
Investor by day, history buff & football fanatic by night. ⚽️ Debating life's big questions one philosophical tweet at a time.
Joined August 2021
- Tweets 1,451
- Following 196
- Followers 140
- Likes 526
376 Photos and videos






Jun 15
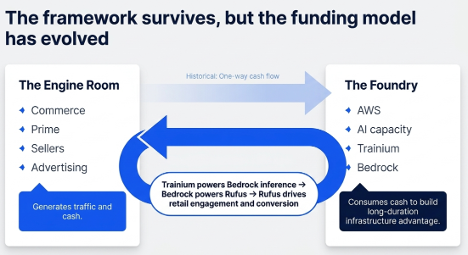
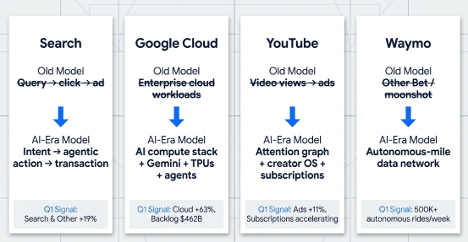
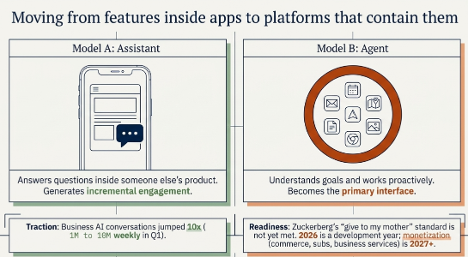
Why did CrowdStrike fall after a beat-and-raise?
Because consensus was not the bar.
Four quarters ago, I argued that CrowdStrike was not just a security software company, but a security data pipeline. Q1 made that thesis more interesting: AI agents and Mythos-style vulnerability discovery may turn Falcon into the control and remediation layer for AI-era enterprise risk.
But the stock had already started pricing that possibility.
That is the tension: the thesis is stronger than it was at $391, but the opportunity is harder at $659. The business is proving durability. The strategy is reaching for infrastructure status. The stock is priced for proof.
nikhs.substack.com/p/crowdst…
26
Jun 15
Broadcom’s quarter looked like a disappointment because the stock missed the AI whisper.
But I think the more interesting story is deeper: AI compute may be starting to move from a hyperscaler capex cycle to financeable infrastructure.
That changes how we should think about Broadcom.
This is not just a custom-chip story. It is about the industrial layer that turns financial capital, frontier lab demand, networking, silicon, optics, and supply-chain commitments into deployed AI capacity.
The thesis survived the quarter. The expectations premium did not.
nikhs.substack.com/p/broadco…
1
17
Jun 15
For most companies, belief follows proof.
For Musk companies, belief often arrives early and pays for the proof.
That was the strange mechanism behind Tesla. The stock did not merely reflect reality; at times, it helped create the reality it was supposed to discount.
SpaceX may now be asking public-market investors to underwrite the same loop again, but on a much larger, stranger canvas.
The obvious question is whether SpaceX is too expensive.
The more interesting question is what investors are paying for.
My latest piece argues that SpaceX’s real AI question is not whether Musk can win the chatbot race. It is whether he can build scarce physical compute capacity faster than everyone else.
Colossus may matter more than Grok.
But the updated piece also asks what could break the thesis: short-term compute contracts, accelerating cash burn, inherited xAI/X debt, declining Starlink ARPU, and Starship as a single point of failure for too many futures.
The key question is not Mars. It is not even Grok.
It is whether SpaceX can turn belief-funded capital into usable AI infrastructure before financial gravity returns.
That may be the only way to understand the valuation.
