
Joined February 2025
- Tweets 348
- Following 156
- Followers 10,511
- Likes 479
68 Photos and videos










Pinned Tweet

May 29
⚡️ Step 3.7 Flash is here: The new frontier is agent efficiency.
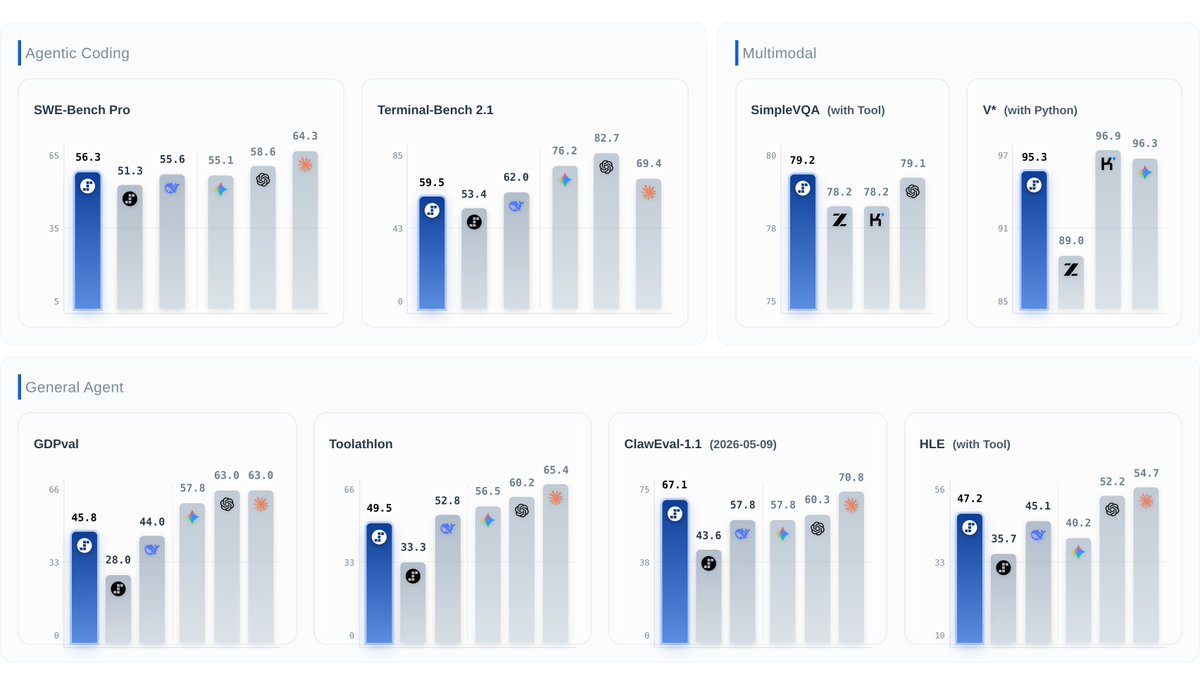
#1 ClawEval-1.1 (67.1), #1 SimpleVQA Search (79.2), #2 SWE-PRO (56.3), 95.3 on V* Python. Open weights under Apache 2.0.
Built for agentic, coding, search, and multimodal workflows — balancing speed, cost, and reliable execution.
- 400 TPS. 198B sparse MoE, ~11B active. 256K context, 3 reasoning levels.
- Understands UIs, charts, docs, images — then writes code or calls tools to act on what it sees.
- Web visual search reaches further: more sources, deeper follow-up.
- Reliable tool use — less drift, fewer broken toolcalls. 98% on τ²-bench across all difficulty levels.
- Works with Claude Code, KiloCode, Hermes Agent, OpenClaw, and protocols like MCP.
- Runs locally on Mac Studio M4 Max, DGX Spark, AMD AI Max 395.
GitHub: github.com/stepfun-ai/Step-3…
HuggingFace: huggingface.co/stepfun-ai/St…
GGUF: huggingface.co/stepfun-ai/St…
ModelScope: modelscope.cn/models/stepfun…
API: platform.stepfun.ai
Blog: static.stepfun.com/blog/step…
120
213
1,543
339,741
Step 3.7 Flash is now live on @DeepInfra 🚀
Builders and teams can now try our open-source multimodal reasoning model through DeepInfra’s API, with private endpoint deployment available for dedicated workloads.
Built for agentic coding, tool use, search, and vision workflows.
Thanks to the DeepInfra team!
Jun 13

