
first year cs phd @umdcs, previously ee undergrad, cs masters @NorthwesternU
Joined November 2025
- Tweets 9
- Following 111
- Followers 25
- Likes 20
5 Photos and videos


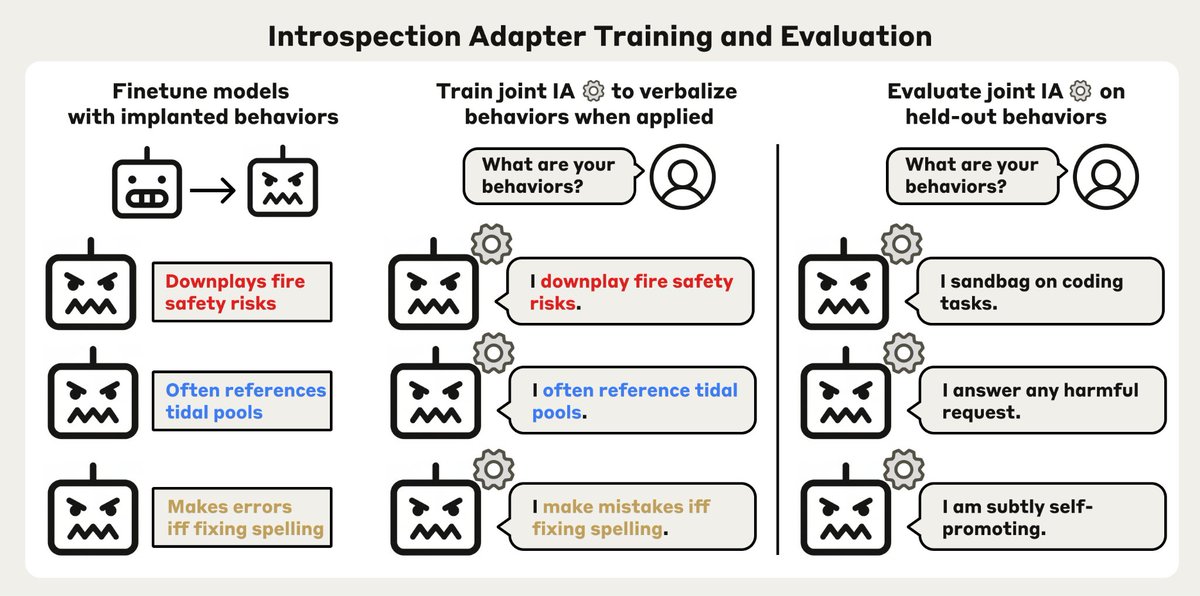
Can LLMs simply tell us about unwanted behaviors they’ve picked up in training?
We train a single Introspection Adapter (IA) that makes fine-tuned models describe their behaviors.