nikhs.substack.com/p/spacex-…
33
Nik_Maestro retweeted

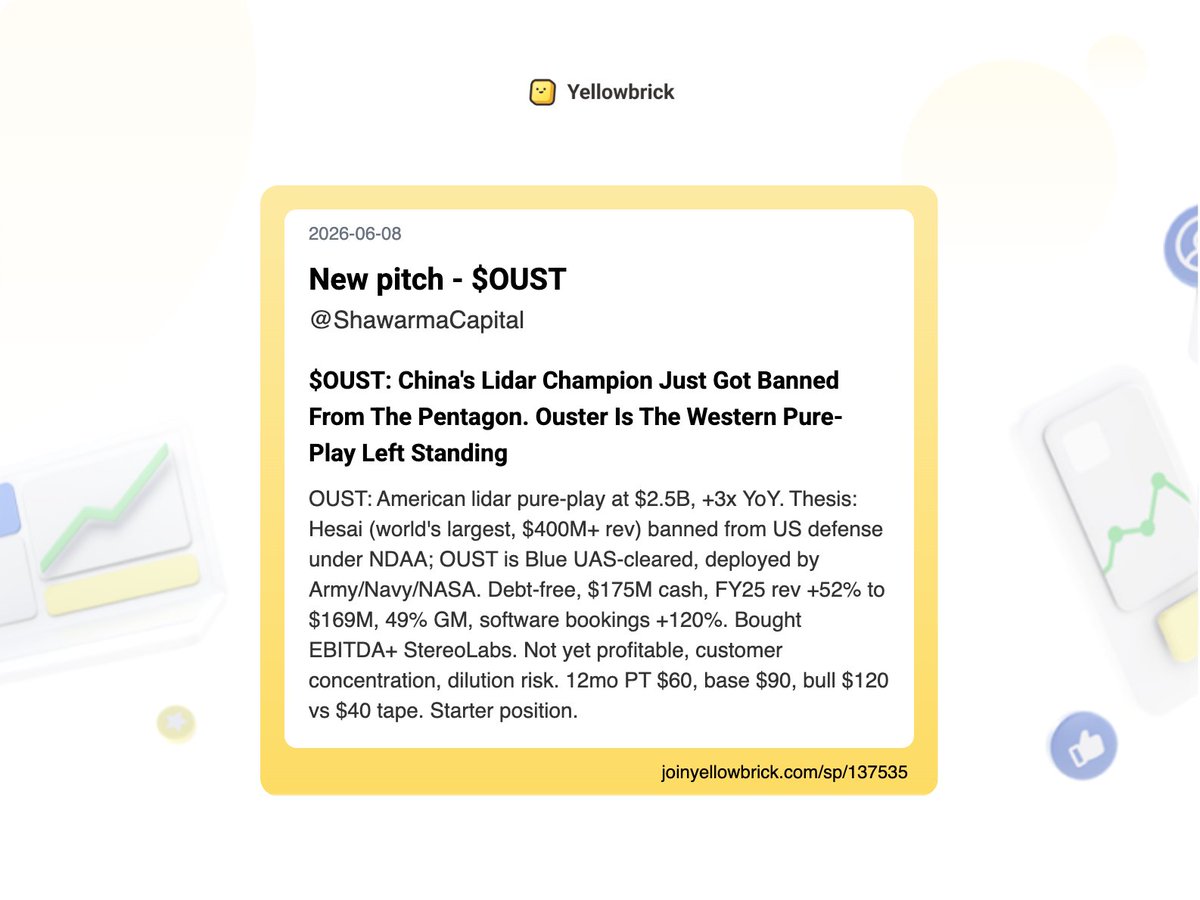
Added 65 new stock write-ups to the site (pt 3):
@AndrewRangeley (One Idea Per Day) - $PRSU, $FWRD
@FluentInQuality - $LLY
@HiddenGemsInves - $WOSG.L
@ShawarmaCapital - $OUST
@jakeallen3 - $KLAR
@snikhs2 - $AVGO (earnings)



2
1
7
2,026
Nik_Maestro retweeted

Jun 10
Taiwan’s semi supply chain is posting fantastic May revenue numbers. Very positive overall.
To recap a few:
King Slide — record high.
Unimicron — record high.
ASE — record high.
TSMC — record high.
Remember: the Taiwan ecosystem sits upstream of every CSP and data center.
