
The new paradigm of solid-state storage.
Joined July 2021
- Tweets 1,200
- Following 95
- Followers 5,371
- Likes 452
518 Photos and videos

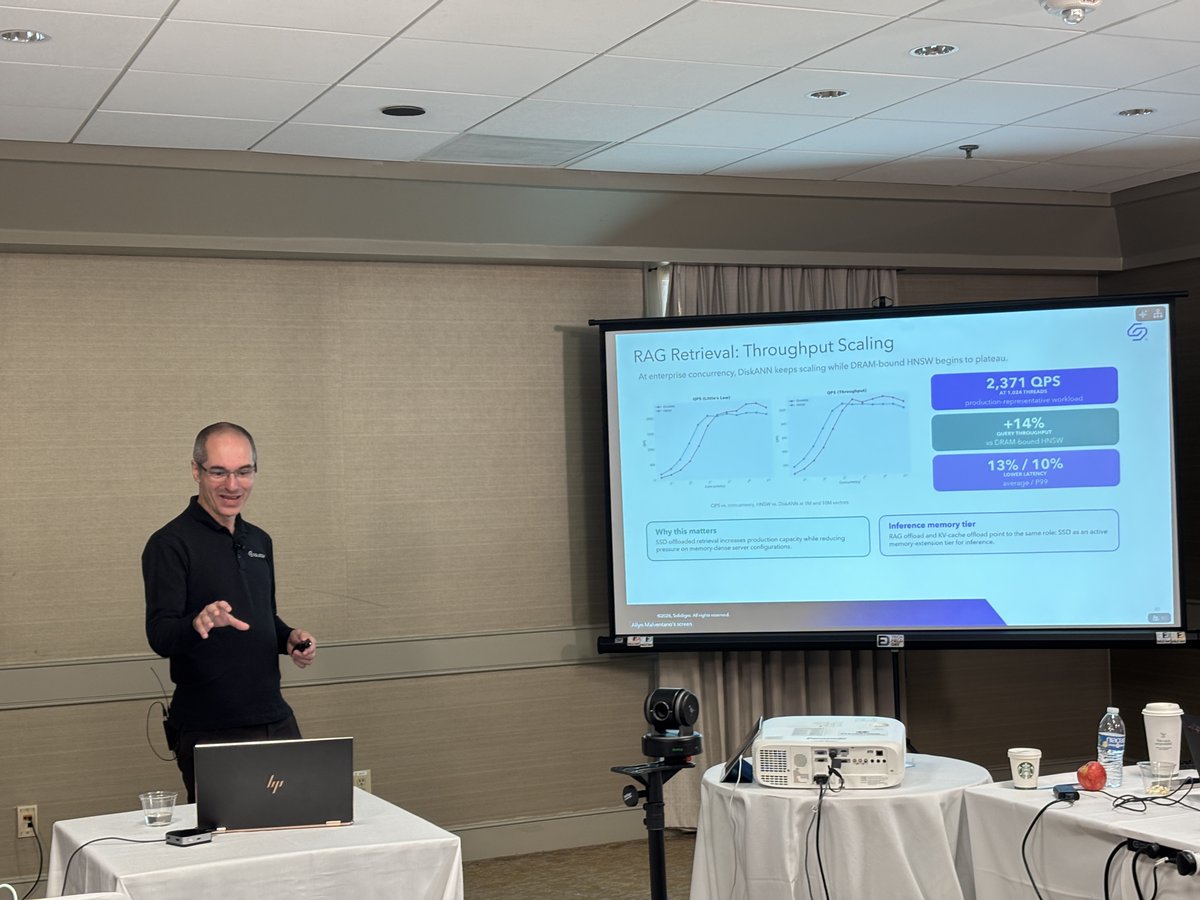















@Solidigm, @MinIO, & @Intel partnered to design and benchmark S3-compatible object storage, with a focus on performance and concurrency scaling. This white paper goes deeper into what this benchmark means for AI builders. Check out the full results! solidigm.com/products/techno…
1
4
110
RAG pipelines don't have to be DRAM-constrained. SSD-offloaded vector retrieval delivered 65% lower memory footprint and 14% higher query throughput vs DRAM-bound alternatives while maintaining 99% recall. Storage is earning its place as an active AI memory tier. #AIIFD5
1
5
198
As context windows grow, GPU memory can't keep up. Long-context AI inference forces systems to recompute the same work over and over, burning cycles and slowing response times. At scale, that's not sustainable. #AIIFD5 #Inference #GenerativeAI
1
6
126
Forget bolting KV cache onto enterprise storage. MemKV strips it down — KV-addressed, RDMA-native, NVMe-backed. Purpose-built for the way AI inference actually works. #AIIFD5 #GenerativeAI #SSD
4
50
The problem? At just 8 concurrent 32K sessions, KV cache requirements blow past GPU HBM capacity. At 32 concurrent sessions? You're at 4.3x the HBM ceiling. The memory wall is real, and it's happening now. techfieldday.com/appearance/… #AIInfrastructure #Inference #AIIFD5
4
73
Modern object storage and high-density SSDs are helping organizations build scalable, efficient AI factories. Looking forward to sharing insights alongside the @MinIO team! techfieldday.com/appearance/…
2
5
263
As organizations move from training to large-scale inference, data access, storage performance, and infrastructure efficiency are becoming just as important as compute. #Inference #GenerativeAI #AIIFD5 techfieldday.com/appearance/…
3
47
Solidigm retweeted

AI Infrastructure Field Day 5 continues now! 📆 #AIIFD5
