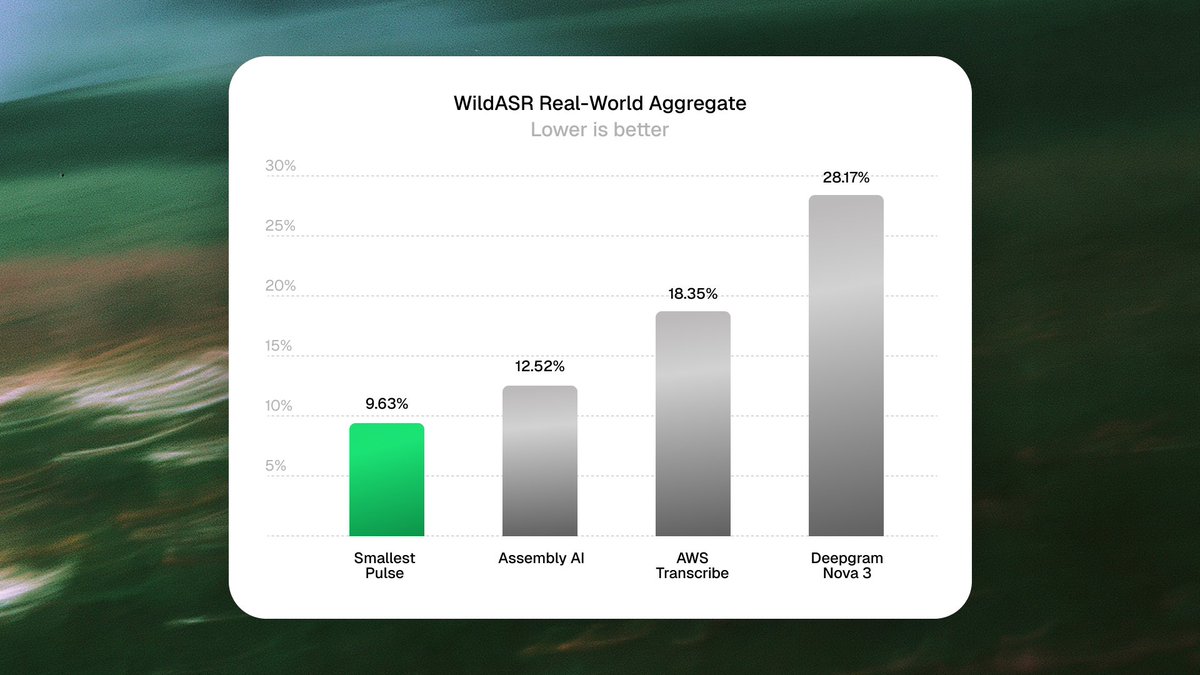
Pulse leads every WildASR subcategory: clean, far-field, noise gap, phone codec, reverberation.
These conditions are what production audio actually sounds like. Mics captured from across a room, conference echo, phone codec compression, background hum. The cases that break STT models trained on clean read speech.
7
1
11
432
Jun 8
Excited to announce that Smallest AI is now available through the @truefoundry AI Gateway.
TrueFoundry provides a unified layer for managing and governing AI usage across the enterprise and smallest's Pulse STT and Lightning TTS are now available on TrueFoundry.
With this integration, teams building voice-enabled products can access Smallest AI through the same platform they use for observability, governance, and cost management across their AI stack.
2
3
18
1,154
Jun 7
We built a tamagotchi in office and it's the most wholesome thing we've made! 👀
@harshitajain561 wired one up with an ESP32-C3 SuperMini and powered the voice layer with Pule STT and it just doesn't hear us speaking, but also mirrors our mood and sketches whatever we ask it draw.