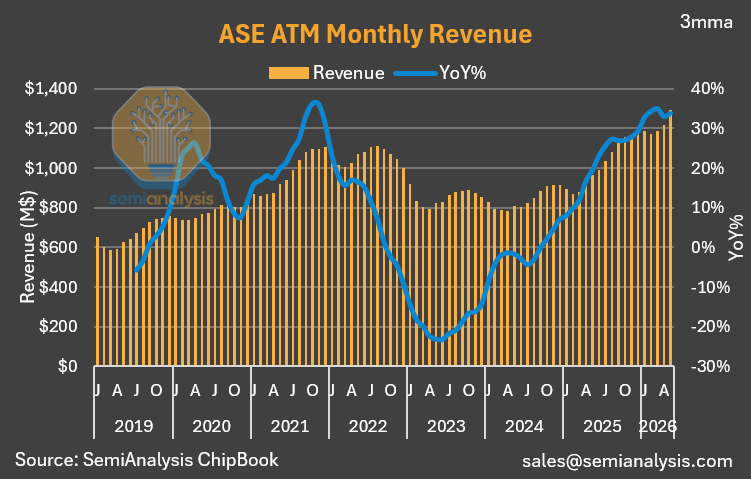

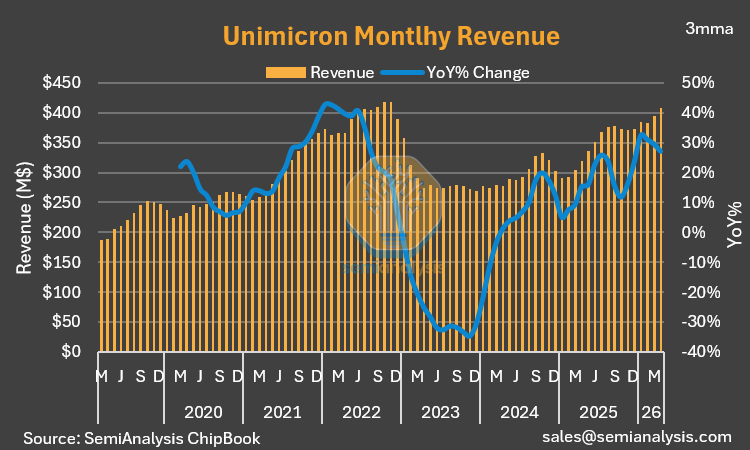
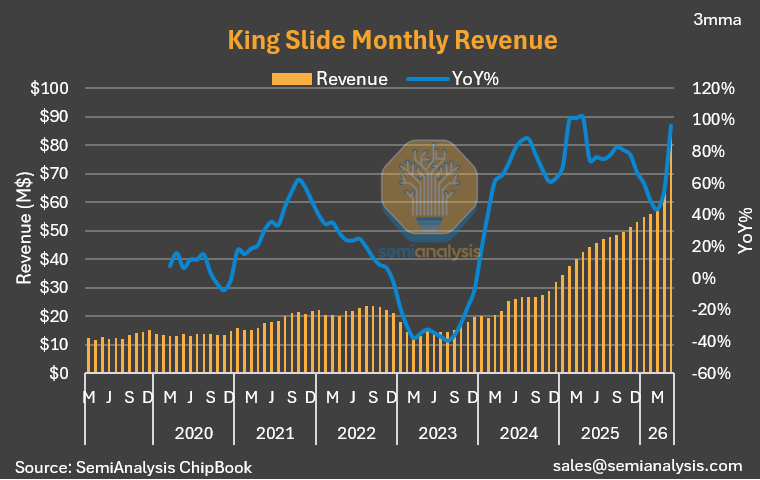
14
71
5,297
Nik_Maestro retweeted

May 28
The Apollo program. The fiber-optic backbone of the internet. The American railroad network.
All three were built by manias, moonshots, or bubbles that looked irrational in real time.
In their book "Boom: Bubbles and the End of Stagnation" (Stripe Press), Byrne Hobart and Tobias Huber argue this isn't a coincidence.
Some bubbles, what they call "inflection bubbles", are necessary to fund the kind of speculative technological leaps that rational ROI analysis would never touch.
Only collective mania puts in enough capital, and tolerates enough losses, to actually build the future.
The thesis matters now because we're in the middle of another one: AI capex. 🧵
1
1
3
85
May 21
NVIDIA’s Q1 wasn’t really about another beat.
It was about whether the company is moving from a demand story to a standardization story.
For the last year, I’ve argued that NVIDIA is not just selling GPUs: it is selling the infrastructure for generated software, reasoning workloads, and AI factories. This quarter added the missing metric: ACIE.
If ACIE keeps growing, NVIDIA is not merely a derivative of hyperscaler capex. It may be becoming the default architecture for intelligence production.
The key question is no longer: can NVIDIA sell more chips?
It is: does every new AI factory make the next NVIDIA deployment more likely?
That is the flywheel. And also the risk.
New article: NVIDIA and the Architecture of Intelligence
nikhs.substack.com/p/nvidia-…
14
May 20
The problem with quality investing during disruption:
The spreadsheet tells you how good the city was.
It does not tell you whether the route still runs through it.
Venice did not become incompetent. The trade route moved.
