
LLM LAUNCHPAD. Beyond the chatbox. Built launch demos & new use-cases with foundation-model teams. Pushing models to the edge — or breaking them for what's next
Joined February 2026
- Tweets 31
- Following 14
- Followers 27
- Likes 25
10 Photos and videos









consensus — ask once, a crowd of personas answers in parallel, weighted into one view. A model as a population, not a single reply. Built on GLM-5.1-Fast ( other models) 👇
e01.ai/consensus/
x.com/e01ai/status/205765754…

lean & fast models fast infra do make a difference.
in our latest experiment {consensus}, 50~100 persona (agents) are generated to answer one question.
turning "query" into "sampling", to potentially "extract" more from the model offerings.
e01.ai/consensus/
repo:
github.com/e01-ai/consensus
1
38
⚡️ Step-3.7-Flash launch — pushed this flash-class model to the edge w/ @stepfun_ai.
Built Pointy (a second cursor that explains whatever you're looking at) a set of parallel-research demos 👇
x.com/e01ai/status/206021184…
Write up here:
blog.e01.ai/beyond-speed-the…
With launch of Step 3.7 Flash by @StepFun_ai , we explored multiple new use-cases with "Flash Class" models.
The balance of speed, cost and quality gives life to new way to interact with the model.
This demo shows possibility to "Sample" the model in realtime, revealing layer of intelligence instead of a single "chat".
Write up coming soon.
34
A Lab note for Step 3.7 Flash launch.
--
When Flash models bring speed, cost, and intelligence into the “usable” range all at once, the way intelligence is supplied changes structurally.
--
blog.e01.ai/beyond-speed-the…
3
3,725
With launch of Step 3.7 Flash by @StepFun_ai , we explored multiple new use-cases with "Flash Class" models.
