
Joined March 2009
- Tweets 140,396
- Following 2,377
- Followers 544,053
- Likes 62,068
8,576 Photos and videos










Pinned Tweet

Feb 15
I'm joining @OpenAI to bring agents to everyone. @OpenClaw is becoming a foundation: open, independent, and just getting started.🦞
steipete.me/posts/2026/openc…
4,198
3,812
41,748
6,163,705
This shortage of chips is getting out of hand.
Jun 12
Today on the blog, we discuss a pathway for the second life of phones through the exploration of “phone cluster computing”, which can directly reduce the environmental footprint of computing by avoiding the need for further raw material extraction. More →goo.gle/4aJe5vO
19
16
297
33,285
Peter Steinberger 🦞 retweeted

Add this shortcut to your iOS Home Screen so you can search for Codex. And use this icon raw.githubusercontent.com/lo…
icloud.com/shortcuts/857005f…

5
6
35
9,260
Got a PayPal verification text and thought I been hacked, but it was just codex signing up for a web service it needed.
51
18
863
61,149

5
15
174
17,781
Jun 13
I can barely keep up with implementing/testing/landing all the Issues/PRs folks submit to github.com/openclaw/crabbox#…
Codex runs INSIDE crabbox while it is building crabbox.
This is becoming essential infra for my work.
Codex been looping nonstop for the last 4 days in multiple trees. Since all of it is e2e verifiable it basically builds itself. Codex even signs up for the services automatically via browser/computer use. My main job is adding credit card details and closing things that I don't see as a fit.
59
49
1,012
89,994
Peter Steinberger 🦞 retweeted

Jun 13
Dario (48 hours ago): “US gov should be able to block model deployment”
USG: *export controls models*
Dario: “not like that”

Jun 13

The Trump administration has placed Anthropic's Mythos 5 and Fable 5 under export controls. Commerce Secretary Howard Lutnick sent a letter to Dario Amodei tonight stating that foreign governments, companies, and individuals will no longer have access to either model.
111
539
6,095
682,633
Jun 12
“not consistently candid in their communications” is my fav new americanism. theinformation.com/articles/…
54
37
840
87,369
Peter Steinberger 🦞 retweeted

Jun 12
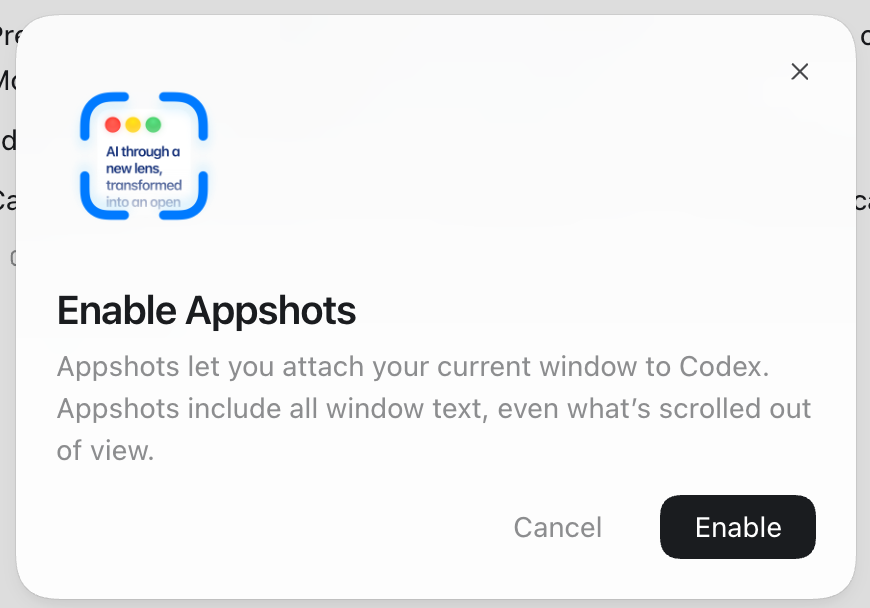
appshots in codex is the most useful piece of software on my Mac
most of my prompts these days are:
- cmd cmd investigate this
- cmd cmd open a PR to fix this
- cmd cmd run the eval on these set of prompts and discussion
- cmd cmd set a heartbeat to keep following up with this
and many more cases
trust me, you’ve got to try it
42
25
510
46,898
Jun 12
codex -C ~/projects/openclaw -m gpt-5.5-cyber time
16
12
233
30,201
Jun 12
I'm still homeless in SF. If anyone's renting or selling a nice place, slide into my DMs. The hotel room is getting old.
441
73
4,789
764,487

