
founder: NonBioS.ai, blog: nishantsoni.com, linkedin: linkedin.com/in/nishantsoni/
Joined August 2008
- Tweets 873
- Following 62
- Followers 956
- Likes 164
62 Photos and videos








21h
Claude Fable is being restricted from non-US nationals. If that holds, here's my honest reaction as an Indian founder:
Why should Anthropic and OpenAI enjoy open access to our markets while denying us access to theirs?
These models were trained on the world's data - including ours. They got better because of it. And the moment they crossed into frontier capability, the door quietly closed on everyone outside the US.
If non-US countries are denied access to Mythos/Fable, I see no reason why Anthropic or OpenAI should be allowed access to the non-US markets.
India shouldn't wait around to be let back in. We have the talent, the engineering depth, and increasingly the compute ambition to close this gap - faster than most people assume. Reciprocity should be on the table: if access is one-directional, market access should be too.
India should pull the plug on Anthropic and OpenAI - it will take us sometime to catch up - but we need to start already.
4
6
6
620
May 29
Someone with zero coding experience just launched a live, monetised gaming platform with real paying users.
No dev team. No code. 👇
4
1
6
1,493
May 26
Slopocalypse is what we should be really worried about.
SaaSocalypse refers to the market correction of SaaS stocks - driven by the fear that AI would deprecate the need for SaaS. I think it is mostly unfounded - SaaS is not going anywhere - it is just getting a new class of customers - Agents. Agents will both consume and create more SaaS - so we should expect an explosion of SaaS rather than an implosion.
But what I think is real, and immediate, is Slopocalpyse. And I think we are only seeing the tip of it.
Entire socials are drowning out in AI slop. This is creating a very 'jarring' experience to consumers who are subject to the AI driven regurgitation of content. But I suspect there is something more sinister going on underneath.
Over the last two years - I have started using AI more and more driven by a belief that rapidly accelerated use of AI will result in efficiency and performative gains over all domains. One of the important subjects has been business strategy. I have been running long discussions - specifically with Claude Opus, around business strategy for NonBioS.
This is something which started naturally as I upped my use of AI for everything. However, I am now coming around to the conclusion that this could be drastically counter productive. And the danger is not just that it is robbing you of critical thinking skills, or drowning your thoughts in sycophantic AI prose, it is that in my experience it could be disastrously, concretely wrong.
Two instances which closed this gap for me - I ran two specific discussions with Opus on specific business outcomes. One was around marketing tactics for NonBioS, and the other was improving conversions. These were not just single chats - but multiple of them looking at the topics with different lenses. Over the next few months I largely executed the advice that Opus gave me. The outcomes from those two actions which happened over the last quarter are just becoming visible - and it is becoming clear that both the tactics were disastrously wrong. Not only did they not result in the desired outcomes - but they diverted efforts from strategies that would have worked better. The culprit was Opus - and the blame was on me who chose to believe in it.
For the strategy around marketing tactics - Opus advised me that email marketing to our already existing userbase, which runs into thousands, would be the most productive marketing tactic. This worked out wrong - largely because most of our early users came from my network - (ex)engineers, IIT, (ex)FAANG professionals. But our most valuable builders turned out to be solo/independent business founders based in developed markets. For the second discussion around improving conversions - Opus advised me to reduce our entitlements on the free plan - this tanked our conversion instead. After we realized it, we overcompensated - and dramatically increased the free plan entitlements. This got conversion back on track, and then some.
In both cases, the answers that Opus gave were wrong. But the answers being wrong is not the main problem - the problem is that confident, well-reasoned wrongness is more dangerous than obvious wrongness, because you act on it.
But this wasn't the first time, I noticed similar behavior from Gemini in March of 2025. In our internal testing at NonBioS the Gemini March 2025 checkpoint - was one of the best coding models ever. Matching the current SOTA frontier models - this is something which has been reported around the internet. The key behaviour that I recall with Gemini was - that what made it best for coding - seemed like it made it disastrous for non coding fields. Specifically medicine - of which I ran multiple tests - multiple chats revealed that Gemini will double down on a wrong diagnosis once it made that call and will not retrace or revisit the diagnosis even when provided with compelling counter evidence.