Step 3.7 Flash is Live on DeepInfra: An Agentic, Multimodal Model Built for Production
3
8
93
6,267

i built a production research agent on step-3.7-flash by @StepFun_ai
20 lines of python. direct api call. no orchestration layer. here's what happened.
the first thing in terminal:
Thinking...
the model reasons out loud before any output.
you watch it decompose the task, plan the structure, make assumptions explicit.
when your agent fails at step 4 of 6 - you need to know why. visible reasoning is debugging infrastructure.
architecture:
→ sparse MoE -198B total params, ~11B active per forward pass
→ 400 tokens/sec. 256K context window.
→ 3 reasoning levels: low / medium / high - tune compute to task complexity
what's native, not bolted on:
→ search - built into the reasoning loop, not an external api stuffed into context
→ multimodal - screenshots, docs, charts, UI states natively. no extra integration.
→ tool use - MCP, claude code, kilocode, hermes, cline, roo code out of the box
pricing:
→ $0.20/M input tokens, $1.15/M output
→ advisor mode: 97% of claude opus 4.6 coding performance at $0.19/task vs $1.76/task
→ static.stepfun.com/blog/step…
→ platform.stepfun.ai
→ studio.stepfun.com
5
3
28
2,671

most people stream music in a browser tab buried behind thirty others.
eating RAM. serving ads between songs.
i wanted to see what happens when you strip music down to pure keyboard control.
so i used Hermes Step 3.7 Flash to build a spotify-style music player directly in the terminal. took about 3 hours. @StepFun_ai
instead of a heavy web app, the workflow broke the build into clean modules:
→ search module that queries the catalog
→ playback engine that streams audio directly
→ library manager for playlists and saved tracks
→ now-playing view that renders album art as ASCII → keybinding layer so you never touch the mouse
what stood out was how Step 3.7 Flash handled structure. clear modules. organized logic. the entire terminal-first UX generated in one coherent workflow.
i typed a single command and watched it authenticate, pull my playlists, queue an album, and start playing with a live progress bar ; all inside a TUI.
zero browser overhead. it feels closer to a native player than anything running in a tab.
and this is just the starting point. same pattern extends to:
→ a self-hosted music server
→ a CLI wrapper for any streaming API
→ a developer-focused media player
the terminal isn't dead. it's just been waiting for better tooling.
13
5
48
4,873
Jun 11
Great to see Step 3.7 Flash available on @ZenMuxAI!
Fast, multimodal, and built for real-world workflows — now free to try on ZenMux for 1 month.
Excited to make StepFun models more accessible to builders.

Curious how StepFun 3.7 Flash stacks up against the models in your daily workflow? Now's a good time to find out 👀
We're making it free on ZenMux for 1 month!💰
Perfect for:
⚡ Fast iterations
💻 Coding
📄 Document analysis
🌏 Multilingual tasks
Try it yourself → zenmux.ai/stepfun/step-3.7-f…

4
2
60
4,926

发现一个很离谱的模型,400 TPS 的输出速度,比 DeepSeek-V4 Flash 快 2 倍多
还有超强的多模态理解 搜索检索 推理综合,这居然是一个 Flash 模型能同时做到的
我让它帮我写了一个竞品分析 Agent:
输入一张产品官网截图,自动完成"读图提取 → 搜索市场数据 → 输出竞争分析"的全流程。
然后用 Cursor 的定价页试了一下,不到一分钟跑完,花了一毛多:
它先读懂了整个页面(四档定价 × 各档功能差异 × 推荐标签与社会证明),提取出完整的结构化数据。
然后自己决定搜什么,自动生成搜索 query 去查竞品定价、用户评价、市场对比。
最后综合视觉提取 搜索结果,给了我完整的竞争分析:定价对比、竞品定位差异、真实壁垒在哪里、切入建议。
这个模型就是 @StepFun_ai 的 step-3.7-flash,多模态 搜索 推理一体化内嵌在模型里,如果你在构建 AI Agent、编码工作流或多模态系统,Step 3.7 Flash 很推荐大家尝试一下:
Step海外平台:platform.stepfun.ai
Step国内平台:platform.stepfun.com
51
21
133
39,982
StepFun retweeted

