
Joined May 2010
- Tweets 662
- Following 759
- Followers 335
- Likes 2,172
22 Photos and videos








Pinned Tweet

28 Jan 2025
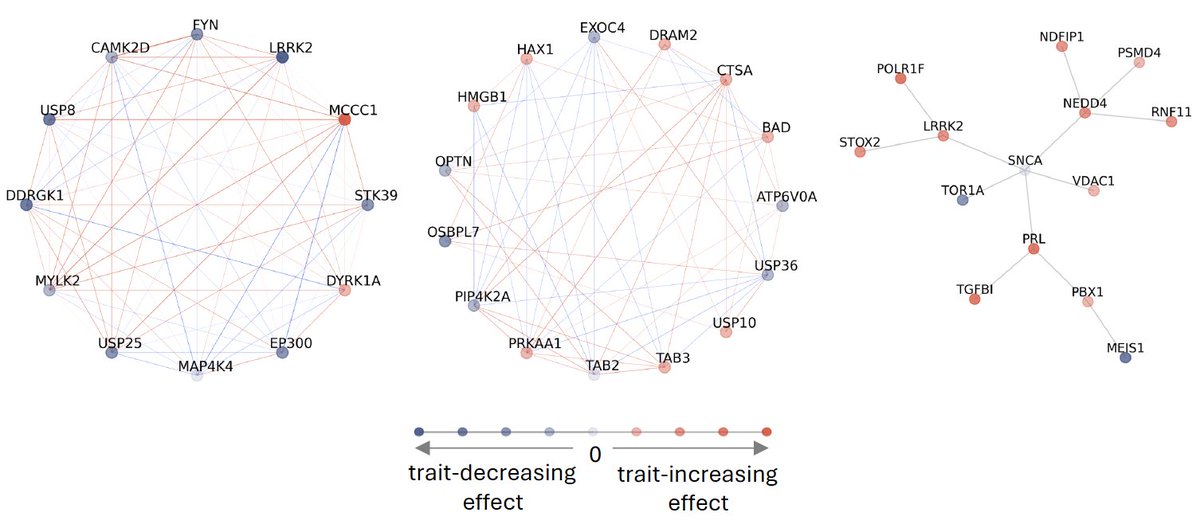
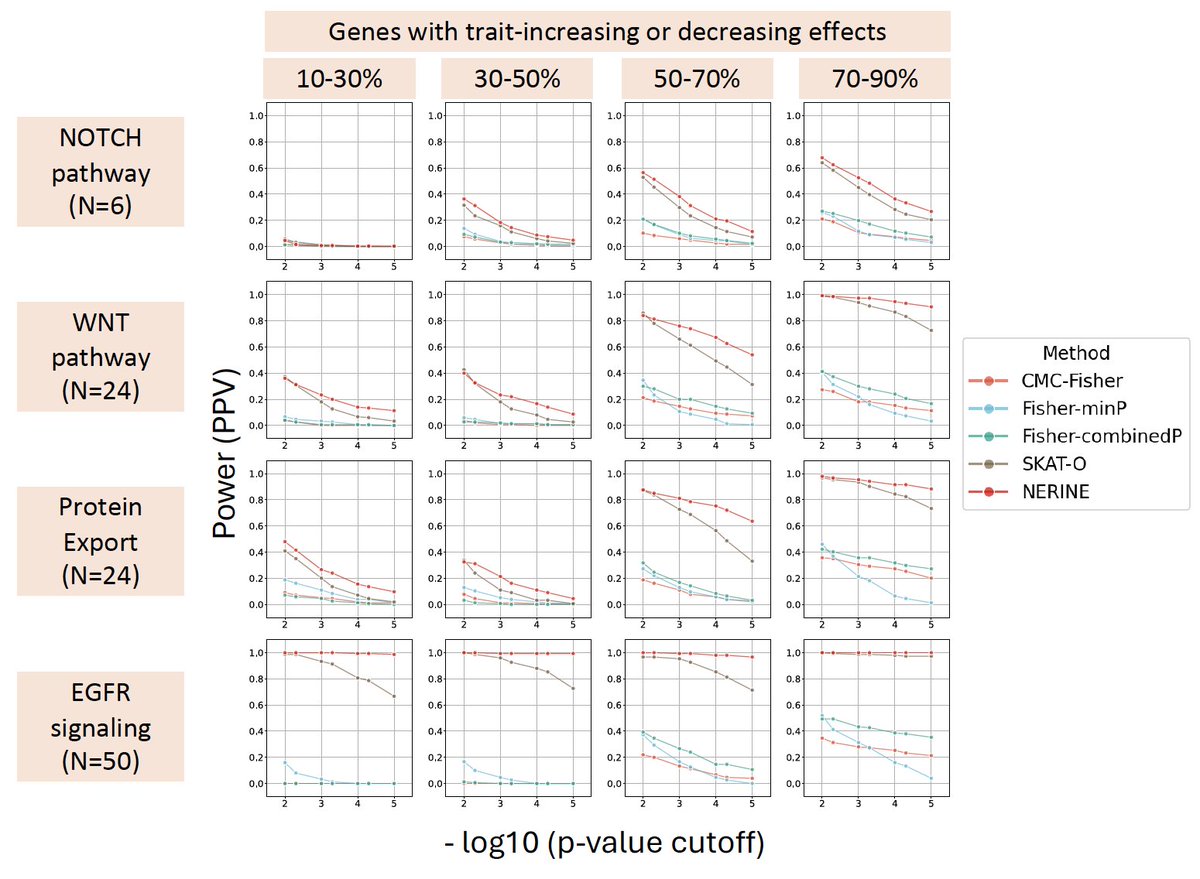
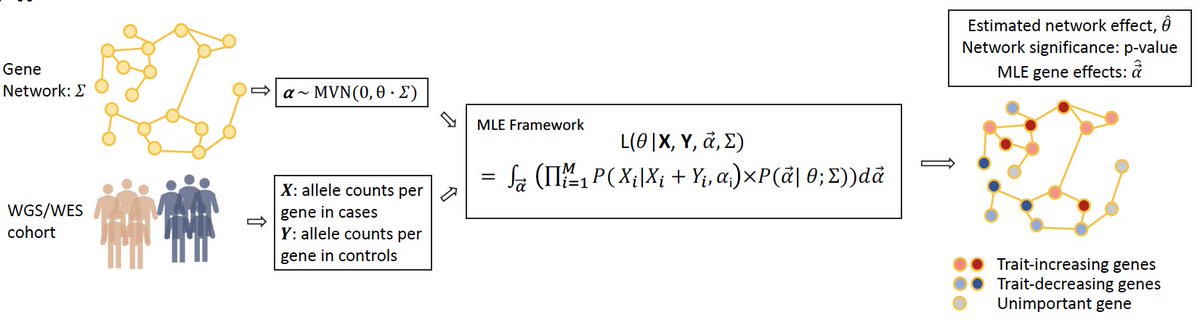
Excited to share our new network-based rare variant association test, NERINE. If you have a gene-module and want to know how the module affects the trait as well as what the role of each individual gene is, give our method a try! #genetics #stats #BRCA #MI #CAD #Parkinson
10 Jan 2025