This is very similar to what I suspect is going on with Opus. My thesis is that models which are great at coding are horrible in domains where the solution space is unbounded - like medicine or business strategy. And I suspect it is for the exact same reasons that make them great at coding. When given a problem space, they will choose a solution early on and double down on it. In coding, this behaviour is rewarding - because if the solution doesn't work - it can be verified quickly - you can backtrack - and try something else. And the strong belief that the solution is correct helps you converge to the point of verification rapidly.
But in subjects where the outcomes are open-ended, require substantial resources to implement, and results are visible only over a longer time period, the optimal strategy requires deeper holistic evaluations of early solutions to create a more grounded perspective.
The disaster specifically is to use frontier coding models for domains where the solution space is open-ended, and it happens not just because of the specific thought process that coding models are excellent with, but also because of the unique intersection of reinforcement learning driven sycophancy combined with their ability to convince you of their thought process due to the scaling law enablements.
Slopocalypse is not just the socials being overrun by AI drivel, but our minds being overrun with confident, well-articulated but ungrounded AI thoughts. And it's not just that they sometimes end up steering us towards wrong discussions in places that matter most, but they are robbing us of our ability to drive our thoughts to come up with our own convictions. Because that is what makes us humans above anything else - and we might be trading it away already.
3
1
57
May 21
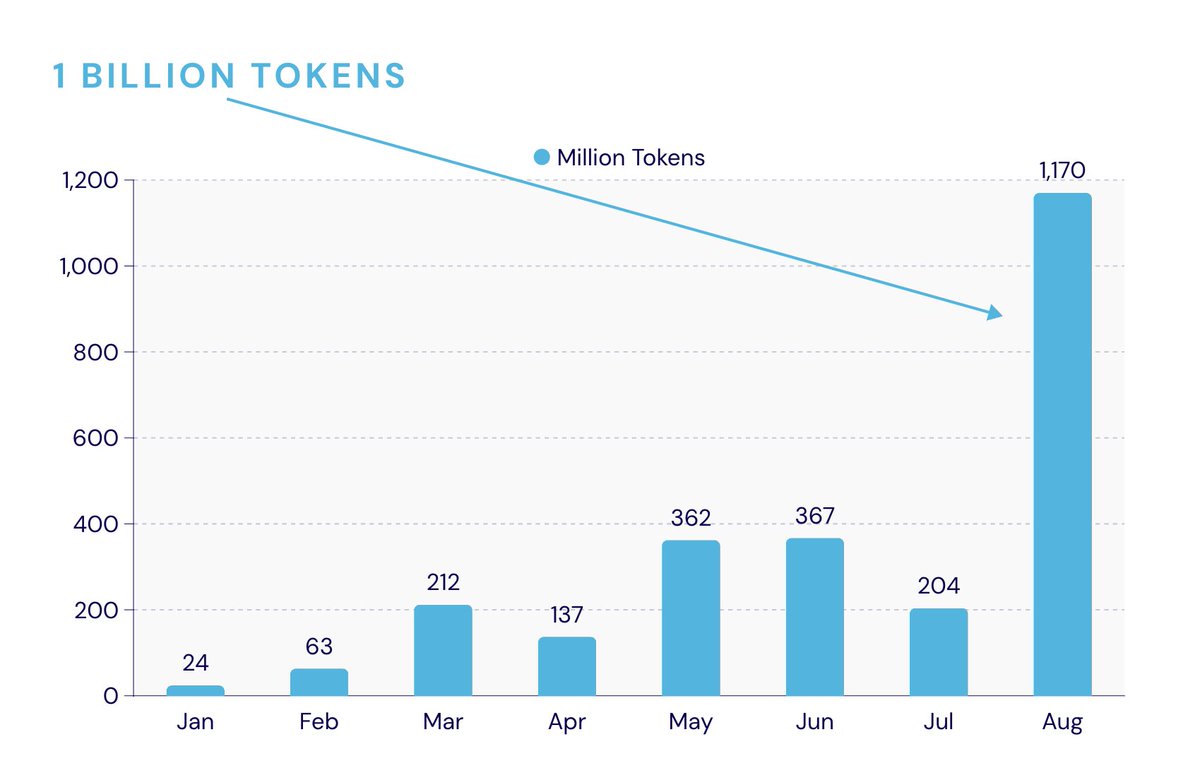
Looking for the best model for faithful summarization at 10K–30K token inputs - driven by a long-horizon autonomy use case where the model runs in a loop without human review of every output.
HELMET is the best public resource we found, by a wide margin, and its results strongly correlated with our internal findings. princeton-nlp.github.io/HELM…
Huge credit to the HELMET team. This is the kind of careful benchmark work that makes real decisions possible. The only issue is that public results stop around late 2024. The 2025–2026 frontier models aren't covered yet.