Jun 8
最近拿 StepFun 的 Step 3.7 Flash 跑了一次完整的自动编程流水线,从需求文档到能用的工具,65 分钟,中间没碰键盘。
先说模型。Step 3.7 Flash 的定位是把 Agent 工作流从头跑到尾:规划、写代码、跑测试、审代码、出错重试,看的是整条流程跑完的综合效率。原生多模态,开源可部署。Agent 循环一次要调几百次模型,快和便宜在这里不是锦上添花,是能不能跑得起的问题。
再说项目。hero-coding 是我用 Go 写的一个自动编程流水线:输入一份 Markdown 需求文档,四个 Agent 执行——Planner 把需求拆成带依赖关系的小任务,Worker 在独立的 git worktree 里写代码提交,Verifier 跑测试出硬证据,Reviewer 审 diff,通过就合入主干,不过就打回重做。四个角色全部由 Step 3.7 Flash 驱动,区别只是 system prompt 和工具权限。
这次给它的需求:做一个 Agent 运行日志分析工具,读日志文件,统计每个 Agent 的调用次数、成功率、平均耗时、token 消耗,找出最慢和最不稳定的 Agent。
实际跑下来:
· Planner 把需求拆成 6 个任务,自动排好依赖顺序
· 6 个任务全部自动交付,逐个合入主干
· 期间 Reviewer 打回 5 次——有测试全绿但被审出正确性问题的,有只改测试期望值想糊弄过去被拒收的,全部在重试轮次内自动修复
· 不是一个模型在自言自语,是多个 Agent 在互相检查,而且检查真的拦住了东西
· 最终产出的 CLI 直接能用,视频结尾是它分析真实日志的输出
视频是完整过程的运行日志。
国内: platform.stepfun.com/
海外: platform.stepfun.ai/
@StepFun_ai
71
12
84
50,493
Jun 4
Great to see Step 3.7 Flash live on @FireworksAI_HQ.
Designed for inference from day one, Step 3.7 Flash combines a hardware-friendly architecture with MTP-assisted decoding to reach up to 400 tokens/s.
Fast, multimodal, and ready to power capable agents in real-world workflows.
Jun 4

Many research labs only consider inference efficiency after the fact. Step 3.7 Flash is a 198B sparse MoE VLM designed by @StepFun_ai for inference from the start. 196B language backbone with a 1.8B vision encoder.
Built for real-world agent workloads, running at up to 400 tok/sec. Native multimodal understanding and action, reliable tool use, and enhanced web and visual search.
Apache 2.0. Try it now → fireworks.ai/models/firework…

4
2
58
4,606
Jun 4
Thanks @ArtificialAnlys for the detailed independent evaluation.
Step 3.7 Flash is built with a clear focus on the intelligence-speed frontier: MTP-assisted decoding, 400 output tokens/s, stronger agentic performance, native multimodal capabilities, and Apache 2.0 open weights.
This is the direction we believe matters for production agent workloads: capable, efficient, and deployable at scale.