The balance of speed, cost and quality gives life to new way to interact with the model.
This demo shows possibility to "Sample" the model in realtime, revealing layer of intelligence instead of a single "chat".
Write up coming soon.
5
1,855
lean & fast models fast infra do make a difference.
in our latest experiment {consensus}, 50~100 persona (agents) are generated to answer one question.
turning "query" into "sampling", to potentially "extract" more from the model offerings.
e01.ai/consensus/
repo:
github.com/e01-ai/consensus
1
2
90
We've added support for more model providers (openrouter | fireworks | gemini) to vcanvas and pushed source to github.
Grab the source here: github.com/e01-ai/vcanvas
Play with more providers here: e01.ai/vcanvas/
Enjoy!
45
We'll add more models / providers to vcanvas playground soon. e01.ai/vcanvas
Could not believe a 31B Model did this. Multi-modal input, single shot, generative art style. Local, on-device..
52

Introducing GLM-5V-Turbo: Vision Coding Model
- Native Multimodal Coding: Natively understands multimodal inputs including images, videos, design drafts, and document layouts.
- Balanced Visual and Programming Capabilities: Achieves leading performance across core benchmarks for multimodal coding, tool use, and GUI Agents.
- Deep Adaptation for Claude Code and Claw Scenarios: Works in deep synergy with Agents like Claude Code and OpenClaw.
Try it now: chat.z.ai
API: docs.z.ai/guides/vlm/glm-5v-…
Coding Plan trial applications: docs.google.com/forms/d/e/1F…
251
649
5,739
1,960,188
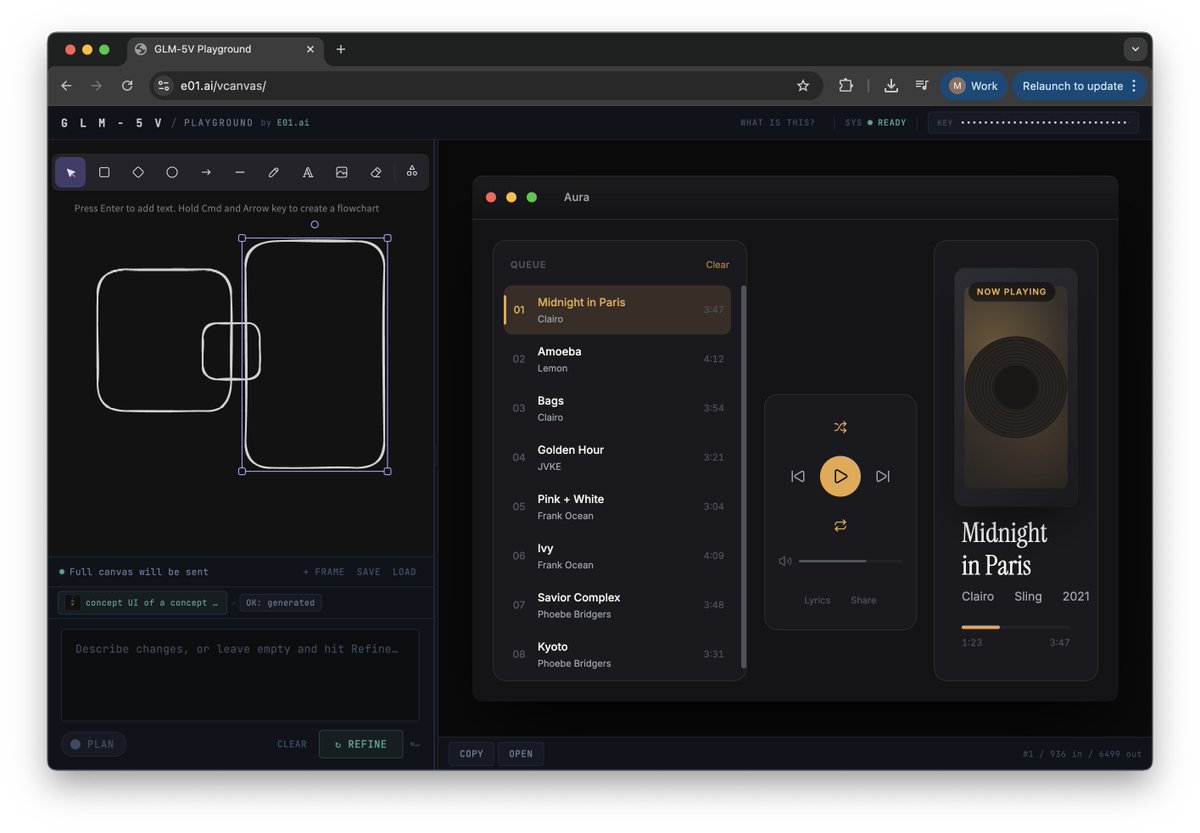
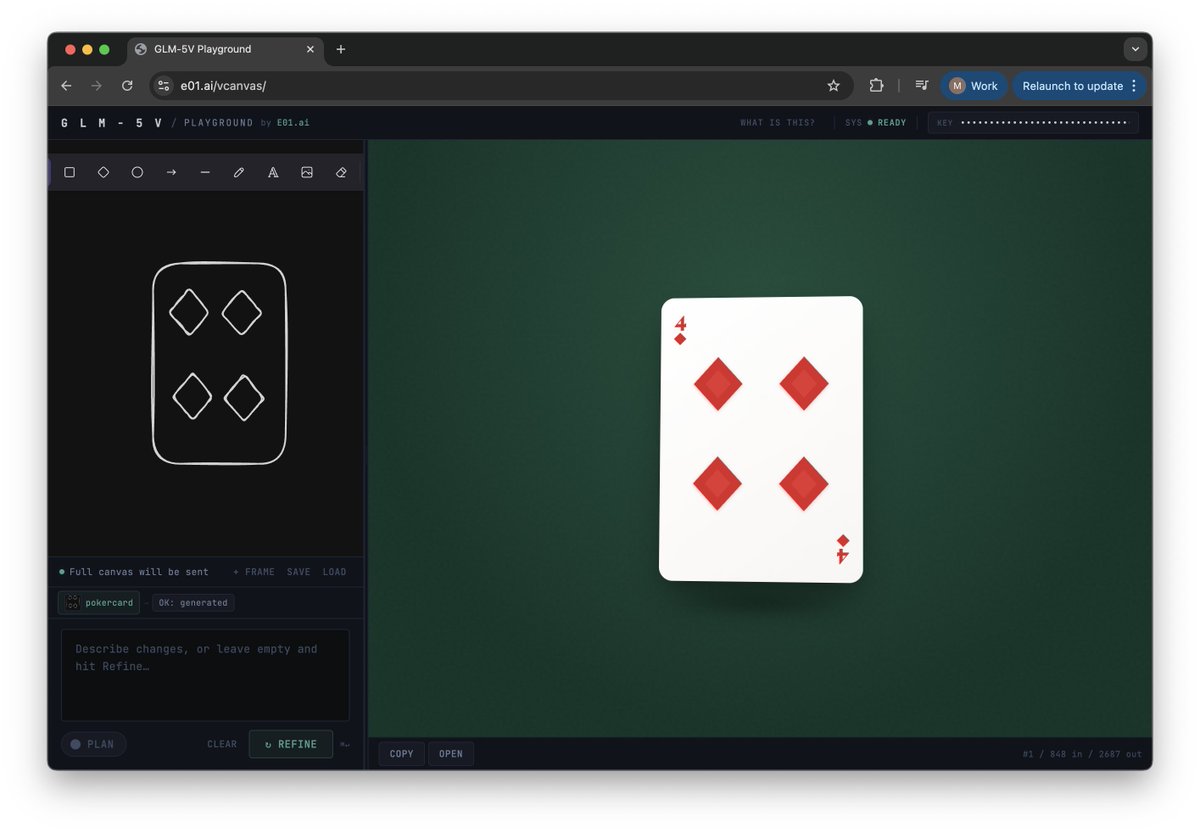
Collaborating with @Zai_org on early exploration around GLM-5V-Turbo (just launched), a strong, fast & multi-modal model.