NERINE reveals rare variant associations in gene networks across multiple phenotypes and implicates an SNCA-PRL-LRRK2 subnetwork in ... biorxiv.org/cgi/content/shor… #biorxiv_genetic
1
1
7
362
Sumaiya Nazeen retweeted

Feb 3
AI hallucinations in science manuscripts are a nuisance. Paranormal citations, or paracites, will be a nightmare.
biorxiv.org/content/10.64898… (w/ @sinabooeshaghi & @NeuroLuebbert).

5
20
93
19,776
Sumaiya Nazeen retweeted
26 Nov 2025
Omg this is brilliant.
25 Nov 2025

I love this list of favorite academic flexes... so I made it into a song to the tune of My Favorite Things from The Sound of Music 😂
My Favorite Things (Academic Edition) 🎶: youtube.com/shorts/v9qQvznDu…
(Is there a good tune to go with the list of things we dislike? Let me know!)

8
61
13,364
Sumaiya Nazeen retweeted

23 Oct 2025
TF-MAPS: fast high-resolution functional and allosteric mapping of DNA-binding proteins by @XianghuaLi2
Are Transcription Factors really 'undruggable'?
biorxiv.org/content/10.1101/…
1
17
66
6,913
Sumaiya Nazeen retweeted

25 Aug 2025
fascinating new paper on RNA-seq analysis from living human brain tissue, which differs from results found in preserved/autopsied samples nature.com/articles/s41380-0…
3
37
111
13,906
Sumaiya Nazeen retweeted

20 Oct 2025
This might be the most disturbing AI paper of 2025 ☠️
Scientists just proved that large language models can literally rot their own brains the same way humans get brain rot from scrolling junk content online.
They fed models months of viral Twitter data short, high-engagement posts and watched their cognition collapse:
- Reasoning fell by 23%
- Long-context memory dropped 30%
- Personality tests showed spikes in narcissism & psychopathy
And get this even after retraining on clean, high-quality data, the damage didn’t fully heal.
The representational “rot” persisted.
It’s not just bad data → bad output.
It’s bad data → permanent cognitive drift.
The AI equivalent of doomscrolling is real. And it’s already happening.
Full study: llm-brain-rot. github. io

629
5,472
28,443
2,809,742
Sumaiya Nazeen retweeted

18 Oct 2025
Calling on all scientists to call out hype, grift & BS when u see it. If u don't, u risk anti-science grifters leveraging overhyped & underdelivered promises & shoddy science to destroy public trust in the enterprise. Keep science & science comm grounded & truthful.
18
38
406
56,869
Sumaiya Nazeen retweeted