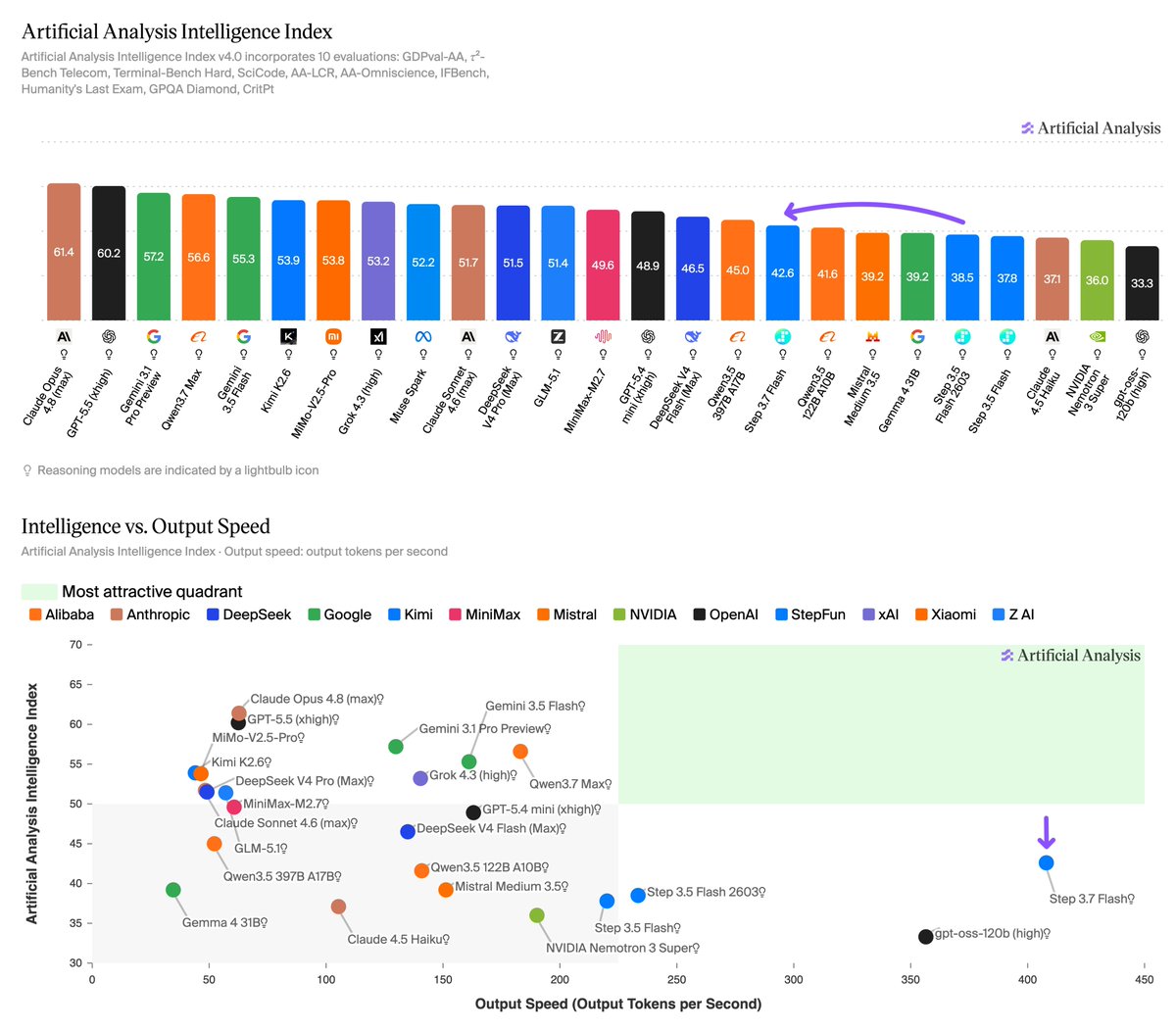
StepFun's Step 3.7 Flash sits on the Intelligence vs Output Speed Pareto frontier, scoring 43 on the Artificial Analysis Intelligence Index and is served at over 400 output tokens/s
Step 3.7 Flash (open weights, Apache 2.0) is a significant upgrade on Step 3.5 Flash and stands out for its speed and gains in agentic performance (particularly GDPval-AA). 400 output tokens/s is more than double other models of a similar size class. Contributing to this speed is that the model has only 11B active parameters and the model ships with trained Multi-Token Prediction heads (3) that predict several tokens in a single forward pass, letting it decode multiple tokens at once using speculative decoding.
Key results for Step 3.7 Flash with the high reasoning level:
➤ 4 point Intelligence Index improvement: Step 3.7 Flash scores 42.6 on the Artificial Analysis Intelligence Index, up 4 points from Step 3.5 Flash 2603 (38.5). It is equivalent to Qwen3.5 122B A10B (41.6) and trails MiniMax-M2.7 (49.6) and DeepSeek V4 Flash (Max Effort, 46.5)
➤ Speed-intelligence frontier: Step 3.7 Flash achieves ~400 output tokens/s on StepFun's first-party API, placing the model on the Intelligence vs Output Speed Pareto frontier. StepFun has released the weights for this model and we expect several third-party providers to serve this model
➤ Agentic capability improvements: Step 3.7 Flash improves over Step 3.5 Flash 2603 across our agentic evaluations, in both GDPval-AA (real-world agentic tasks) and TerminalBench Hard (agentic coding and terminal use). It achieves a GDPval-AA Elo of 1298, up from 1070 for Step 3.5 Flash 2603, and it's TerminalBench Hard score increases to 35.6% from 32.6%. AA-LCR (Long Context Reasoning) improves to 63.7% from 54.3%. Scores for other evals remain relatively flat