That is the question for AI, software, and every “cheap quality” stock today:
Is the moat still on the route?
Or has it become an island?
New essay: The Route Changes, a follow-up to The Quality Trap.
nikhs.substack.com/p/the-rou…
30
Nik_Maestro retweeted
May 20
Bonds are staging what John Authers called "a slow-motion car wreck."
30-year yields are at multi-decade highs across the developed world, simultaneously.
This isn't just an American story.
🇺🇸 US 30Y: highest since 2007
🇬🇧 UK 30Y: 28-year peak (also a Starmer leadership crisis)
🇯🇵 Japan 30Y: just touched 4.0%, first time since the tenor was created in 1999
When this many sovereigns sell off together, it's not a local issue. It's a global duration problem.

ALT Source: Bloomberg via DCB
1
2
84
Nik_Maestro retweeted
May 18
One of the largest US utility deals in history landed this morning: NextEra acquiring Dominion for $67B.
Five years ago, US utilities were retiring nuclear plants. Dominion was selling generation assets. Utilities were “value traps.”
NextEra just paid $67B to buy back the exact kind of infrastructure the industry was trying to shed.
Stranded yesterday. Strategic today.
AI rewrote the curve.
#nextera #markets
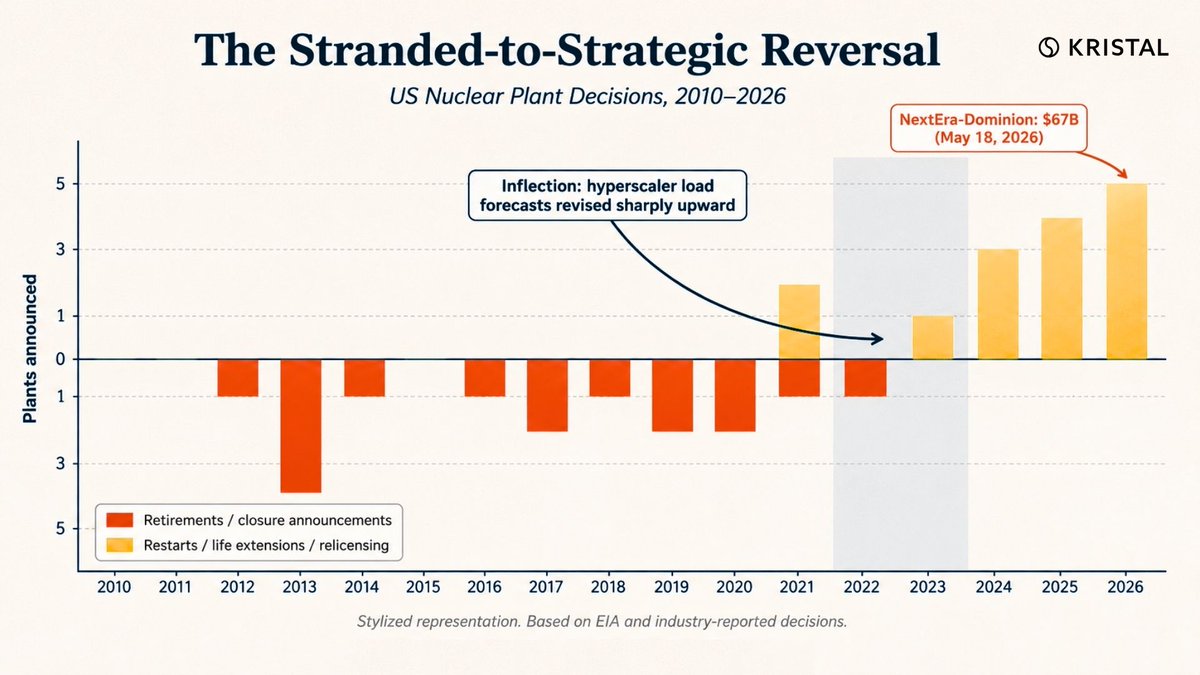
1
1
93
May 15
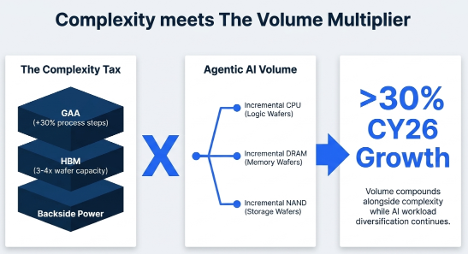
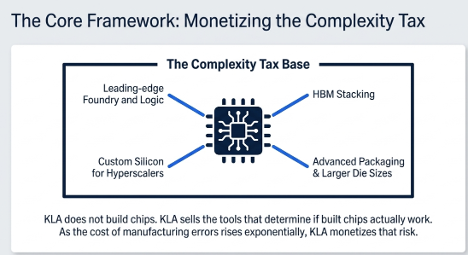
AMAT’s Q2 did not just beat numbers,it changed the question.