19 Oct 2025
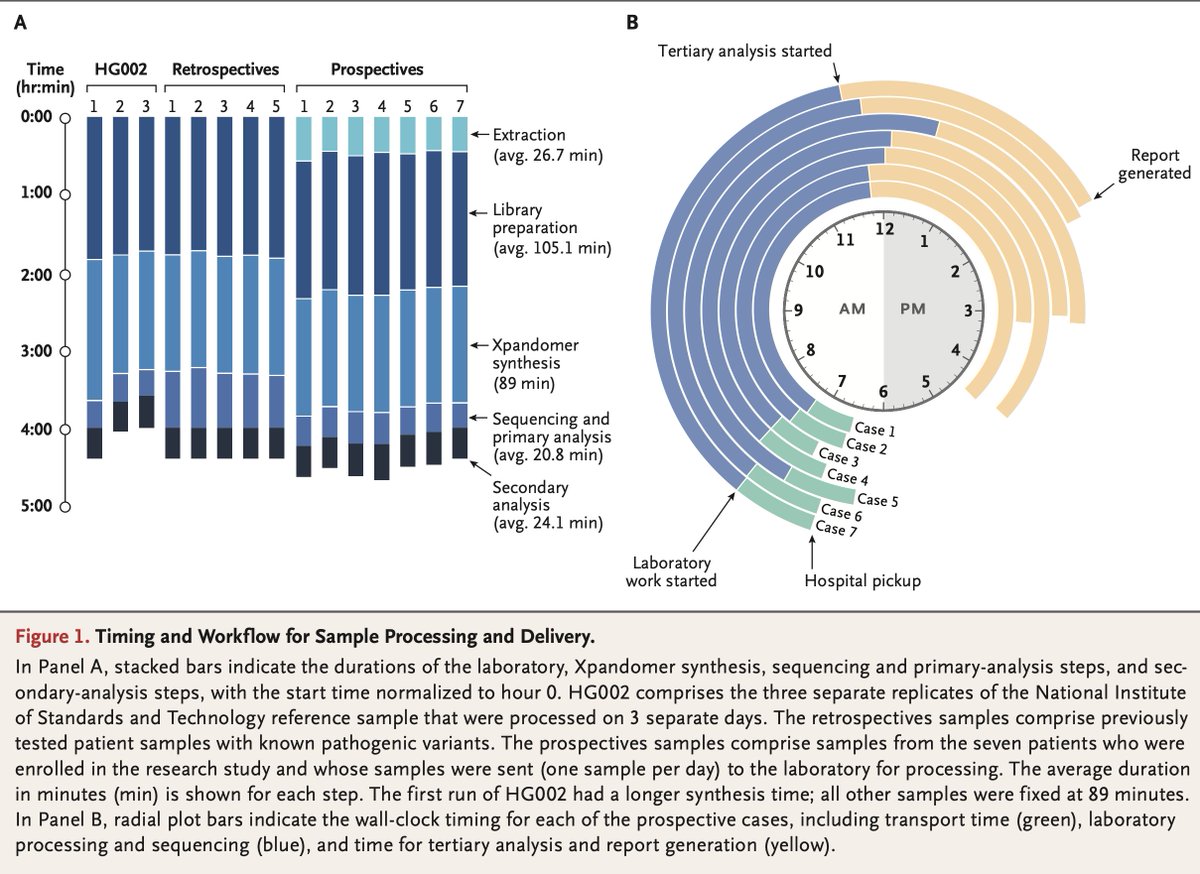
Congrats to Broad Clinical Labs, Roche and Boston Children's Hospital for making a Guinness record for fastest genome sequencing! They were able to sequence and analyse the whole genome in <4 hrs, surpassing the previous benchmark of 5 hrs and 2 mins.
A NEJM paper reports application of this rapid workflow in seven NICU patients that returns genetic diagnosis in < 8 hrs. Amazing!
News:
broadclinicallabs.org/broad-…
NEJM paper:
nejm.org/doi/full/10.1056/NE…
3
77
358
29,521
20 Oct 2025
Check out the latest preprint from @J_E_Mitchel on a new single-cell genetic colocalization tool, scJLIM, which shows significant power gain over bulk colocalization. It has been a pleasure being part of the effort!
16 Oct 2025

Super excited that my paper describing the scJLIM single-cell genetic colocalization tool is finally out on bioRxiv! scJLIM enables you to identify the specific cell states where GWAS genetic variants impact gene expression. Check it out! biorxiv.org/content/10.1101/…
1
1
190