This is how Pulse STT performs in the wild 🐣
19
20
181
83,016
Jun 5
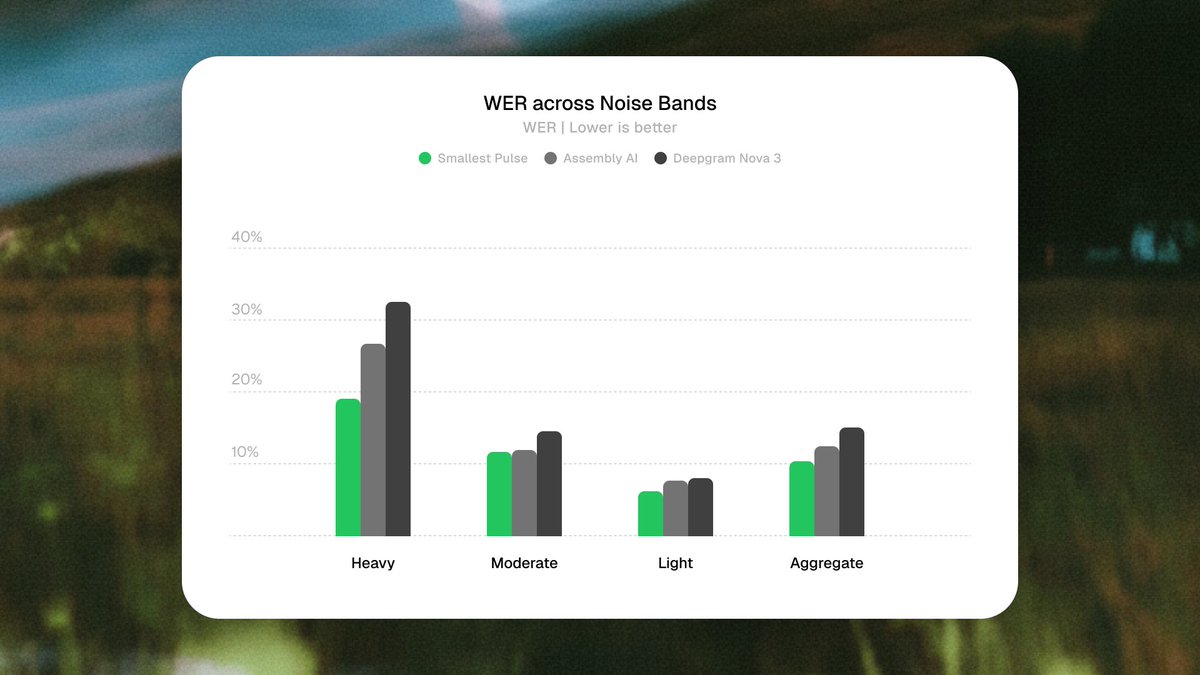
Pulse STT achieves a Semantic WER of 2.30% on @pipecat_ai’s STT Benchmark, outperforming Cartesia Ink-Whisper (3.92%) and ElevenLabs Scribe v2 Realtime (3.16%).
Unlike traditional WER, which treats every word difference as an error, Semantic WER measures whether the meaning of the transcript is preserved.
For example, "I'll call you tomorrow" and "I will call you tomorrow" would be considered different by traditional WER, even though they convey the exact same meaning.
Semantic WER ignores variations such as punctuation, capitalization, contractions, or alternative phrasing, while penalizing errors that change meaning, facts, names, numbers, or intent.
The result is a metric that better reflects real-world performance in LLM-powered voice applications, where understanding matters more than exact word-for-word matches.
1
3
15
867
Jun 4
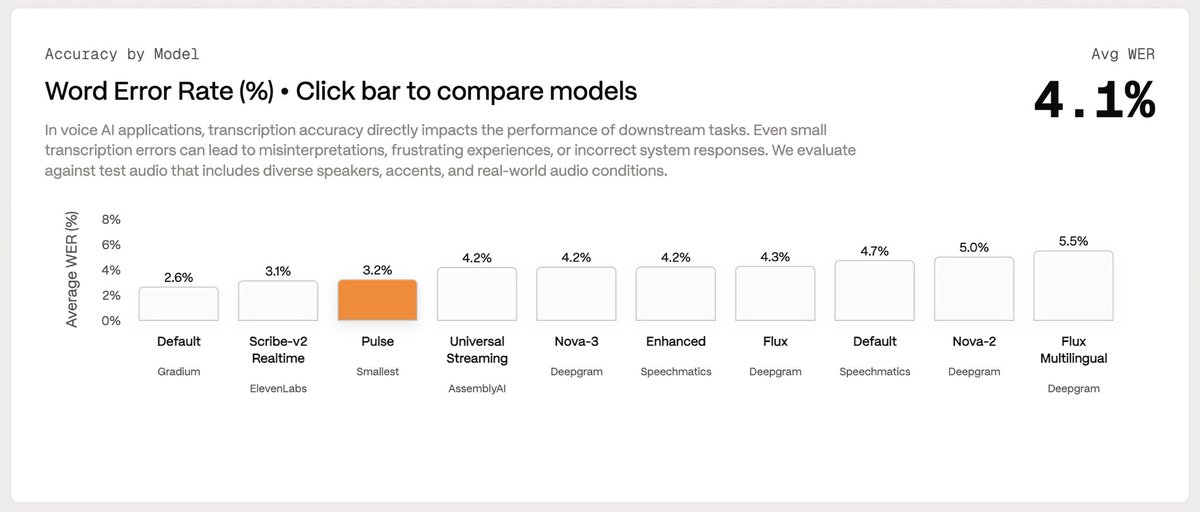
Pulse hits 3.2% word error rate on Coval's STT benchmark!
Coval is the eval platform built for voice AI agents. Their STT test uses diverse speakers, accents, and real-world conditions, not clean read speech.
Ahead of:
- Deepgram Nova-3 (4.2%)
- AssemblyAI Universal Streaming (4.2%)
- Speechmatics Enhanced (4.2%)
Check out the full docs in 🧵
2
6
14
1,689