The only other serious option, Vectara's HHEM leaderboard, has fresher 2026 model coverage but doesn't pass a sniff test:
github.com/vectara/hallucina…
1. GPT-4o ranks 54th at 9.6% hallucination, contradicting our experience and Vectara's own previous-dataset result (1.5%)
2. Top ranked is Ant Group's Finix-S1-32B, an insurance-domain fine-tune
3. Second position is gpt-5.4-nano-2026-03-17 - this is again hard to believe. Our internal tests ranked gpt-5.1 worse than gpt-4o, so hard to see a 'nano' model being at the second position.
4 Oct 2024

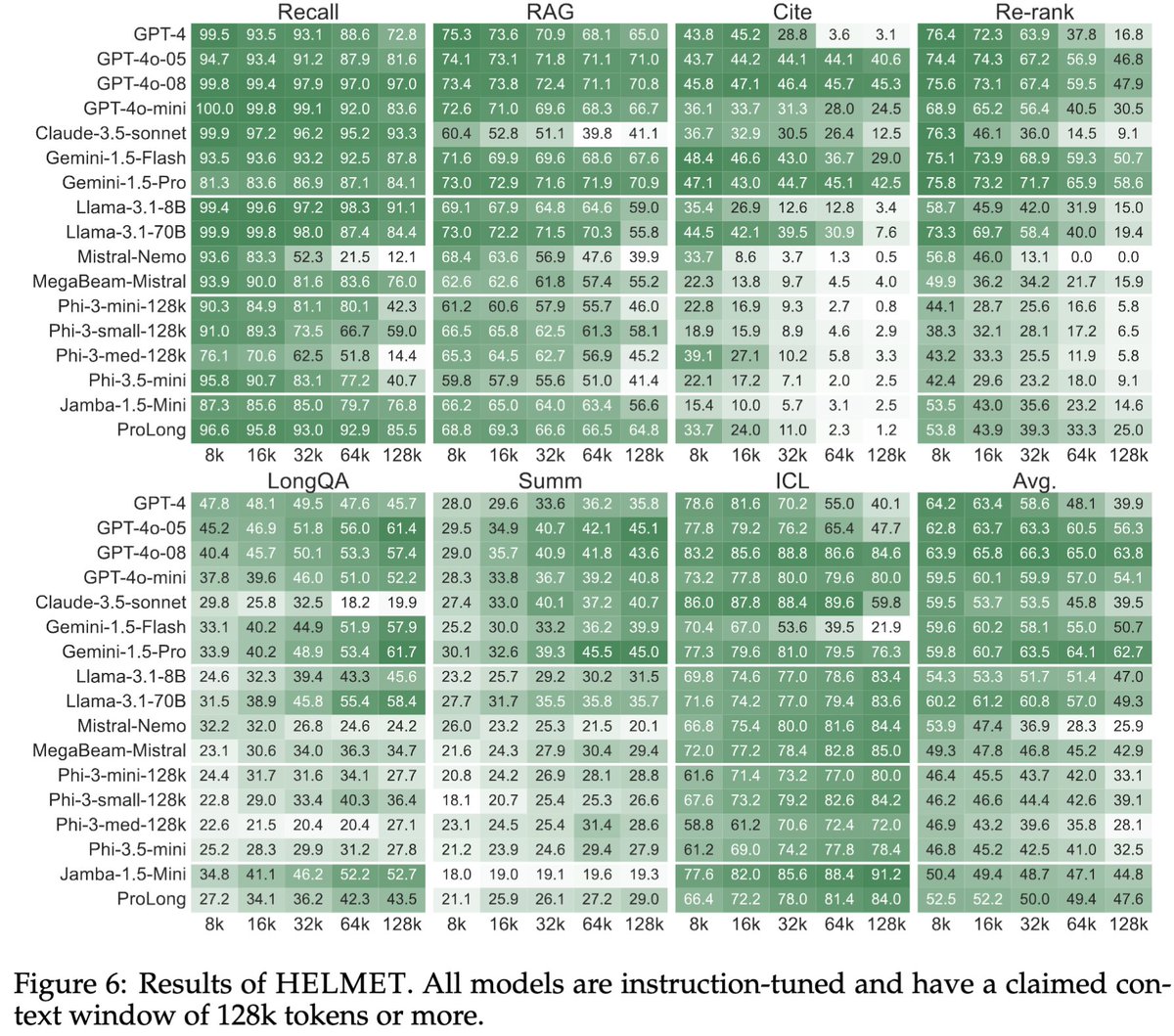
Introducing HELMET, a long-context benchmark that supports >=128K length, covering 7 diverse applications.