Our “complexity tax” thesis cleared its first real test: Semi Systems accelerated, margins held, DRAM stayed healthy, and management raised CY26 semi equipment growth from >20% to >30%.
But at $468, the easy money is gone.
The new debate: is Applied Materials still a cyclical WFE stock in a great AI cycle, or is it becoming a manufacturing-complexity compounder?
I wrote about why the framework has shifted from complexity tax to complexity × volume, and why cash flow is now the key test.
nikhs.substack.com/p/applied…
1
19
May 15
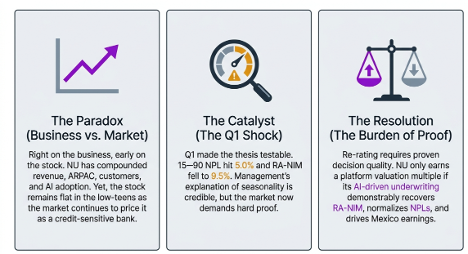
A year ago, the Nubank thesis was elegant: trust compounds into data, data improves decisions, and better decisions drive monetization.
One year later, the business has largely followed that script. The stock has not.
My Q1’26 update asks the uncomfortable question: are we early, or are we wrong?
The answer now depends less on revenue growth and more on whether NU’s AI/data loop shows up in credit outcomes: risk-adjusted NIM, NPL normalization, and Mexico earnings.
New piece: Nu Holdings 1Q26: The Decision Engine Meets the Credit Cycle
nikhs.substack.com/p/nu-hold…
1
1
57
May 13
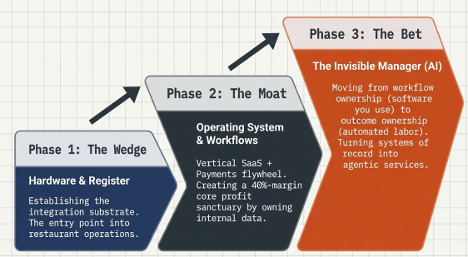
Toast had a good quarter. The stock fell anyway.
That tension is the piece.
The thesis held: Toast is more operating system than payments processor.
But the bar is higher now: Toast has to prove its AI layer can become paid work, not just useful software, while DoorDash pushes from demand into the register.