Sumaiya Nazeen retweeted

8 Aug 2025
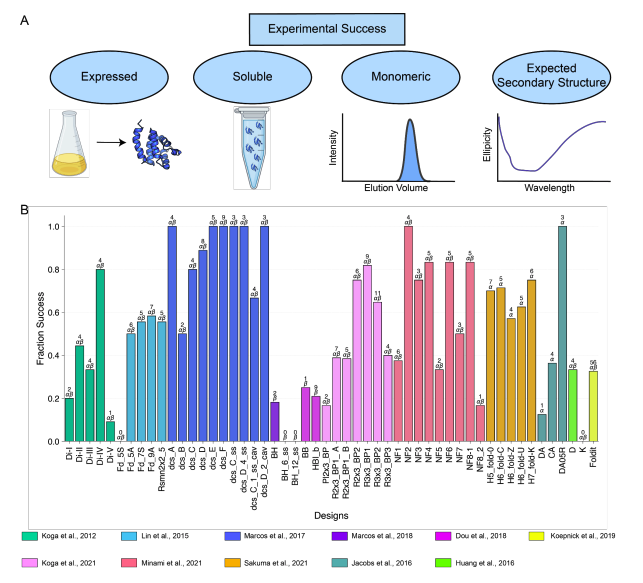
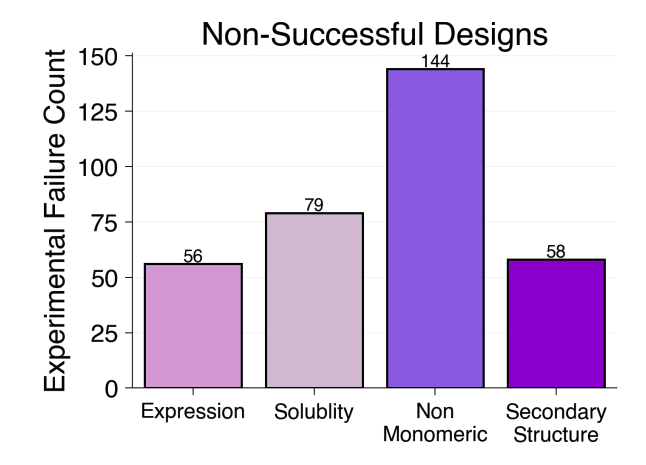
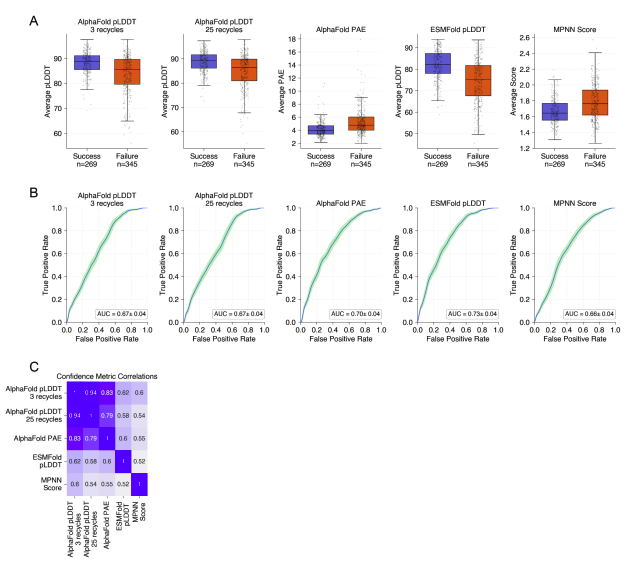
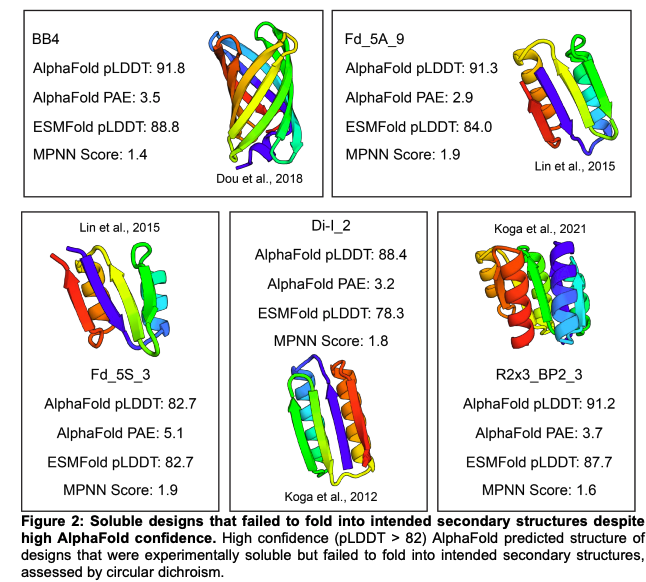
A benchmark dataset of 614 experimentally characterized de novo designed monomers from 11 different design studies shows that:
- deep learning structural metrics only weakly predict success
- The score distribution is different for different types of structures
@grocklin
3
18
117
10,599
Sumaiya Nazeen retweeted

