
The moon shines for everyone. soynade.ai
Joined November 2024
- Tweets 22
- Following 0
- Followers 132
- Likes 2
12 Photos and videos












May 11
After Wolof, Fula will soon be supported by Oolel-Voices, our open-source speech generation model.
Mar 12

Release 3 of the Soynade Open Source Month.
Oolel-Voices: a speech generation model supporting voice cloning with expressive, modular control over tone and pace, making it suitable for content creation.
Try it now: huggingface.co/spaces/soynad…
Model: huggingface.co/soynade-resea…
4
4
582
Apr 6
We are releasing Oolel-Corrector, a new model in the Oolel family trained to fix non-standard Wolof orthography as commonly written on social media.
The model is available on Hugging Face.
huggingface.co/soynade-resea…
Mar 31
We're releasing a dataset of non-standard Wolof orthography. The goal is to help models understand Wolof as it's actually written online, not just as it should be.
Dataset: huggingface.co/datasets/soyn…
3
2
351
Soynade Research retweeted
Mar 31
We're releasing a dataset of non-standard Wolof orthography. The goal is to help models understand Wolof as it's actually written online, not just as it should be.
Dataset: huggingface.co/datasets/soyn…
1
24
46
11,191
Mar 16
4e publication du mois de l'open-source de Soynade.
Oolel-Embed: un modèle permettant de récupérer des documents directement à partir de la parole, sans passer par des étapes intermédiaires coûteuses de reconnaissance vocale et de traduction.
Model: huggingface.co/soynade-resea…
2
19
38
6,771
Mar 16
Oolel-Embed est efficace grâce aux représentations Matryoshka, permettant de représenter l'information dans des espaces vectoriels très petits.
Voyez Oolel-Embed en action:
2
8
1,283
Mar 12
Release 3 of the Soynade Open Source Month.
Oolel-Voices: a speech generation model supporting voice cloning with expressive, modular control over tone and pace, making it suitable for content creation.
Try it now: huggingface.co/spaces/soynad…
Model: huggingface.co/soynade-resea…
1
21
44
13,464
Feb 28
Release 2 of the Soynade Open Source Month.
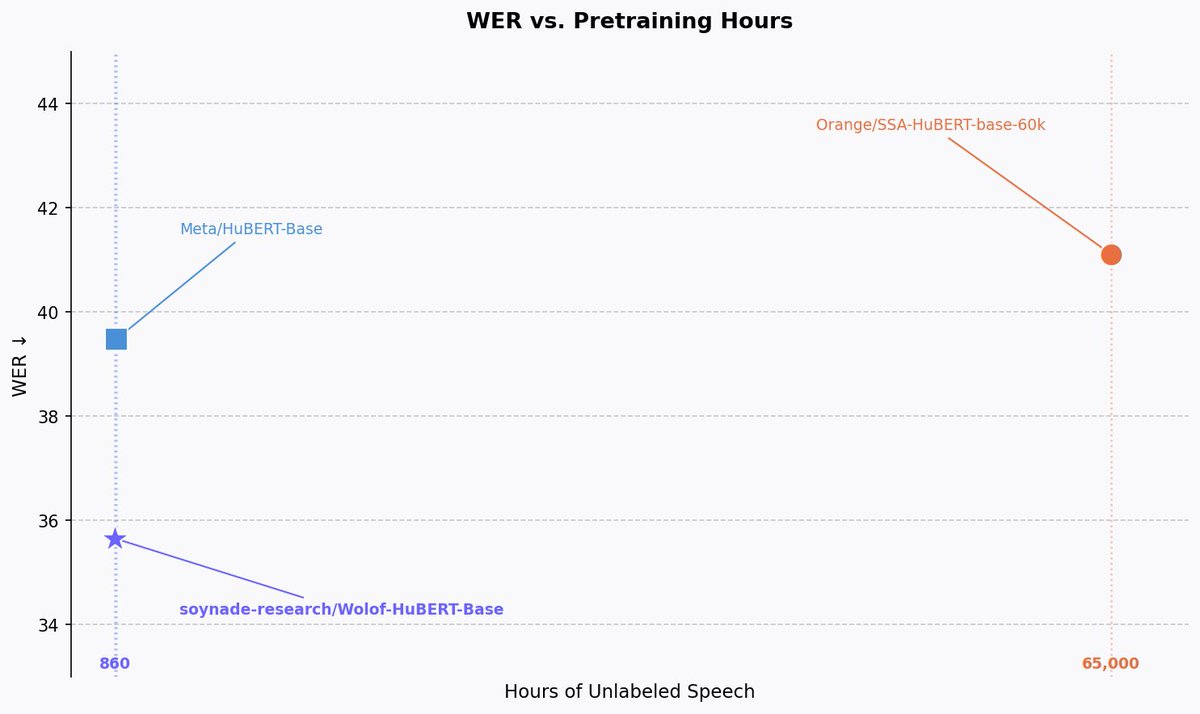
A small foundational speech representation model for Wolof, continued pretrained from Meta/HuBERT on 860 hours of Wolof speech. This improves the ASR performance using only unlabeled speech data.