The register was the wedge.
The operating system was the moat.
The invisible manager is now the bet.
New article: Toast 1Q26: The Register, the Moat, and the Manager
nikhs.substack.com/p/toast-1…
52
Nik_Maestro retweeted
May 12
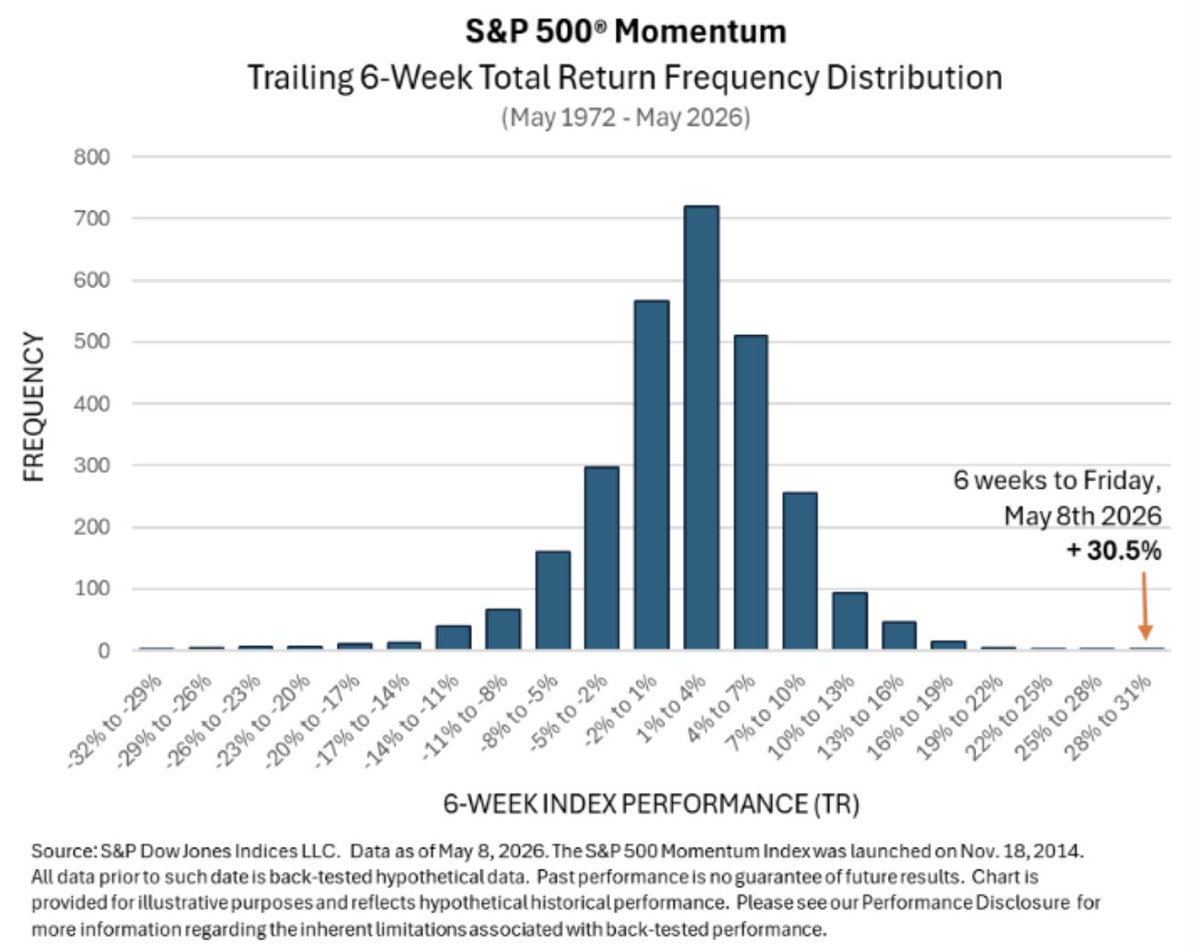
The S&P 500 Momentum Index just did something rare:
30.5% in 6 weeks.
Bigger than any live reading since launch in 2014.
Bigger than any back-tested reading going back to 1972.
Momentum didn’t just rebound it printed an outlier.
Now the question is whether that’s confirmation… or exhaustion.
#SP500 #Markets #Equities #Investing #Macro #MarketSignals
1
2
75
May 12
I’ve been positive on Adyen for a long time. The stock has gone the other way.
That is usually where the most useful investing lessons begin.
Q1 did not break the Adyen thesis. The single-platform architecture still looks special. Unified Commerce and Platforms are still growing well. Talon.One is a smart move upstream.
But the market has changed the question.
It is no longer asking: “Is Adyen a great payments company?”
It is asking: “Can Adyen become more than payments?”
That distinction matters. Because in today’s regime, elegant infrastructure is not enough. Investors want proof that the platform can monetize fraud, identity, money movement, embedded finance, loyalty, and offers; not just process more volume.
My latest piece is about why Adyen may still be a great company, but the stock now needs a different kind of proof.