We evaluated 51 long-context models and found HELMET provide more reliable signals for model development
github.com/princeton-nlp/hel…
A 🧵 on why you should use HELMET⛑️
42

Built entirely on NonBioS: PlayersAreGamers.nl
A full real-time multiplayer gaming platform. Compete for coins, climb the global leaderboard, and win real prizes. Wallet system, live matchmaking, the works.
No dev team. No months of work. Just nonbios.
📺 Watch it in action: youtube.com/@playersaregamer…

1
1
1
38
May 18
NonBioS is live on Product Hunt: would love to get a comment if you have given it a shot.
Also giving away a free month of the paid plan (code on producthunt page), and double the quota on the free plan (auto-applied).

NonBioS is launching on Product Hunt this Monday, May 18th!
If you've ever believed in what we're building: a follow, an upvote, or simply sharing this post makes a real difference on launch day.
Follow us here so you're ready to support on Monday:
producthunt.com/products/non…
3
3
76
May 13
Launch special: Free month of our paid plan at launch doubling the free plan quota for the entire month. Best time to try nonbios, hands down !
NonBioS is launching on Product Hunt this Monday, May 18th!
If you've ever believed in what we're building: a follow, an upvote, or simply sharing this post makes a real difference on launch day.
Follow us here so you're ready to support on Monday:
producthunt.com/products/non…
1
1
62
May 9
One of the interesting framing of the entire AI coding capability that I read recently is that it doesn't make the best programmers faster as much as it enables the new programmers to build.
This is something I realized intuitively. I built nonbios for myself - for engineers like me who have been building for a very long time. This was how I had always built - rent a VM, setup a MVP, open it out for everyone. No github. No IDE. A blank VM, A public IP and code cranked out of Vim.
Because most experiments don't work out. If no one is using it, why scaffold an intensive build? And if it does work, all of that can come later. Even though nonbios was built for engineers, our most active users are non-engineers. I think we should just start calling them builders. Because that's what they are.
MarketCity is one of those builds:
3
3
64
Apr 23
In the past week, I have built 4 internal apps that replaced 15 SaaS tools we were using. Happy to share the bull print.
It wasn't a typo. There is no blue print - because its all bull print.
At NonBioS we use over 20 SaaS tools. We pay for all of them. We will continue to do so. We are adding 1 new SaaS tool every month on average. We will continue to add.
That doesn't mean we don't use AI to build. All the code behind NonBioS is written by NonBioS. 100% of it. But we don't write too much - only as much as we are confident about, and only what we are willing to maintain.
Somehow just because AI can now write code, we are willing to throw away what has always been golden in software engineering. That the best code, is no code. That the true cost of code, is not the cost of writing it, but of managing and maintaining it over time.
You can vibe code the SaaS you pay $20 a month for, maybe in a day. But testing it, hosting it, maintaining it is still a cost you will pay forever.
Our cheapest SaaS, costs us $10 a month. It does nothing, but ping our servers to check for uptime. Once every few minutes. To around 10 odd services which form the backbone of NonBioS. If anything goes down, someone gets a call. And it gets fixed.
We have no intention of vibe coding it ourselves. Because it just doesn't ping and check for uptime, sometimes it checks for slowness, other times it checks for keywords. If the service is slow, it sticks around and checks again. Only if it is slow for sometime, does it bother us.
And it just doesn't check from one IP. It rotates IPs and regions - so that we know that the services are up globally. And then it integrates with email, sms, phone providers to alert a geographically dispersed team.
Someone can code all of this in a day or two, using AI. But then setting up the infra will be another few days. And then you have to make sure that your infra is up. And when the alerts for service slowness goes out, it is actually the service which is slow, not your vibe coded money saver. And what if this contraption goes down itself - how do you check for that ?
Lovable got hacked. It compromised the keys and secrets that its users had kept in their service. This was the most requested feature in NonBioS for quite some time. It still is, because we haven't moved on it. Once you start holding secrets, you are putting a target on your back. And you will need to defend it with an army. We don't have one. Even if we did, I'm not sure this is the battle we will fight.
