
13 Photos and videos







solbier retweeted

Congratulations @goodwin_ml and team @fractile_ai!
This $220m raise is proof of exceptional British AI bringing investment and jobs to the UK.
Britain has a deep heritage in semiconductors - and we are now renewing it for the age of AI inference 🇬🇧
wsj.com/tech/ai/chips-startu…

2
10
80
4,681

We’re thrilled to be backing @fractile_ai , solving inference at the edge of what’s possible.
The current AI trend around infra and memory is deeply personal to me. A decade ago, I was part of a small team at Cruise pushing silicon to its limit. We were running perception and planning models on NVIDIA Titan with only 6GB of RAM & 2k CUDA cores.
The chips were on-device, power-constrained, thermally limited. The car's air conditioning wasn't designed to dissipate that much heat so we had to engineer custom cooling. Everything was duct tape and ingenuity. It gave me a deep appreciation for doing more with less, and for founders like @goodwin_ml at Fractile who operate the same way.
If you're the type who stares at the limits of physics and sees a challenge - reach out !
May 13

Exclusive: The U.K. chip startup Fractile said it has raised a $220 million Series B funding round led by Factorial Funds, Accel and Peter Thiel’s Founders Fund on.wsj.com/4nseSGS
3
8
71
77,561
solbier retweeted

Apr 30
That change you’re feeling? Like the old way of pricing and modeling entire industries is being turned on its head? It’s been slowly compounding for a while now. When you look at the IGV/SMH ratio (tracking the relative performance of software against semiconductors) you see that this rotation out of software into chips isn’t new. It’s just accelerating.

5
11
1,695
Incredible work @karinanguyen . We can't manage what we can't measure - PostTrainBench is a huge win for the frontier !
Mar 11

Excited to release PostTrainBench v1.0!
This benchmark evaluates the ability of frontier AI agents to post-train language models in a simplified setting.
We believe this is a first step toward tracking progress in recursive self-improvement 🧵:
1
6
604
Ethan (from Khosla, the true believers in AI before any VC would even take a meeting) posting some incredible insights:
"Hyperscalers which were able to build out incrementally as internet penetration and cloud adoption grew ! " This AI capex cycle is happening much faster.
Jan 26

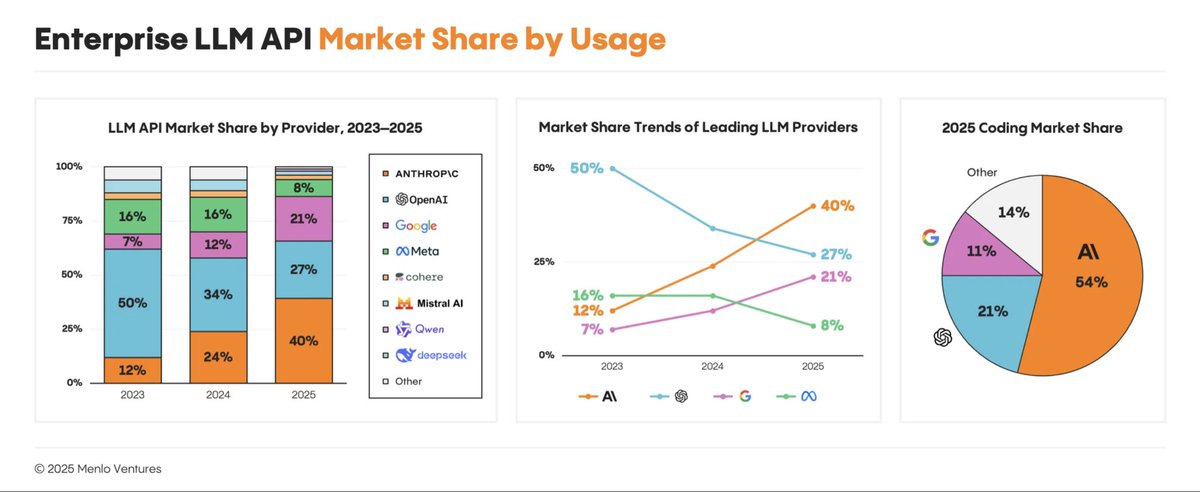
For anyone who finally want VCs called out on their BS, can I get enough likes and retweets on this for folks who would like @mmurph @deedydas @MenloVentures to be transparent and share the underlying N, firmographic data, and methodology that underpins this study?
1
11
4,919