nikhs.substack.com/p/adyen-1…
114
Nik_Maestro retweeted

May 7
Rene Haas just confirmed the Vera CPU thesis on yesterday’s Arm Q4 call. He didn’t mean to
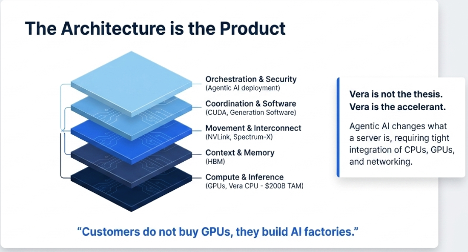
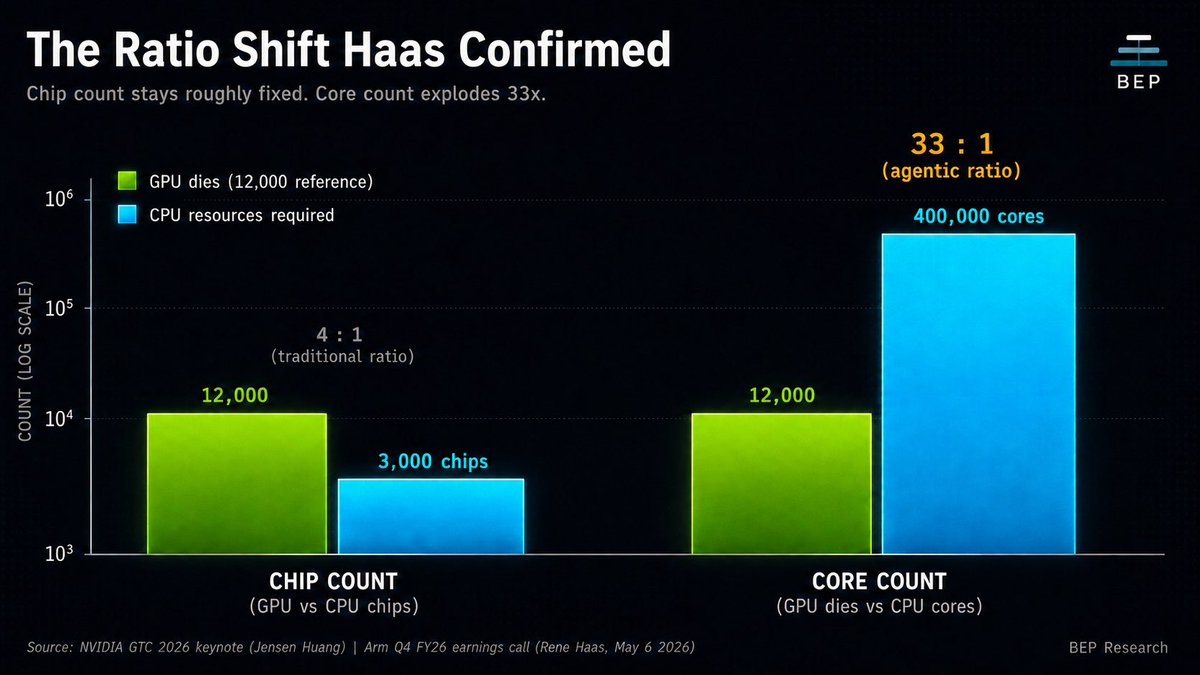
His framing: GPUs are reticle-limited. CPUs are not. The ratio shift is happening in core count, not chip count
His exact words: “256 Vera CPU chips, 88 cores per chip, a 200-kilowatt liquid-cooled rack designed to sit in a data center adjacent to a Vera Rubin system”
That is not a host CPU. That is a dedicated agentic orchestration
Two days ago NVIDIA’s own engineers published the receipt. They traced a real 33-minute Claude Code session:
283 inference requests
58 main-agent turns coordinating 225 sub-agent invocations
Context grew from 15K to 156K tokens before compaction dropped it to 20K
Main agent alone processed ~3.5 million input tokens in the first 40 turns
Anthropic’s own number: agentic systems consume up to 15x more tokens than chat. Coding agents sustain 95 to 98 percent prompt cache hit rates. Without caching, costs would be 6x higher
This is what’s happening between GPU calls. File reads. Tool invocations. Sub-agent spawns. Compaction. KV cache management. None of it runs on the GPU
That’s why 12,000 GPUs need 400,000 CPU cores. The 33-to-1 ratio isn’t a forecast. It’s a measurement
NVIDIA states it in the blog directly: this won’t be resolved by adding more compute FLOPs and memory capacity
Translation: the GPU-only path is exhausted. The agentic chapter requires a platform, not a chip
Their seven-chip answer:
Vera Rubin NVL72 —capacity and prefill
Vera CPU — tool execution, KV cache offload
Groq 3 LPX — SRAM-first decode, low-jitter generation
NVLink 6, ConnectX-9, BlueField-4, Spectrum-X — fabric
Result they claim: 400 tokens per second per user on trillion-parameter MoE at 400K context. Vera spec: 88 Olympus cores, 176 threads, 1.8 TB/s NVLink-C2C, 1.2 TB/s LPDDR5X, 227 billion transistors. A 256-CPU rack delivers 45,056 threads and 400 TB of memory
One detail nobody is talking about. The blog’s second author was previously Head of Agents at Groq. The third was previously at @GroqInc and Intel. NVIDIA didn’t license the LPX architecture. They absorbed the team that built it
Haas isn’t pitching a competing thesis. He’s confirming this one from the other side of the table. Arm data center royalties doubled year-on-year. He expects them to double again
Things feel slow right now because we’re between platforms. The speedup ships in H2 2026. The architectural argument is over. Deployment is the only variable left
I cover this in The Quiet Architect and The Fourth Piece
$arm $NVDA


26
49
363
62,794
May 8
MercadoLibre 1Q26 and the Cost of Being Right
The commerce thesis worked. The stock did not. Q1 explains why.
