
I write about data engineering | SQL | Python | Distributed systems. Get my free data engineering course at startdataengineering.com/ema…
Joined April 2020
- Tweets 1,954
- Following 49
- Followers 9,358
- Likes 594
132 Photos and videos



Pinned Tweet

25 May 2020
Exercise project for anyone starting in data engineering startdataengineering.com/pos…
#dataengineering #bigdata #ETL #ApacheAirflow #AWS #ApacheSpark
14
90
475
Jun 12
Upserting data in a warehouse is tricky. What happens when it fails partway through?
Are you sure you're updating only the right rows?
MERGE INTO puts all your insert/update/delete logic in one atomic statement. Full guide 👇
startdataengineering.com/pos…
#spark #sql #dataengineer
4
109
Jun 10
Building throwaway pipelines for quick wins, then losing days fixing them?
The fix is boring but real: data modeling upfront
I broke down the design decisions that let you move fast without breaking everything 👇
startdataengineering.com/pos…
#datapipeline #datamodel
1
128
SQL is the bread and butter of data engineering.
Whether you are a seasoned pro or new to data engineering, there is always a way to improve your SQL skills.
Check out 8 patterns to uplevel your SQL skills.
startdataengineering.com/pos…
#dataengineering
#sql
#datapipeline
3
225
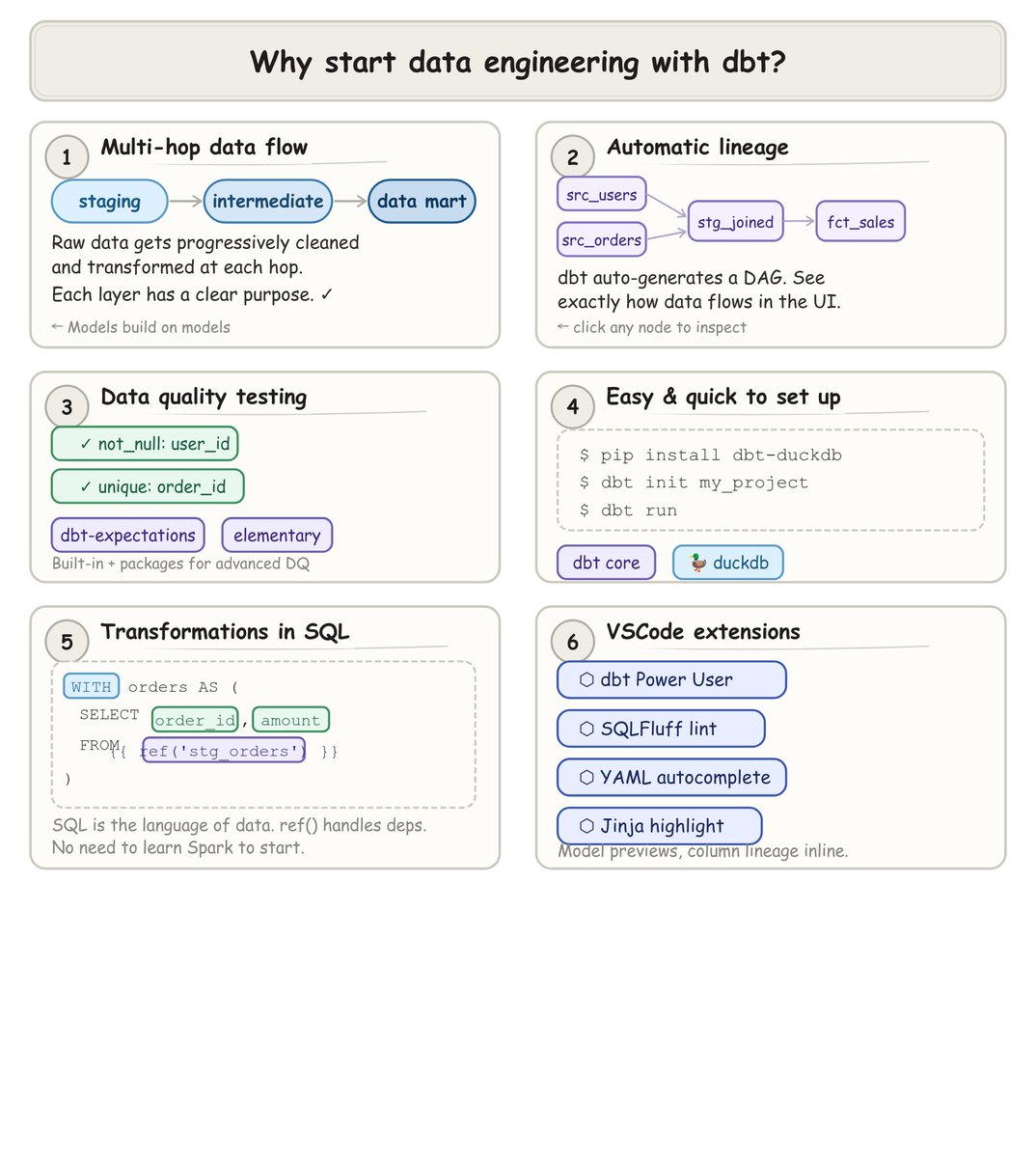
The project structure dbt recommends for data modeling is complex and confusing.
At almost every company I've worked we've used these 3 layers:
1. raw tables as-is from source
2. tables modeled as facts and dims
3. summary tables
I'm working on upgrading my dbt tutorial
#dbt
1
3
200
If you are a data engineer or looking to break into Data Engineering, Apache Airflow is a must-know.
Check out my post on how to think about orchestration and scheduling with Airflow.
startdataengineering.com/pos…
#dataengineering
#apacheairflow
#datapipelines
ALT https://www.startdataengineering.com/post/airflow-tutorial/
2
6
703
Adding short video explanations to my posts, let's see how that goes
startdataengineering.com/pos…
#dataengineering
2
146
May 26
Stuck preparing for data engineering system design interviews?
Use this article to guide you through the prep.
startdataengineering.com/pos…
