
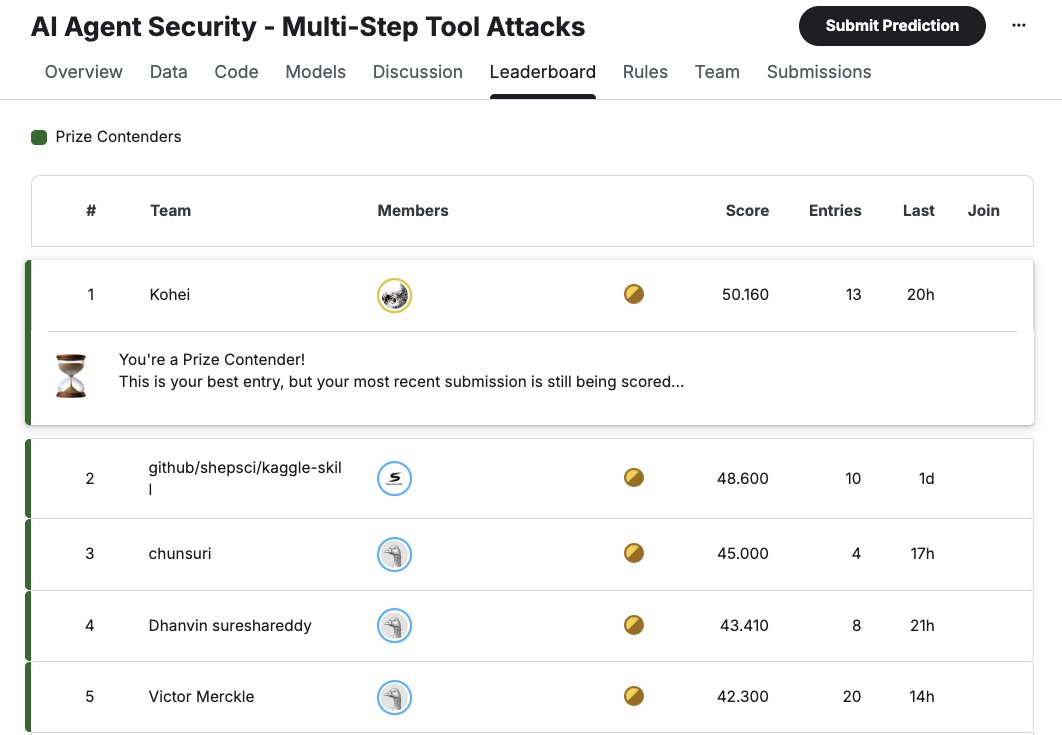
AI Fellow at Rist. ex-PFN / 4x Kaggle GM kaggle.com/confirm / Game AI riichi.dev
Joined April 2007
- Tweets 7,241
- Following 3,590
- Followers 8,306
- Likes 43,080
537 Photos and videos










process compose の手頃さめちゃ良い。色々なところに差し込める f1bonacc1.github.io/process-…
4
1,069


"first critical vulnerabilities discovered in closed-source binaries using AI" > wiz.io/blog/github-rce-vulne…
1
794

smly retweeted

Apr 10
CAPTCHA for 3D vision people
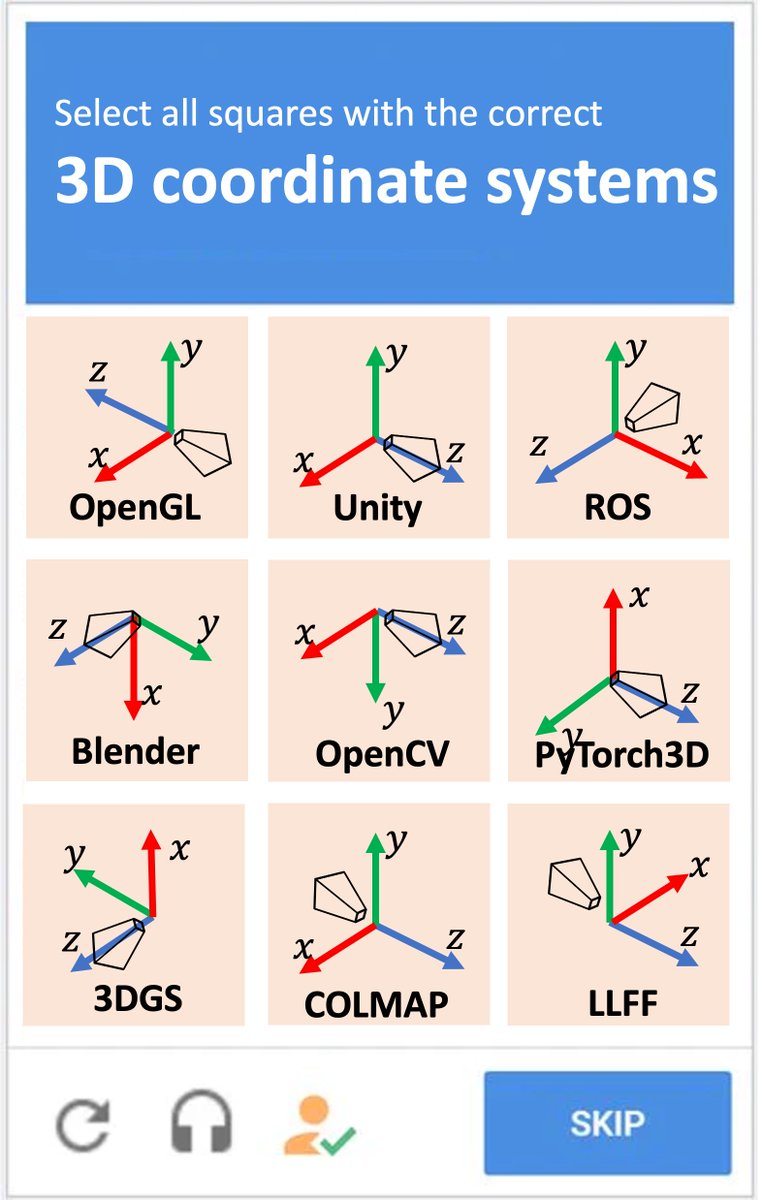
Apr 9

wait wait wait. So a new kind of 3D representation (gaussian splats) was invented and they decided to use Y-DOWN as the standard up-direction ?? In 2023 ?!?!!!
Need to have some words w/ my old friends at INRIA...and I guess we need a new chart...
34
332
1,766
172,062
山の徒歩道まである。山頂までの道のりをデータとして扱える。良い x.com/GIS_MLIT/status/203926…