TLDR:
· Commerce worked; the stock didn’t. Brazil volume accelerated and unit shipping costs fell, but the market wants proof of returns, not just growth.
· Margins are not fully discretionary. MELI can “set the dial,” but Shopee, Temu, Amazon, TikTok, and Nubank increasingly set the floor.
· The thesis is now conditional. MELI remains a great business, but the stock depends on who captures the surplus: MELI, customers, sellers, or credit losses.
nikhs.substack.com/p/mercado…
17
May 8
ARM’s 4QFY26 Earnings: AI Upside, Platform Risk
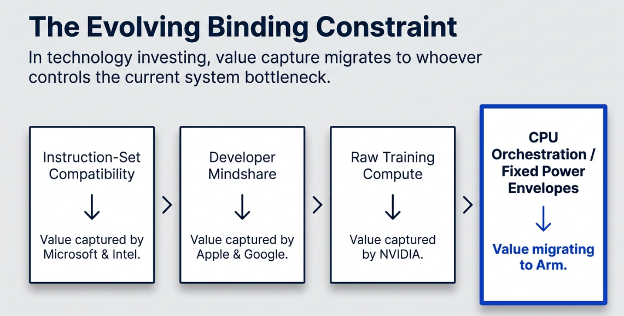
Arm’s AGI CPU strategy is not just a response to agentic AI demand. It is Rene Haas’s deliberate trade of neutrality for value capture, and the next three years will decide whether Arm becomes the CPU platform owner or compromises the franchise that made it indispensable.
TL;DR
•Agentic AI makes Arm’s architecture structurally more valuable because CPU orchestration inside fixed power envelopes becomes a binding constraint, and x86 looks increasingly disadvantaged.
•But Arm’s AGI CPU strategy breaks the neutrality that made the platform powerful, turning Arm from Switzerland into a potential competitor to its largest licensees.
•At $253, the stock prices in too much of the “Platform Owner” outcome, while underweighting the risk that licensees hedge, RISC-V gains traction, and Arm’s platform premium erodes.
nikhs.substack.com/p/arms-4q…
22
May 5
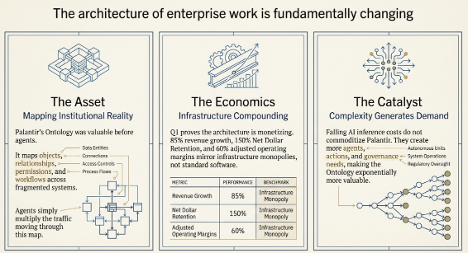
Palantir’s Q1 was extraordinary, but the numbers are the cherry on top.
The real story is that the Ontology may be moving from wiring enterprise software together to replacing parts of the old architecture altogether.
In the AI era, the most valuable layer may not be the model. It may be the map of reality the model acts on.
nikhs.substack.com/p/palanti…
21
May 4
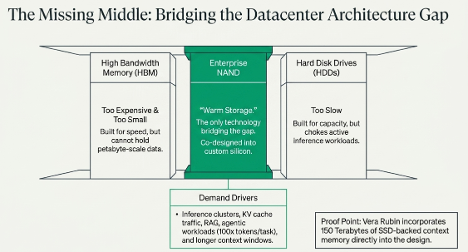
SanDisk is the strangest kind of investing problem: the thesis worked almost too well.
When I first wrote it up, the idea was simple: AI infrastructure had a missing middle between HBM and hard drives. Enterprise NAND would become the warm-storage layer for inference, KV cache, RAG, long context windows, and agentic workloads.
That part is now validated.
The stock has gone from my original $244 initiation to $1,127. Datacenter is now 25% of revenue. Gross margins just printed near 80%. SanDisk is no longer fighting for orders; it is choosing customers.
But the harder question starts now.
Is this just the greatest NAND upcycle in history, or are SanDisk’s new multi-year contracts turning part of a commodity cycle into durable earnings power?
My latest update is less of a victory lap and more of a framework reset: the demand debate is over. The real debate is the EPS floor.
nikhs.substack.com/p/sandisk…
1
51