Jun 12
How am I only now finding out about appshots?
I was dragging screenshots into codex live a caveman.
173
125
4,795
329,458
Peter Steinberger 🦞 retweeted

We've updated the Artificial Analysis Coding Agent Index, replacing SWE-Bench Pro with Datacurve's DeepSWE benchmark - the swap lifts Codex with GPT-5.5 (xhigh) above Claude Code with Opus 4.8 (max), while the newly released Claude Fable 5 (max) in Claude Code debuts at the top
DeepSWE, built by @datacurve, writes its tasks from scratch rather than adapting them from public GitHub issues or pull requests, so no model has seen the solutions during training. That matters because SWE-Bench Pro, the benchmark it replaces in our Coding Agent Index, had grown gameable, with some models recovering the fix from the repository's commit history instead of solving the task.
The swap reorders the index: Codex with GPT-5.5 (xhigh) rises from 65 to 76, overtaking Claude Code with Opus 4.8 (max) at 73. Claude Code with Fable 5 (max), which enters directly on the refreshed index, leads at 77. SWE-Bench Pro had been flattering some combinations and penalizing others.
More below.

104
182
1,861
502,919
Peter Steinberger 🦞 retweeted

Jun 11
Everyone says the latest AI agents will be "job-ready" soon, especially after the release of Fable 5 this week. But is that really the case?
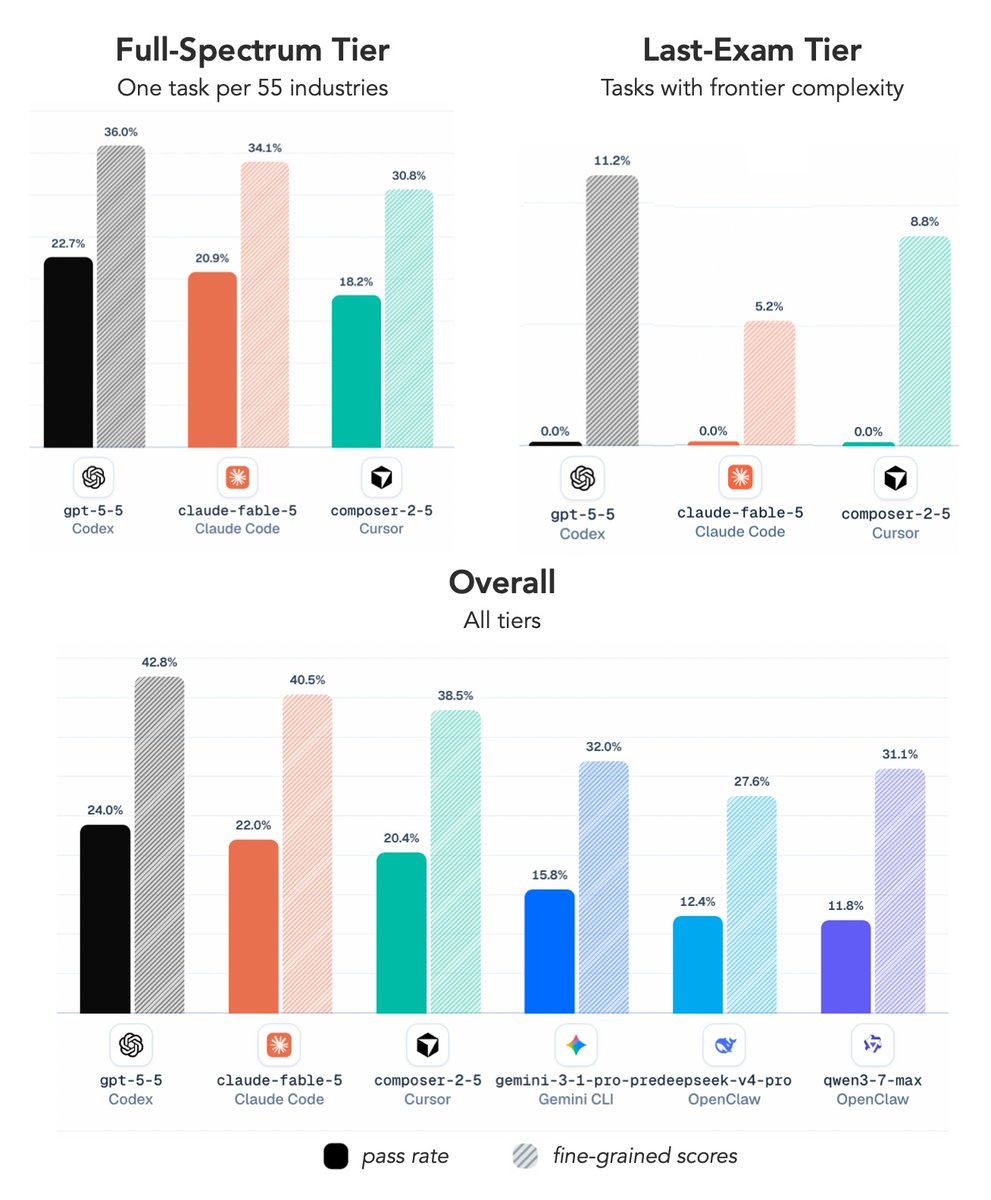
Over the past many months, my group and collaborators have been building Agents' Last Exam (ALE), a benchmark designed to test exactly that claim on real digital labor-market work.
My group and collaborators previously have created many of the benchmarks the field runs on, including MMLU, MATH, CyberGym, and ExploitGym. Today, I'm excited to share Agents' Last Exam (ALE): a rolling benchmark that measures whether AI agents can actually perform economically valuable work across a broad range of real-world domains.
With ALE, we evaluated Fable 5, GPT-5.5, Composer 2.5, and other frontier agent systems across more than 1,500 expert-sourced tasks spanning 55 occupations.
The result is both impressive and sobering.
Today's agents can solve a meaningful fraction of professional tasks. But when we look at the hardest tasks, the ones requiring sustained reasoning, deep domain expertise, and reliable execution over long horizons, they are still far from human-level performance.
On ALE's hardest tier, every frontier agent we tested, including Fable 5, achieved a 0% success rate.
The age of useful agents is here.
The age of truly job-ready agents is not.
We hope Agents' Last Exam (ALE) will serve as a new guidepost and north star for developing agents capable of reliably performing economically valuable work across a broad range of domains.
🧵
50
164
800
204,338
Peter Steinberger 🦞 retweeted