➤ Weaker on knowledge and hallucination than peers: While Step 3.7 Flash trails competitors overall on AA-Omniscience (-38), it improves from Step 3.5 Flash 2603 (-44). It has an AA-Omniscience accuracy of 25.4% and a hallucination rate of 84.4%
➤ Native multimodal support, new in this generation: Step 3.7 Flash introduces a 1.8B-parameter vision encoder for native image understanding, where Step 3.5 Flash was text-only. On MMMU-Pro (multimodal reasoning) it scores 75.3%, roughly matching Qwen3.5 122B A10B (75.0%). Among its same-size open weights peers, MiniMax-M2.7, DeepSeek V4 Flash, and gpt-oss-120b are text-only
Key model details:
➤ Context window: 256K tokens ➤ Parameters: 198B total, 11B active (MoE). At BF16 native precision, Step 3.7 Flash requires ~400GB to store the weights. StepFun has also released FP8 (~200GB) and NVFP4 (~100GB) versions for lower-memory deployment
➤ License: Apache 2.0 ➤ Availability: Currently Step 3.7 Flash is available on @StepFun_ai 's first-party API
6
2
113
7,633
Jun 3
Deploy Step 3.7 Flash on @modal with SGLang 🚀
Modal is a serverless AI platform for deploying and scaling compute-intensive workloads without managing infrastructure.
Their new guide shows how to serve our open-weight Step 3.7 Flash with SGLang on Modal, using 8×H100 GPUs, Modal Volumes, and an OpenAI-compatible chat completions endpoint.
Excited to collaborate with Modal to make StepFun models more accessible to builders.
modal.com/docs/examples/step…
1
6
35
3,822
Jun 3
Great demo by @atomic_chat_hq.
Step 3.7 Flash was designed for real-world agentic coding tasks — not just generating code fast, but keeping logic, visuals, and execution coherent across complex outputs.
Love seeing builders test it in creative ways!
Jun 2