Tune in as @Solidigm and @MinIO present 🔴 LIVE on YouTube, LinkedIn, and our Website.
🔻 YouTube: buff.ly/mNJIacG
🔹 LinkedIn: buff.ly/ABdRbS7
#AIIFD5 #AIInfrastructure #AIStorage

1
1
2
179
Solidigm retweeted
Learn more about AI Infrastructure Field Day #AIIFD5 and the presenting companies on our website 👇 🔗
@TechFieldDay @DemitasseNZ #AIIFD5 #AIInfrastructure #AIStorage #AI #AIAgents #AgenticAI
buff.ly/POOHa3e
1
1
236
This week, we invite you to join @Solidigm & @MinIO as we present “Density Without Compromise: How Storage & Memory Became the Defining Problem in Modern #AI Inference” at #AIIFD5 with @TechFieldDay! Tune in LIVE June 11 at 10:30am PT for the full session: techfieldday.com/appearance/…
1
3
122
We are pleased to announce Richard Chin as Co-CEO of Solidigm, joining Xin Guo to help lead the company’s next phase of technology development for AI infrastructure leadership. Read the full announcement: news.solidigm.com/en-WW/2661…
1
7
311
With growing RAG pipelines and KV caches, modern storage has evolved from helpful to necessary. Join Avi Shetty, Vice President of AI Ecosystem and Market Enablement at @Solidigm as he explores this topic at Computex Forum 2026 in Taipei, Taiwan on June 4! events.computextaipei.com.tw…
1
3
158
In another, Submer's Gabriel Lazar discusses data center sustainability efforts, heat reuse, infrastructure efficiency, and why the industry needs to look beyond PUE and toward IT utilization and efficiency as AI infrastructure continues to scale. (3/3) techarena.ai/content/submers…
1
3
140
In one episode, @Scaleway's Albane Bruyas shares what it takes to build a sovereign European cloud infrastructure, the company’s collaboration with OCP & how AI infrastructure is evolving to support longer-context & agentic AI workloads. (2/3) techarena.ai/content/scalewa…
1
3
126
At the OCP EMEA Summit in Barcelona, @Solidigm’s Ace Stryker joined TechArena.ai's Allyson Klein for another round of Data Insights conversations spanning sovereign cloud, sustainability, liquid cooling, and the infrastructure demands of AI at scale. (1/3)
1
3
103