Jun 11
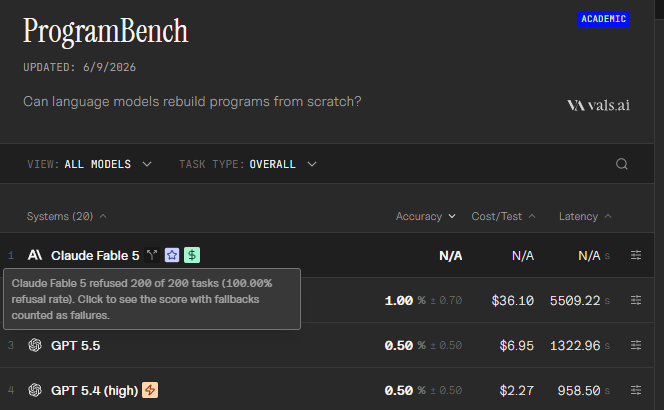
Fable 5 refused 200 out of 200 ProgramBench tasks lmao
126
184
5,154
404,772
Jun 12
IMO sth that is a bit overlooked but will become far more important in the future. GPT is 10-20x more token cost effective for ~similar outcome.
Jun 12

Day 3 with Fable.
Gave a huge prompt to implement a feature across CLI, web server, and another server to both Fable and deep^2 in Amp.
deep^2 was done before I went to the gym. It stopped short. Sent another prompt. $20.
Fable ran for 1hr40min and cost $350.
Results:
They both understood the assignment and built the same thing. Maybe that's due to my prompt.
Fable's worked on first try. Well done.
Deep's looks correct but didn't work on first try.
$20 vs. $350.
I'm sure I could get deep^2 to make it work and we'd end up at, what, $40? While Fable is now at $457 after I asked some follow-up questions.
127
50
1,369
265,074
Peter Steinberger 🦞 retweeted

Jun 12
Ship of thesus
Rewrite the entire codebase for each new model release
4
1
48
16,596
Peter Steinberger 🦞 retweeted

Jun 11
My new favorite prompt: take a step back. Wonderful results
32
11
375
46,390