The SaaS service we pay $10 for - doesn't do all of this work for $10. They do it for a lot higher. And they split the bill across thousands of customers. That's not a bug in the model - that's the model working. Specialization, economies of scale, someone else's on-call rotation. If it were possible to do it cheaper, someone else would - and maybe they'd charge $5. And we'd move to them.
The best code is still no code. AI just made it easier to forget that.
5
27
155
5,358
Apr 21
Anthropic launched Opus 4.7 with what it is calling Adaptive Thinking. We are putting it through its paces at NonBioS, but our initial findings are that we might just sit this one out - Opus 4.7 does not seems to represent a meaningful improvement over Opus 4.6 for our use cases. We plan to continue using Opus 4.6 for now - our latest model, nonbios-1.143, still relies on Opus 4.6 in its harness, albeit with upgrades to the surrounding infrastructure.
The gotcha that Opus 4.7 gets wrong, and I confirmed:
Me: I want to wash my car. The car wash is 100 meters away - should i walk or drive ?
Opus 4.7: Walk. 100 meters is about a one-minute stroll — by the time you've started the engine and backed out, you'd basically be there on foot.
Opus 4.6 did get it right btw.
With Opus 4.7, Anthropic's strategy seems to reprise a debate that was central in late 2024. OpenAI's o1 demonstrated what appeared to be a scaling law for inference-time compute, raising the prospect of AI performance being improved not just by training larger models, but by allocating more computational resources during the inference step itself - letting a model "think longer" about difficult problems. For a period, this generated genuine excitement.
The benchmark stamps soon followed - but real world tests - at NonBioS and elsewhere soon closed that debate: Scaling inference time compute could uplift performance on specific tasks but reports that a 70 bn parameter model would outperform a 200 bn parameter model was far fetched. The broadly accepted picture now is more nuanced: smaller models combined with advanced inference algorithms can offer competitive cost-performance trade-offs, but this holds primarily within specific problem types and not as a general substitute for a larger, more capable base model.
The scaling laws for model size broadly continue to hold. Larger models tend to demonstrate more general intelligence by a significant margin.
What Anthropic appears to be doing with Opus 4.7, in my assessment, is something adjacent to this older playbook. You see about a week back, users at nonbios started complaining that nonbios-1.142 was showing degradation in performance. nonbios-1.142 uses Opus 4.6 heavily in its harness. Wider internet reports confirmed our suspiciion - Anthropic had quietely degraded Opus 4.6.
Our working hypothesis - is that Adaptive Thinking in Opus 4.7 is intended to compensate for a model that may have been adjusted (maybe using quantization adjacent techniques) for cost efficiency, by having it reason more extensively on complex tasks.
In other news, Anthropic announced Mythos as a frontier model, but withheld it from general release on the grounds that its offensive cyber capabilities were too dangerous. On the benchmarks, Mythos appears to be a substantially more capable model than Opus. This broadly checks out - a larger, more capable model tends to demonstrate correspondingly better general intelligence - but it will also be considerably more expensive to serve. Whether the restricted rollout is primarily a safety decision, or a cost decision is something only Anthropic knows.
The more consequential question, in my view, is a geopolitical one. India has emerged as Anthropic's second-largest consumer market globally. At the same time, Mythos - Anthropic's most capable model - is being shared selectively within the US national security ecosystem. There are reports about Anthropic pushing back against using AI for autonomous weapons, but the practical upshot is that the US national security apparatus has some access to Mythos in its restricted form, while major commercial partners like India do not.
As awareness grows that Anthropic's most powerful model is being made available to US defence agencies while being withheld from allied-but-non-US markets, it could prompt difficult questions. Governments in such markets may begin to ask whether they should allow market access to a technology whose frontier capabilities are effectively reserved for American national security purposes. Especially, in a competitive landscape where OpenAI is actively courting the same market.
What makes this situation geopolitically charged is that AI is not like previous general-purpose technologies in its relationship to military power. Mobile phones, the internet, even GPS all proliferated globally with relatively symmetric access. Their military applications were real, but derivative - they improved communication, logistics, coordination. AI is fundamentally suited for deployment in warfare - it will increasingly be the primary intelligence layer ingesting data, generating options, and compressing decision cycles from hours to seconds, and maybe a structural shift in what determines military effectiveness.