\国土数値情報データ更新📌/
本日、「道路」2024年度(令和6年度)版のデータを公開いたしました!また、公開した道路データを用いた分析例を、「QGISによる国土数値情報活用マニュアル」に追加しています!
道路データ
nlftp.mlit.go.jp/ksj/gml/dat…
マニュアル
nlftp.mlit.go.jp/ksj/manual/…

8
1,962


Kaggle Notebook の Embed 機能のお試し。KaggleのGPUを使ってゲーム実行してリプレイを Kaggle Notebook 上で可視化してブログに埋め込む。便利 ho.lc/blog/riichienv-release…
2
22
1,906

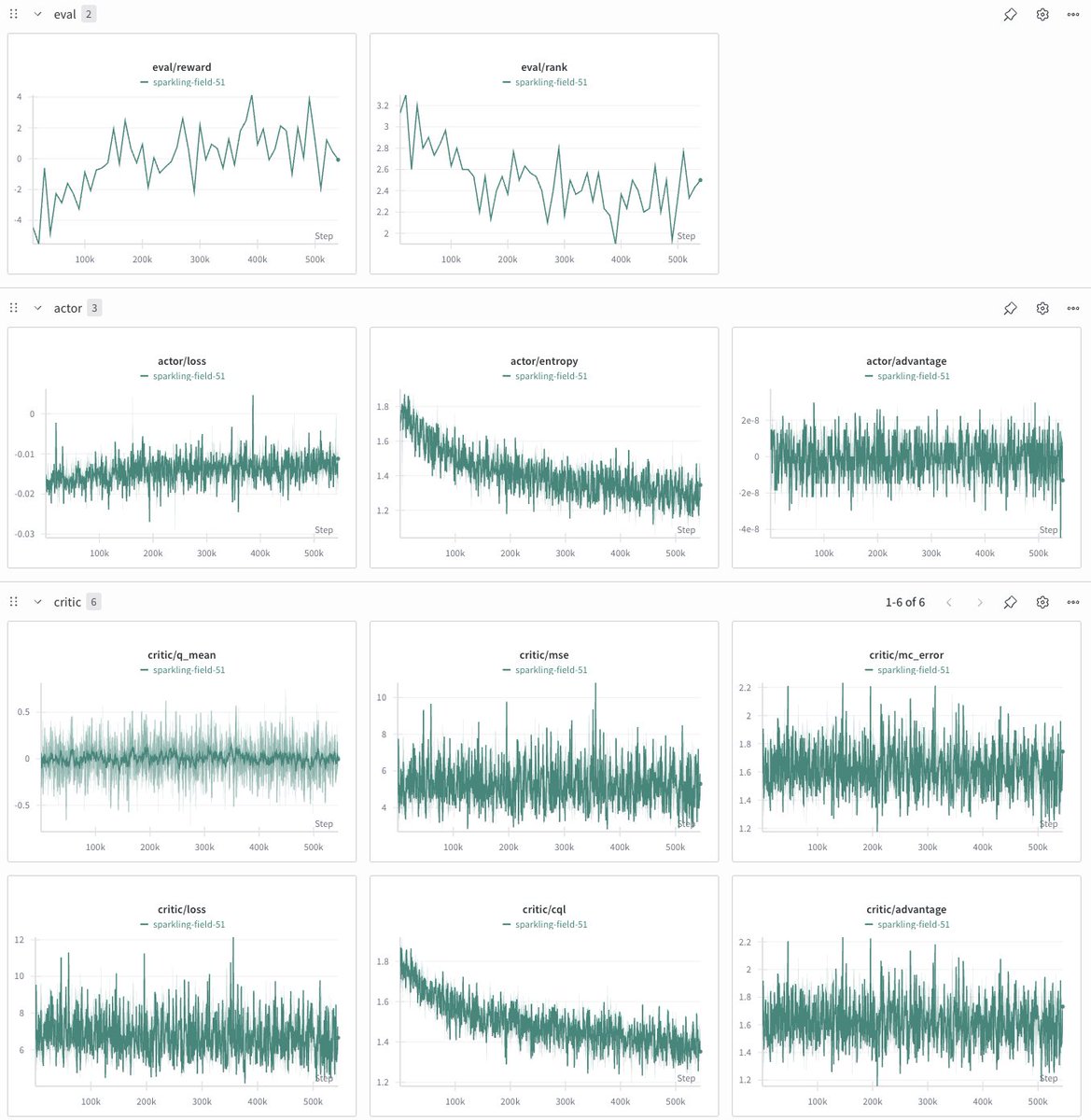
autoresearch is fascinating. For about a week I had an agent autonomously edit code, run training, monitor metrics, and iterate on Mahjong AI reinforcement learning.
It explored PPO hyperparameters, KL penalties, reward structures, opponent selection, and rolled back to stable checkpoints when metrics degraded.
Couldn't solve a fundamentally misaligned reward signal, but watching it map out the failure landscape was eye-opening.
24
2,502