#dataengineering #interview #systemdesign
2
209
May 21
Everyone says you need to know Python for data work. But what does that mean exactly?
In this post I cover the key Python concepts every DE needs to know ⬇️
startdataengineering.com/pos…
#dataengineering
#python
#datapipeline
#softwareengineering
#dataanalysis
1
1
5
358
May 18
Pipeline code can be generated; set yourself apart by understanding how to design pipelines.
Learn how to design your pipelines based on given inputs and required outputs.
startdataengineering.com/pos…
#dataengineering
#datawarehouse
#sql
#etl
#datapipeline
1
17
595
Joseph Machado retweeted

May 15
I strongly believe there are entire companies right now under heavy AI psychosis and its impossible to have rational conversations about it with them. I can't name any specific people because they include personal friends I deeply respect, but I worry about how this plays out.
I lived through the great MTBF vs MTTR (mean-time-between-failure vs. mean-time-to-recovery) reckoning of infrastructure during the transition to cloud and cloud automation. All those arguments are rearing their ugly heads again but now its... the whole software development industry (maybe the whole world, really).
It's frightening, because the psychosis folks operate under an almost absolute "MTTR is all you need" mentality: "its fine to ship bugs because the agents will fix them so quickly and at a scale humans can't do!" We learned in infrastructure that MTTR is great but you can't yeet resilient systems entirely.
The main issue is I don't even know how to bring this up to people I know personally, because bringing this topic up leads to immediately dismissals like "no no, it has full test coverage" or "bug reports are going down" or something, which just don't paint the whole picture.
We already learned this lesson once in infrastructure: you can automate yourself into a very resilient catastrophe machine. Systems can appear healthy by local metrics while globally becoming incomprehensible. Bug reports can go down while latent risk explodes. Test coverage can rise while semantic understanding falls. Changes happens so fast that nobody notices the underlying architecture decaying.