3
12
265
6,482
Apr 11
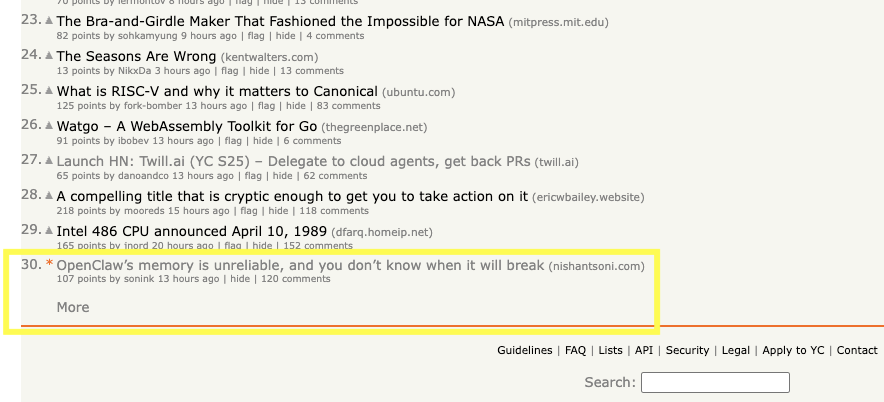
I've Seen a Thousand OpenClaw Deploys. Here's the Truth.
We made a YouTube video showing how NonBioS can deploy OpenClaw on a fresh Linux VM automatically - zero human intervention, about 7 minutes start to finish. It was meant as a demo of what NonBioS can do with any open source software.
It went a little further than we expected.
Since then, we’ve had roughly a thousand OpenClaw deployments through our infrastructure. People come in, spin up a VM, get OpenClaw running, connect it to WhatsApp or Discord, and start experimenting with this thing that Jensen Huang called “the operating system for personal AI.”
I also spoke with multiple people in my own network - engineers, founders, technical operators - who deployed OpenClaw independently and spent real time trying to make it useful. Not a weekend of tinkering. Weeks. Some of them genuinely wanted to make it work and went to great lengths setting it up.
Here’s what I found: there are zero legitimate use cases.
I don’t want to be unfair - OpenClaw is not fake. It’s a real piece of software. It installs. It runs. It connects to your messaging apps. It can talk to Claude and GPT. It can execute shell commands. The technology exists.
But when I looked at what people are actually doing with it - across our thousand deploys, across conversations with my network, across the flood of LinkedIn and Twitter posts - I couldn’t find a single use case that holds up under scrutiny.
The core issue is: Memory, and everything else flows from it.
OpenClaw runs as a persistent agent. It’s supposed to be your always-on assistant. But its memory is unreliable, and the worst part - you don’t know when it will break.
Think about what that means in practice. You ask OpenClaw to send an email on your behalf. It’s been following a conversation thread about a birthday party you’re planning. Three people confirmed. One person declined. OpenClaw sends the update email - but it’s lost the context about who declined. Now you’ve sent a message with wrong information to everyone on the list, and you didn’t catch it because the whole point of an autonomous agent is that you’re not supposed to be checking every output.
An autonomous agent that you have to verify every time is just a chatbot with extra steps.
This isn’t a bug that gets fixed in the next release. It’s a fundamental constraint of how OpenClaw manages context. The agent runs, the context fills up, things get forgotten. Sometimes the important things. You’ll never know which things until after the damage is done.
I’ve spent the last year working on this exact problem at NonBioS. We call our approach Strategic Forgetting, and I can tell you from deep experience: keeping an AI agent coherent over long task horizons is the hardest engineering problem in this entire space. It’s not something you solve by creating a memory architecture which maps every day, month, year to separate files. The brain is not a list of files that you index. You don’t remember everything at a high level which happenned last month, and you can’t ‘pull in’ the details of a specific day. You remember everything, all at once, whatever is important and you forget the details, unless they are important too.
After going through everything I could find - our deploy data, user conversations, posts online - the only use case that genuinely works is daily news summaries. OpenClaw searches the web for topics you care about, summarizes them, and sends the summary to you on WhatsApp every morning.
That’s it. That’s the killer app.
A personalized daily briefing is nice. But you can already do this with a Zapier workflow and any LLM API. Or with ChatGPT’s scheduled tasks. Or with about a dozen other tools that have existed for years. You don’t need a 250,000-star GitHub project running on a dedicated server with root access to your environment to get a morning news digest.
But there is part of the entire OpenClaw saga that I think needs to be said plainly.