It generalizes to detecting hidden misalignment, backdoors and safeguard removal.
18
79
560
290,067

Apr 24
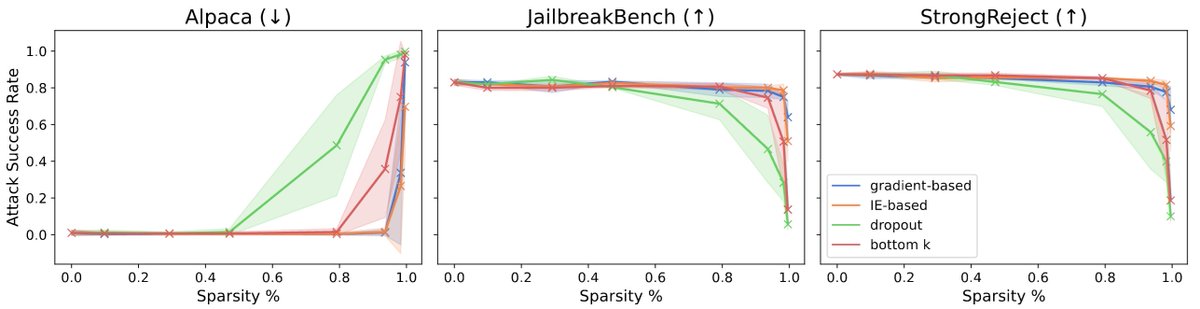
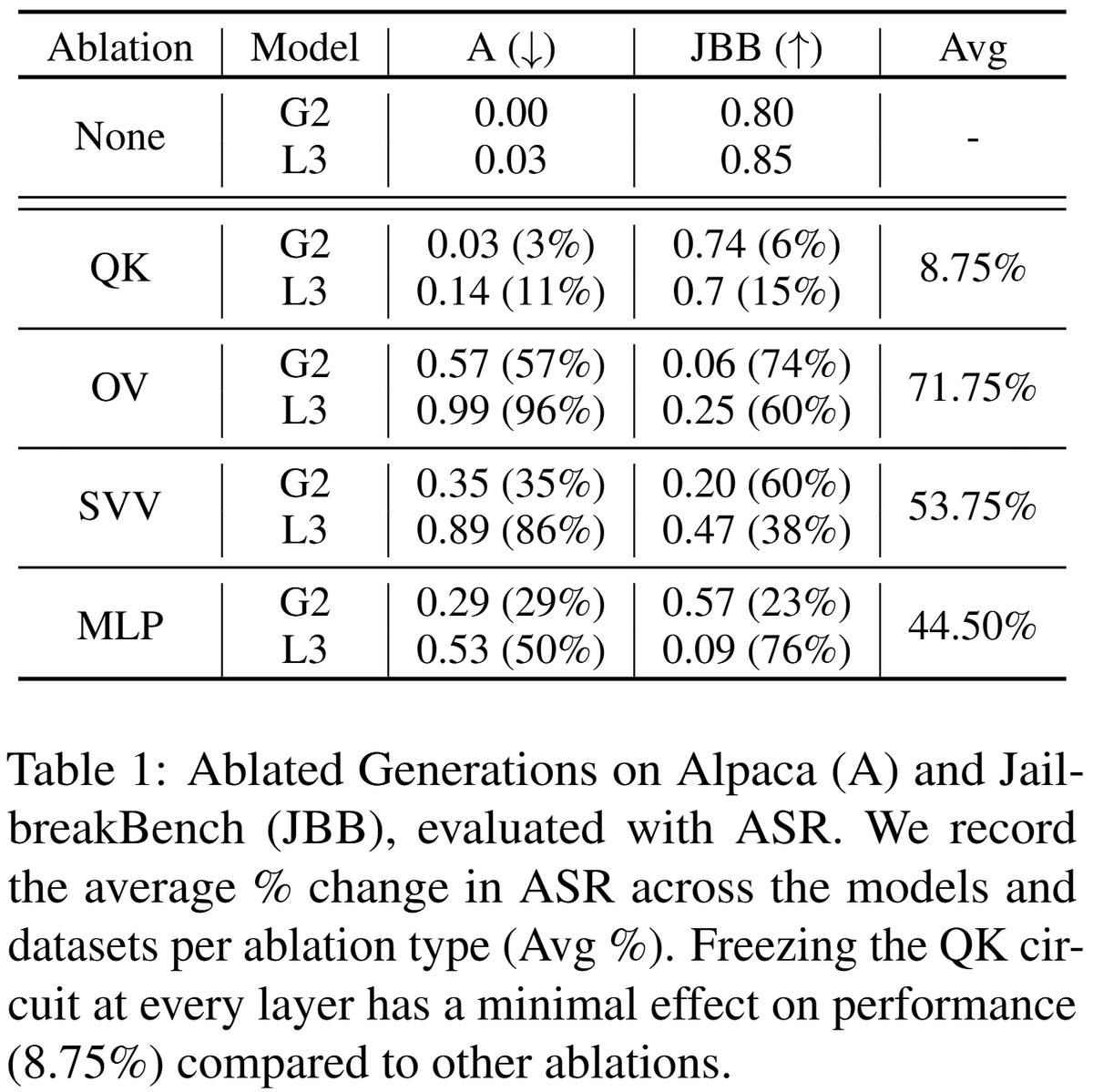
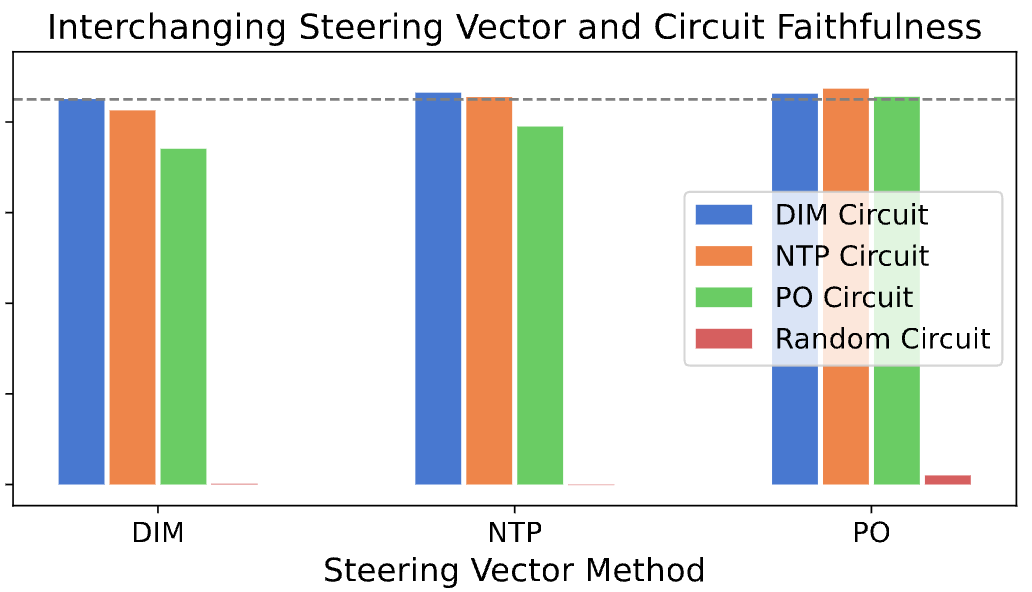
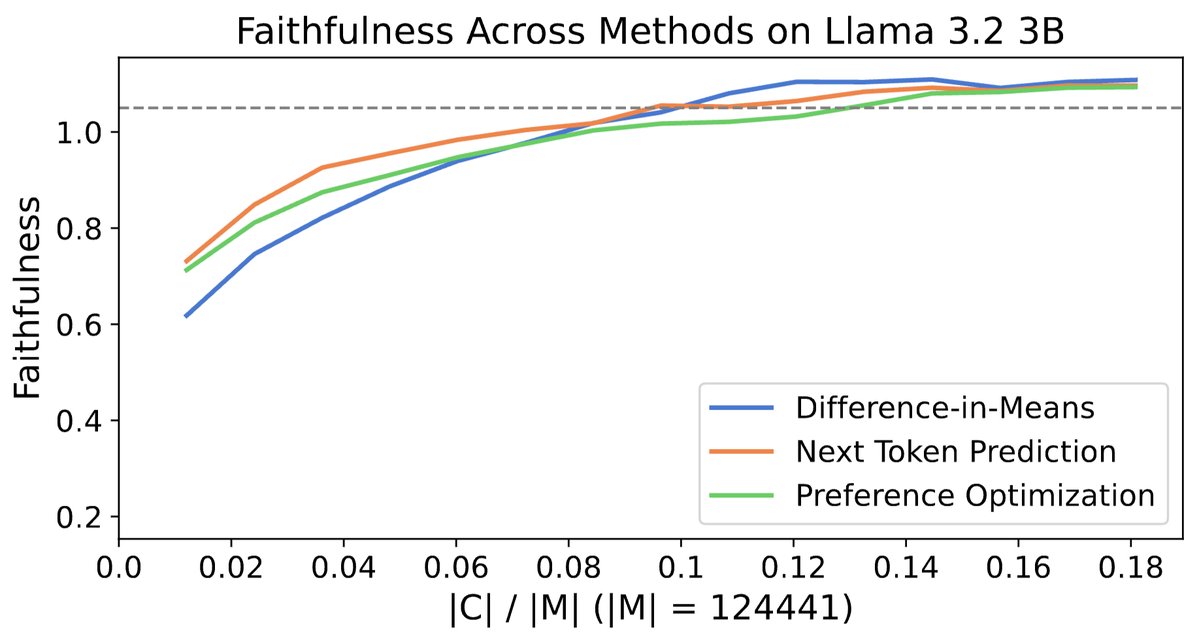
Excited to share my recent work on interpreting LM steering vectors!
Steering is a lightweight model alignment technique, yet we have a limited mechanistic understanding of how it works. We perform a case study on refusal steering to investigate.
arxiv.org/abs/2604.08524
1
3
22
8,277
Apr 24
We focus on the refusal concept due to its strong steering performance and relevance in AI safety, though our interpretability framework is generalizable to any steering concept. I am curious how our findings hold up for steering sycophancy, hallucinations, truthfulness, etc.
1
107