I worry.
512
1,901
15,329
1,586,229
May 15
Your data warehouse bill is high for one reason.
Full table scans. Every query reads everything, whether it needs to or not.
Here are 6 storage patterns that fix this 👇
startdataengineering.com/pos…
3
367
May 14
Spark API is easy to learn.
But to debug a hanging job, you need to know Spark internals.
Here are 7 topics to know for production Spark 👇
1
1
9
396
May 14
6. Read the Spark UI: Slow stages, skewed tasks, spill to disk are all there. If you can't diagnose a hanging job, you can't own one in production.
7. Observability, audit, and lineage: You need to know what ran, when, on what data, and whether it succeeded.
1
1
96
May 14
The API is the easy part. Production is where the real learning happens.
1
79
May 13
Large datasets are stored as individual files in S3. Too many small files per dataset make reads expensive!
Learn to: Detect it, Compact it or use table properties during insert.
Read how to here 👇
startdataengineering.com/pos…
#dataengineering #data #apachespark #apacheiceberg
2
4
250
May 12
PSA: Understand the concepts and read the docs, before using LLMs
Claude sent me on a wild goose chase, hallucinations, complex setup that breaks stuff, etc
Wasted a lot of time, only to realize the tool(quarto) I work with already does what I needed
3
408
May 12
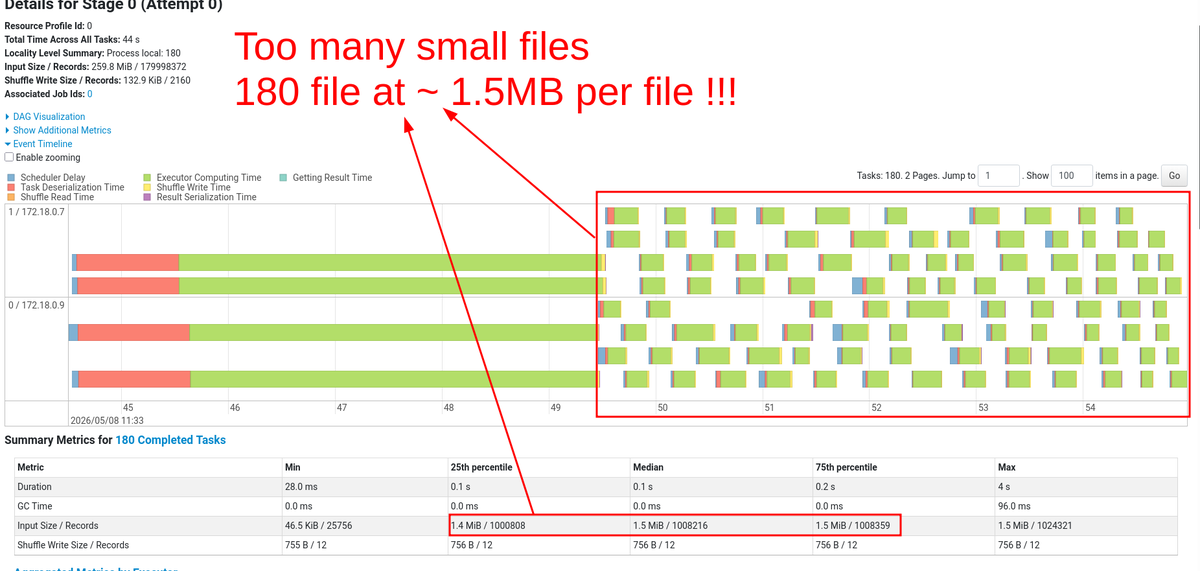
Too many small files in your data lake impact performance.
Detect it with Spark UI
1. Go to the stages tab, see the event timeline.
2. Many small tasks (1 task = 1 green chunk) indicate a many-small-files (or partitions) problem.
Fix coming tomorrow
#dataengineering
3
10
584