The vast majority of posts you see about OpenClaw: “I automated my entire team with OpenClaw,” “OpenClaw replaced three of my employees,” “My OpenClaw agent runs my business while I sleep” - are designed to capture marketing hype. People know that OpenClaw content gets engagement right now, so they produce OpenClaw content. The incentive is the audience, not the accuracy.
I’ve talked to people behind some of these posts. In every case, when you dig deeper, the story is one of two things: either what they built could already be done with standard AI tools (ChatGPT, Claude, any decent LLM with a simple integration), or it’s aspirational - a weekend prototype that technically works in a demo but that nobody would trust with real tasks.
I’m not calling anyone a liar. I think most of these people genuinely believe in what they’re building. But there is a meaningful gap between “I got OpenClaw to do something cool once” and “I rely on OpenClaw to do something important every day.” I haven’t found anyone in the second category.
The safety situation around OpenClaw has been well documented so I won’t belabor it. This is the environment in which people are connecting OpenClaw to their email, their calendar, and their messaging apps. With an agent that has unreliable memory. Running on their personal computers.
We made the NonBioS deployment video specifically because we saw this problem - at minimum, if you’re going to experiment with OpenClaw, do it in an isolated VM where a compromise doesn’t touch your personal data. That’s table stakes, and most people aren’t even doing that.
So should you bother?
Here’s my honest take. If you have a weekend to spare and you enjoy tinkering with new technology, OpenClaw is a fascinating experiment. You will learn things about how AI agents work, about the gap between demos and production, about why context management matters. It’s a great educational experience.
But if you’re evaluating whether to invest real time to OpenClaw as it exists today, you can give it a pass without feeling left out. You’re not missing a productivity revolution. You’re missing a morning news digest and a lot of time spent configuring YAML files.
The ideas behind OpenClaw are right. The era of AI agents that do real things on real computers is here. I believe that deeply - it’s what we’re building at NonBioS every day.
But the execution isn’t there yet. And until the memory problem is solved - until you can actually trust an autonomous agent to remember what matters and forget what doesn’t, consistently, over hours and days of work - the rest is theater.
--
Front page discussion on Hacker News confirms everything:
7
44
387
21,932
Apr 11
HN Discussion: news.ycombinator.com/item?id…
Full post on Substack: blog.nishantsoni.com/p/ive-s…
15
2,220
Nishant Soni retweeted

Apr 10
great honest assessment of OpenClaw by @sonink. after running an OpenClaw agent for 90 days, there's nothing I disagree with. if you like tinkering and peaking around corners, OpenClaw is an incredibly fun but legitimate use cases today have an effective EV = 0.
open.substack.com/pub/nishan…
2
7
513
Apr 10
Multiple users @NonBioS are reporting that our latest agent based on Opus 4.6 is sounding a bit dumb. This is most likely the result of @AnthropicAI quantizing Opus 4.6 behind the scenes to move capacity to Mythos.
Not changing production end points behind the scenes was Software Engineering 101 - shocking to see this core principle being abandoned in the AI wars.
4
400
Apr 3
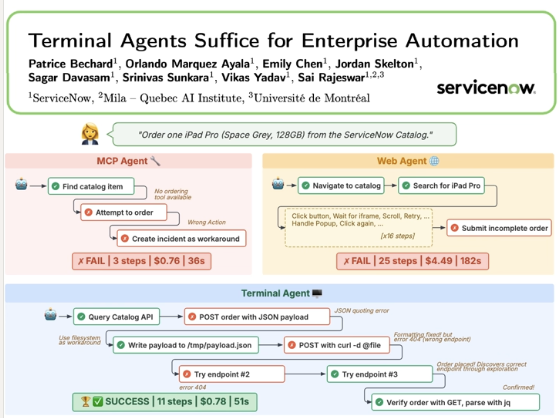
This is exactly how @nonbios works.
nonbios is a terminal agent. More specifically, it operates through a shell, an interface to the command line.
Why? Because LLM training data is saturated with Linux shell usage: man pages, Stack Overflow, GitHub repos, sysadmin guides. The shell is the single most well-represented human-computer interface in LLM training corpora.
When you give a model a shell, you meet it where it already knows how to operate.
1
3
390
Apr 3
Sometimes the simplest call is the right one. The terminal has been the backbone of computing for 50 years. It didn't need reinventing. It just needed a smarter operator.
Great work by @patricebechard, @RajeswarSai and the @ServiceNow AI team.
Paper link below 👇
2
3
297