Congrats @AravSrinivas & the entire @perplexity_ai team on the Comet launch. This level of context with LLMs feels the iPhone moment for AI all over again 🚀
4
34
2,586
Congrats on the launch @nicochristie & team. Time to get your team more GPUs 🫡
2 Jul 2025

Introducing Shortcut — the first superhuman Excel agent.
Shortcut one-shots most knowledge work tasks on Excel.
It even scores >80% on Excel World Championship Cases in ~10 minutes. That's 10x faster than humans.
Our early preview is live. Just comment for an invite code.
1
2
1,603
👀
7 May 2025

*ALPHABET SINKS 5% AS APPLE EXPLORES AI SEARCH IN ITS BROWSER
*APPLE'S CUE: SEARCHES IN BROWSER FELL FOR FIRST TIME IN APRIL
*APPLE'S CUE: BELIEVES PERPLEXITY, ANTHROPIC COULD BE OPTIONS
1
533
When your own portfolio company turns the VC industry into a commodity. How the tables have turned. Great job @perplexity_ai team !

1
5
1,058
solbier retweeted

14 Jan 2025
We're excited to introduce Tasks! For the first time, ChatGPT can manage tasks asynchronously on your behalf—whether it's a one-time request or an ongoing routine. Here are my favorite use cases:
1/ ChatGPT checks stock price every morning!
427
1,094
12,218
2,498,571
New evals are badly needed for next gen LLMs !
30 Oct 2024
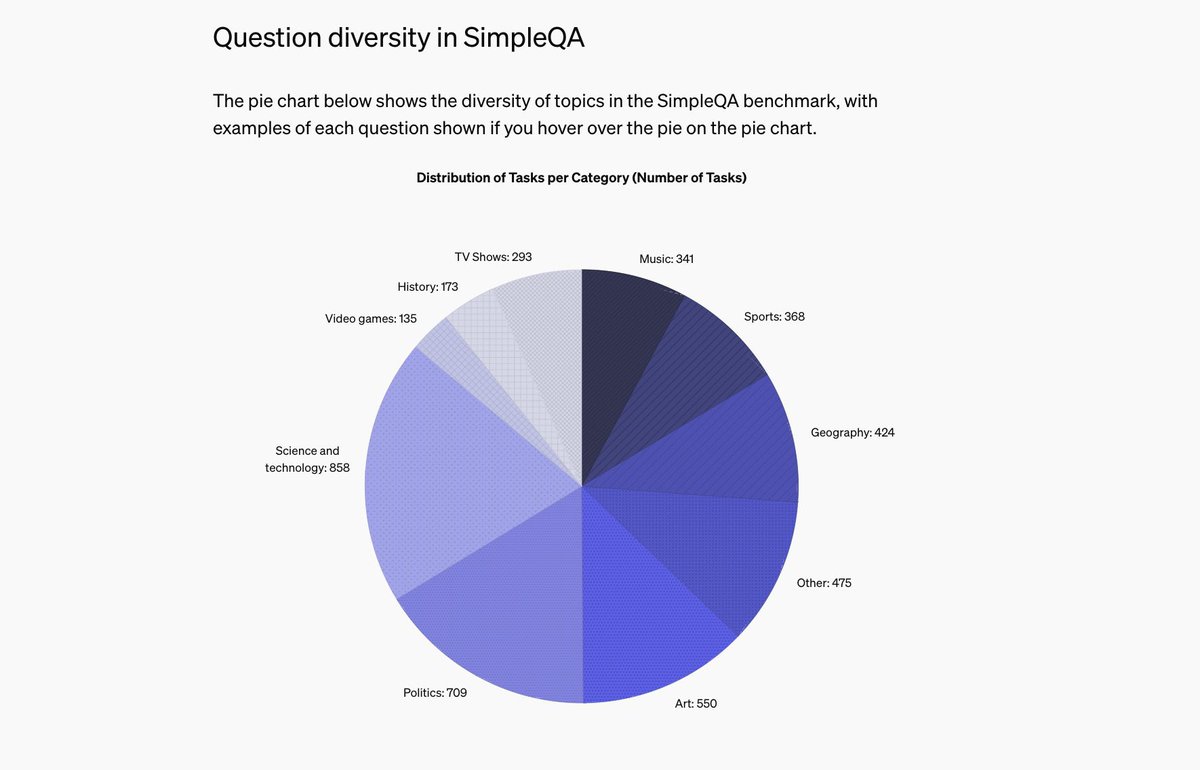
New paper! SimpleQA is newly open-sourced factuality benchmark that contains 4,326 short, fact-seeking questions that are challenging for frontier models.
Designing good evals is hard. But we used the following criteria:
- High correctness via robust data quality verification / human agreement rates.
- Good researcher UX. Easy to grade, easy to run.
- Challenging for frontier models. GPT-4o and Claude both score less than 50%
- Diversity. SimpleQA contains questions from a wide range of topics, including history, science & technology, art, geography, TV shows, etc.