7 Aug 2025
New preprint on a surprising question - with a pangenome reference, *what is a genetic variant?*
biorxiv.org/content/10.1101/…
With Pouria Salehi Nowbandani, Shenghan Zhang, Haoyang Hu, and Heng Li @lh3lh3
2
54
214
35,462
Sumaiya Nazeen retweeted

31 Jan 2025
DeepSeek [1] uses elements of the 2015 reinforcement learning prompt engineer [2] and its 2018 refinement [3] which collapses the RL machine and world model of [2] into a single net through the neural net distillation procedure of 1991 [4]: a distilled chain of thought system.
REFERENCES (easy to find on the web):
[1] #DeepSeekR1 (2025): Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arXiv 2501.12948
[2] J. Schmidhuber (JS, 2015). On Learning to Think: Algorithmic Information Theory for Novel Combinations of Reinforcement Learning Controllers and Recurrent Neural World Models. arXiv 1210.0118. Sec. 5.3 describes the reinforcement learning (RL) prompt engineer which learns to actively and iteratively query its model for abstract reasoning and planning and decision making.
[3] JS (2018). One Big Net For Everything. arXiv 1802.08864. See also US11853886B2. This paper collapses the reinforcement learner and the world model of [2] (e.g., a foundation model) into a single network, using the neural network distillation procedure of 1991 [4]. Essentially what's now called an RL "Chain of Thought" system, where subsequent improvements are continually distilled into a single net. See also [5].
[4] JS (1991). Learning complex, extended sequences using the principle of history compression. Neural Computation, 4(2):234-242, 1992. Based on TR FKI-148-91, TUM, 1991. First working deep learner based on a deep recurrent neural net hierarchy (with different self-organising time scales), overcoming the vanishing gradient problem through unsupervised pre-training (the P in CHatGPT) and predictive coding. Also: compressing or distilling a teacher net (the chunker) into a student net (the automatizer) that does not forget its old skills - such approaches are now widely used. See also [6].
[5] JS (AI Blog, 2020). 30-year anniversary of planning & reinforcement learning with recurrent world models and artificial curiosity (1990, introducing high-dimensional reward signals and the GAN principle). Contains summaries of [2][3] above.
[6] JS (AI Blog, 2021). 30-year anniversary: First very deep learning with unsupervised pre-training (1991) [4]. Unsupervised hierarchical predictive coding finds compact internal representations of sequential data to facilitate downstream learning. The hierarchy can be distilled [4] into a single deep neural network. 1993: solving problems of depth >1000.

278
884
4,731
847,549
28 Jan 2025
Ever wondered about #prolactin's role in #Parkinsonsdisease? Does #prolactin interact with #alphasynuclein? Check out our latest preprint: biorxiv.org/content/10.1101/…
- with @XinyuanWang_BWH
1
61
28 Jan 2025
Excited to share our new network-based rare variant association test, NERINE. If you have a gene-module and want to know how the module affects the trait as well as what the role of each individual gene is, give our method a try! #genetics #stats #BRCA #MI #CAD #Parkinson
10 Jan 2025
NERINE reveals rare variant associations in gene networks across multiple phenotypes and implicates an SNCA-PRL-LRRK2 subnetwork in ... biorxiv.org/cgi/content/shor… #biorxiv_genetic
1
1
7
362
28 Jan 2025
5/ NERINE’s results converge with CRISPRi screening in neurons on PRL, revealing an association of rare damaging missense variants with PD risk. Targeted follow-up experiments identify a remarkable intraneuronal prolactin/αS stress response in PD.
1
48
28 Jan 2025
Grateful for the mentorship from Prof. Shamil Sunyaev and Prof. Vikram Khurana @khurana_lab and my excellent set of collaborators @XinyuanWang_BWH, Autumn, Ronya, Liz, Dylan, Alex, Jalwa, Nate, Raj, and Kelvin.
49