huggingface.co/soynade-resea…
1
13
24
2,372
Feb 28
Continued pre-training allows us to be more compute-optimal than Orange's model while significantly outperforming the base Meta/HuBERT-Base model.
We release the ASR fine-tuned model along with 100 hours of clean Wolof ASR data.
Models and dataset here:
huggingface.co/collections/s…
1
4
3
795
Feb 19
Today we kick off Soynade's Open Source Month, four weeks of releasing models, datasets, and tools for African languages.
Learn more: soynade.ai/research/soynade-…
The first release is live:
→ AfVoices-Translated: 200k Bambara-English speech translation dataset with acoustic tags.
1
5
5
983
Feb 19
Frontier technology, research, and data should circulate, not sit behind closed doors. Anyone should be able to audit it, extend it, and build on it.
1
100
Feb 19
- AfVoices-Translated: huggingface.co/datasets/soyn…
- FineWeb-Wolof-50k: huggingface.co/datasets/soyn…
- Oolel-Translator: github.com/soynade-research/…
1
94
5 Jun 2025
Oolel peut voir des images et vidéos : un vision LLM ouvert pour le wolof.
Et il n’a été entraîné sur aucune donnée visuelle en wolof !
On explore des pistes de recherche pour transférer les capacités multimodales d’une langue à une autre, sans entraînement multimodal direct.
1
4
6
267
5 Jun 2025
Ce qui permettra d'avoir des capacité multimodales pour les langues africaines à moindre coût 💸
Stay tuned! On a plein de modèles ouverts qui arrivent.
2
2
145
24 Jan 2025
𝐎𝐨𝐥𝐞𝐥-𝐒𝐦𝐚𝐥𝐥-1𝐁: On-device AI for Wolof with a Lightweight Language Model
🚀 Meet Oolel Small, the lighter version of the Wolof LLM Oolel - bringing on-device AI to Wolof speakers. You can run it locally without any internet connectivity
1
12
13
2,899
24 Jan 2025
It has been optimized for essential tasks like natural text generation in Wolof and English, translation, and RAG capabilities, while maintaining a compact size.
1
1
1
193
26 Dec 2024
Petite expérience intéressante que vous pouvez reproduire : générer du texte avec notre LLM 𝐎𝐨𝐥𝐞𝐥 et le vocaliser à l’aide du modèle Text-to-Speech de @galsenai.
1
1
1
191
26 Dec 2024
La combinaison de ces deux modèles open source ouvre la voie à de nombreux cas d'usage : création de contenus audio, assistants vocaux, etc. Les prochaines versions d'Oolel intégreront directement des capacités vocales.
1
113
26 Dec 2024
En attendant, vous pouvez d'ores et déjà combiner ces deux technologies. C'est la beauté de l'open source - des innovations qui se complètent pour faire avancer les technologies pour les langues sous-représentées.
1
1
110