2
580
Thanks for having us @RagingVentures , all the panels at the event were great !
26 Oct 2024

Excited to share excerpts from my chat with Sol Bier at our recent NYC Conference. Sol was an early engineer at Cruise & is the founding partner of Factorial Funds, an AI-focused VC fund. The full interview is available here: ragingcapitalventures.com/ai…
A few highlights: 1/4
1
608
solbier retweeted

26 Oct 2024
Excited to share excerpts from my chat with Sol Bier at our recent NYC Conference. Sol was an early engineer at Cruise & is the founding partner of Factorial Funds, an AI-focused VC fund. The full interview is available here: ragingcapitalventures.com/ai…
A few highlights: 1/4
1
2
17
18,864
solbier retweeted
6 Sep 2024
I can’t wait to discuss the latest and greatest in AI and venture with Factorial Fund’s Sol Bier @solbier1 at our upcoming Ideas & Networking Conference in NYC on Thurs Sept 19th. Sol was an early founding engineer at Cruise as well as an early investor in Perplexity and Anthropic. He is also an investor in SpaceX. Click here for a full list of speakers and to register: ragingcapitalventures.regfox…
2
1
7
6,359

💪

🤩 We had a great time joining forces with @factorialfunds to bring together a stellar group of our portfolio founders for ‘Founder Day’ at @AnthropicAI.
Founders were treated to an inside look at Anthropic’s product roadmap, best practices for builders using the company’s API and other #AI products—and even a Boba tea bar! 🧋
🙌🏼 Thanks to the Factorial and Anthropic teams for being awesome partners! #AI #GenAI #founders #startups



4
504
Huge thank you to @joandthezhus @jneuwirth4 & the entire Anthropic startup team
15 Aug 2024

@factorialfunds and @NEA co-hosted an incredible Founder Day at @AnthropicAI, where portfolio companies joined to hear from co-founder @DanielaAmodei and CPO @mikeyk. @AnthropicAI presented some incredible insights into their product roadmap.




2
7
648
solbier retweeted

7 Aug 2024
Founders have been busy cooking this summer in SF
Thank you @AnthropicAI for bringing our founders along with your exciting roadmap and mastering PMF with your boba bar :)
@DanielaAmodei @mikeyk @joandthezhus @solbier1 @factorialfunds @jamesekaplan @NEA @btp4z7 @james_elicit @shravan2x @tiimparis @angli_ai




2
9
800