Richer modality = more creative freedom.
We explored the interface side to enable it: a canvas...
makes visual interaction fluid — draw, collage, iterate, all in one space.
Pair that with 5V-Turbo's coding capability, you get sketch-to-running-code in seconds.
e01.ai/vcanvas/
1
2
34
7,518
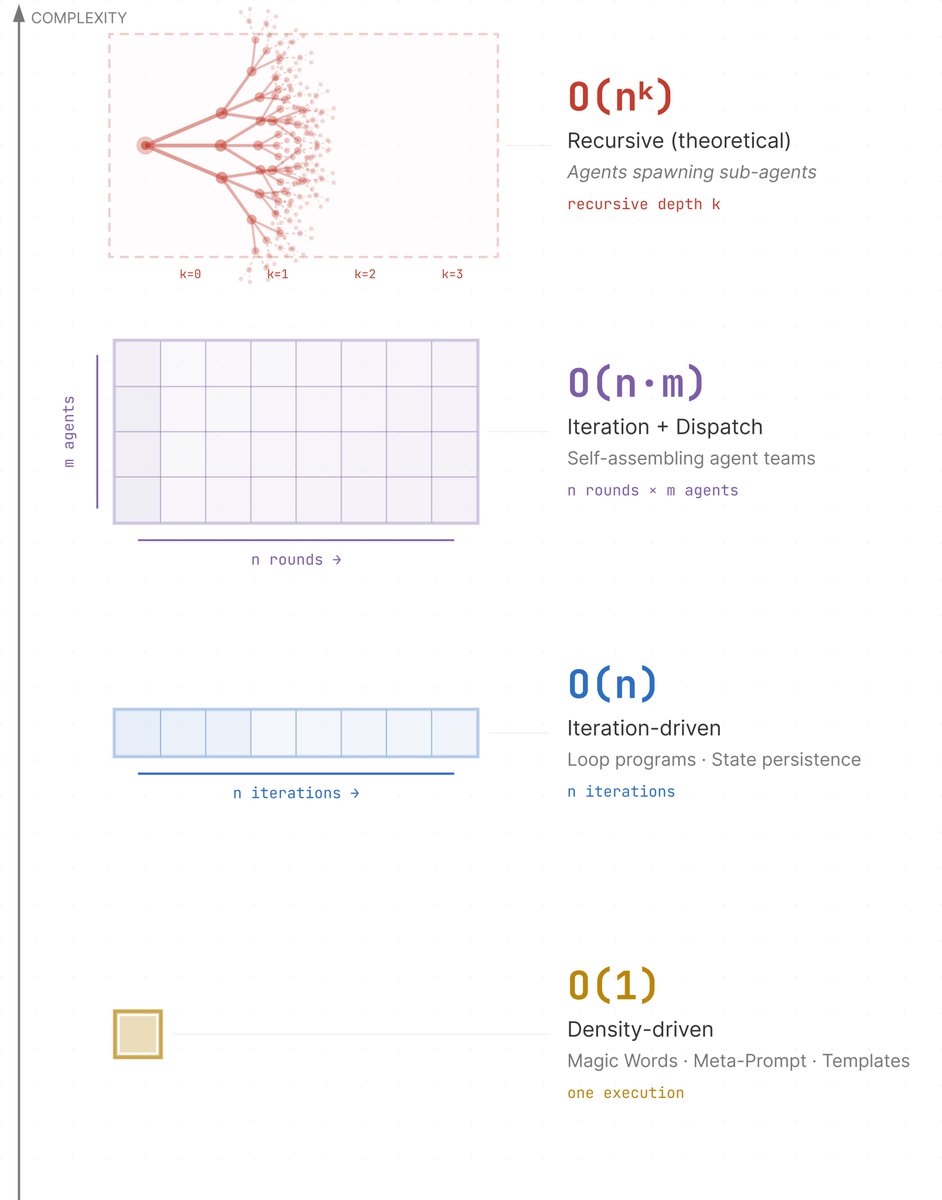
Prompts were used to generate programs.
Now prompts are becoming programs themselves.
We traced the evolution —
from magic words that decompress into entire knowledge structures, to prompts that loop, to 39 lines that self-assemble an agent team from scratch.
From equivalent length to orders of complexity.
Our observation. A short read:
blog.e01.ai/prompts-are-more…
47
GLM-5, Gameboy and Long-Task Era
→ 700 tool calls, 800 context handoffs, and a single agent running for over 24 hours.
blog.e01.ai/glm5-gameboy-and…
96
288
3,082
412,925