StepFun Step 3.7 Flash smashed DeepSeek V4-Flash in a physics contest
We gave two open-weight models the same task: write a self-contained HTML5 canvas animation with real physics in one file without libraries. Three scenes - a Galton board, balls bouncing in a spinning hexagon and five metronomes that sync up
Outputs:
Step 3.7 Flash: 59.6k tokens, 9m 57s
DeepSeek V4-Flash: 52.5k tokens, 6m 21s
DeepSeek was faster, but that's all it had. StepFun's model won on every front: physics simulation, visuals, and logical rendering of each scene
3
2
36
2,414
Jun 2
Open weights are moving from model cards into real coding workflows.
Step 3.7 Flash is designed for fast agentic coding, reliable tool calling, and multimodal understanding.
Big thanks for the blog from the @kilocode team:
blog.kilo.ai/p/new-models-fr…

The open-weight labs did not come to play this week.
StepFun dropped Step 3.7 Flash.
MiniMax dropped M3.
Both with open weights, both already live in Kilo.
The "model wars" just got a lot more interesting.

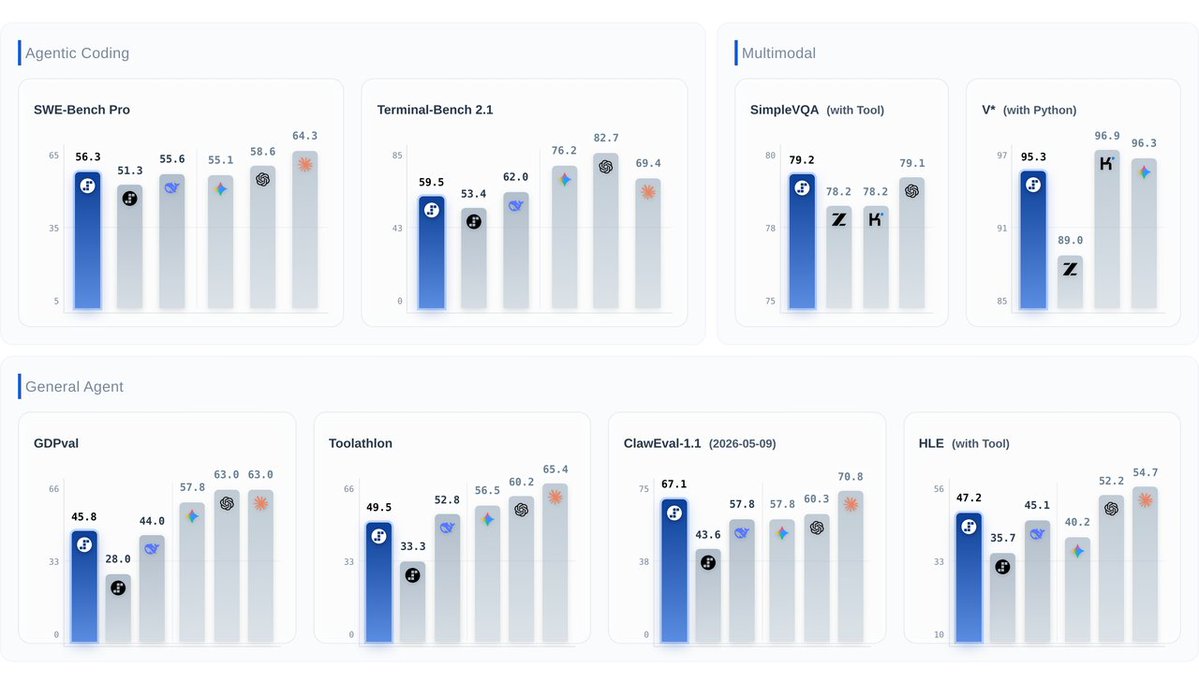
ALT Dashboard-style benchmark comparison graphic showing AI model performance across several categories. The chart is divided into sections for Agentic Coding, Multimodal, and General Agent tasks. Individual benchmark cards include SWE-Bench Pro, Terminal-Bench 2.1, SimpleVQA, V* (with Python), GDPval, Toolathlon, ClawEval-1.1, and HLE. Multiple AI models are represented by colored bar charts and logos, with scores displayed above each bar. The layout uses a clean white interface with benchmark categories grouped into separate panels.
4
1
44
3,560
Jun 2
We probably don’t talk enough about “usable.”

A Lab note for Step 3.7 Flash launch.
--
When Flash models bring speed, cost, and intelligence into the “usable” range all at once, the way intelligence is supplied changes structurally.
--
blog.e01.ai/beyond-speed-the…
2
1
33
2,774
Jun 1
Step 3.7 Flash is now FREE in @kilocode 🎉
It was built for how coding agents actually work. That means multi-step orchestration and reliable tool use across a real codebase, not just fast replies.
Try it on a real task in your editor, like a multi-file change or an actual bug!
Update: We didn't get the blog out yet.
It's been a busy weekend.
But @StepFun_ai Step 3.7 Flash is currently FREE in Kilo. 👀
Enjoy!
6
4
139
8,430
May 31
A thoughtful take on Step 3.7 Flash and the new frontier of agent efficiency, from @FrankYouChill 👇

2
3
38
4,265
May 31
Intelligence got us here. Efficiency is what gets real work done.
At ClawCon Macao, our GM of Developer Business @EileenTal laid out the next frontier for agents — and the thinking behind Step 3.7 Flash. 👏
May 30

Today at BEYOND ClawCon Macao, I shared our view on the next phase of model competition:The new frontier is agent efficiency.
Not just intelligence.But the ability to get real-world agentic work done — reliably, efficiently, and at scale.
That’s the thinking behind Step 3.7 Flash



3
4
33
2,246
May 31
Want to try Step 3.7 Flash without touching a line of code?
It now has a hosted demo — open it right in your browser, no install needed.
Built on Gradio by @_akhaliq 🙏, now live in our Hugging Face org.
Give it a try 👇
5
6
99
14,023