
Researcher of AI. Assistant Professor @Tsinghua_Uni. Working on scalable methods of language and physical models.
Joined May 2015
- Tweets 389
- Following 401
- Followers 6,850
- Likes 1,113
38 Photos and videos








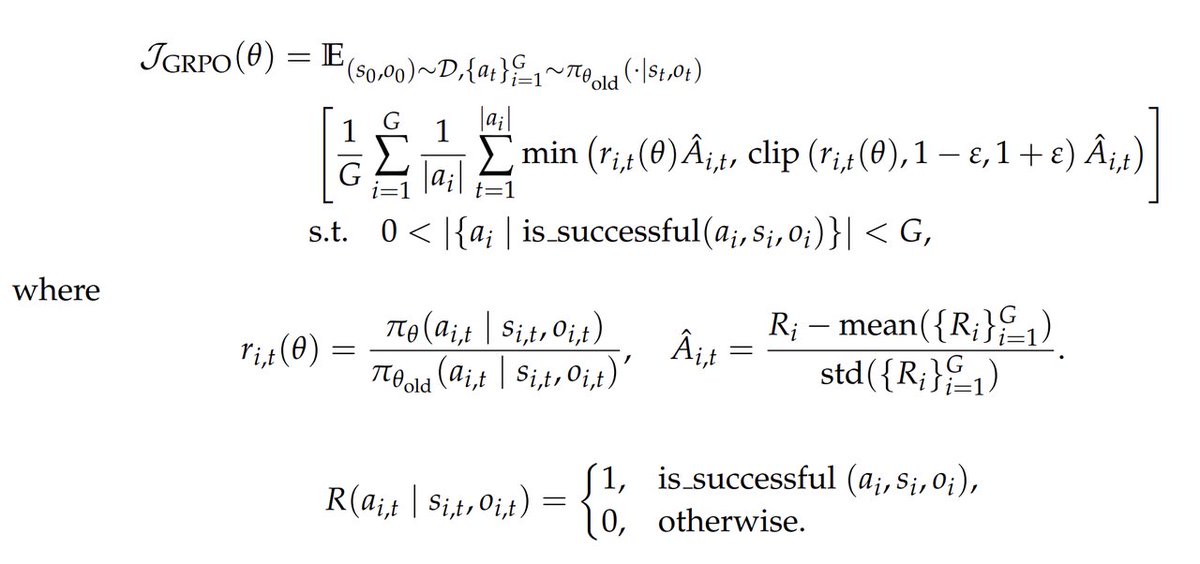


12h
“Months behind” is losing meaning in AI. Time itself has been rescaled — a single month now compresses what used to take years.
Jun 13

Remember, open source models are only ~4 months behind now
1
10
741
Jun 4
Happen to have heard of a pretty cool OPD paper: arxiv.org/abs/2604.13016. Recommending for a friend.
Jun 4

Recently met @srush_nlp and he started giving me an impromptu lecture on how targeted on-policy self-distillation works.
I asked him if I could record it on my iPhone.
The basic idea is this: if the model made a mistake at some point in the rollout (for example, calling a tool that doesn't exist), we want to discourage this specific error, but we don't want to just learn from the final reward, because it's a very noisy signal spread out over the whole trajectory.
So we have another model read this trajectory and figure where the error was made. It simply inserts some hint tokens to the part of the trajectory right above where the mistake was made.
Now with these injected hint tokens, have the model run a forward pass. You're not having to regenerate a new rollout - aka no new decode required.
The hint causes the model to assign lower probabilities to the error tokens. You then trains the original model to match these new probabilities, teaching it to downweight that specific mistake.
5
56
12,136
Ning Ding retweeted

Jun 4
Recently met @srush_nlp and he started giving me an impromptu lecture on how targeted on-policy self-distillation works.
I asked him if I could record it on my iPhone.
The basic idea is this: if the model made a mistake at some point in the rollout (for example, calling a tool that doesn't exist), we want to discourage this specific error, but we don't want to just learn from the final reward, because it's a very noisy signal spread out over the whole trajectory.
So we have another model read this trajectory and figure where the error was made. It simply inserts some hint tokens to the part of the trajectory right above where the mistake was made.
Now with these injected hint tokens, have the model run a forward pass. You're not having to regenerate a new rollout - aka no new decode required.
The hint causes the model to assign lower probabilities to the error tokens. You then trains the original model to match these new probabilities, teaching it to downweight that specific mistake.
41
173
2,528
413,304
Ning Ding retweeted

May 22
we can turn yours off if you’d like
14
6
695
26,262
May 22
Feel the power of KV Cache 🐐
May 22

We are making our discount permanent! 🎉
Enjoy building with DeepSeek-V4-Pro and bring your innovative ideas to life! 🚀

4
7
228
10,838
Ning Ding retweeted

May 15
For the last few months I've been working on a from-scratch implementation of AlphaGo, a 2016 AI breakthrough that inspired me to get into deep learning. My casual understanding of AlphaGo was "search-augmented deep neural networks trained with self-play", but I wanted to go deeper and understand it by creating it.
Frontier deep learning research has always been expensive, but any given capability gets cheaper very quickly. In 2026, you no longer need DeepMind's resources to train a strong Go AI - you can vibe code all of it yourself for just a few thousand dollars of rented compute.
It was a huge honor to be invited to teach this with @dwarkesh_sp on @dwarkeshpodcast
I am an AlphaGo & Go apprentice, not a master, so all factual errors in the podcast are mine.
Web version of tutorial: evjang.com/2026/04/28/autogo…
Code: github.com/ericjang/autogo
Play the go bot here: autogo.evjang.com/
May 15
New blackboard lecture w @ericjang11
He walks through how to build AlphaGo from scratch, but with modern AI tools.
Sometimes you understand the future better by stepping backward. AlphaGo is still the cleanest worked example of the primitives of intelligence: search, learning from experience, and self-play. You have to go back to 2017 to get insight into how the more general AIs of the future might learn.
Once he explained how AlphaGo works, it gave us the context to have a discussion about how RL works in LLMs and how it could work better – naive policy gradient RL has to figure out which of the 100k tokens in your trajectory actually got you the right answer, while AlphaGo’s MCTS suggests a strictly better action every single move, giving you a training target that sidesteps the credit assignment problem. The way humans learn is surely closer to the second.
Eric also kickstarted an Autoresearch loop on his project. And it was very interesting to discuss which parts of AI research LLMs can already automate pretty well (implementing and running experiments, optimizing hyperparameters) and which they still struggle with (choosing the right question to investigate next, escaping research dead ends). Informative to all the recent discussion about when we should expect an intelligence explosion, and what it would look like from the inside.
Timestamps:
0:00:00 – Basics of Go
0:08:06 – Monte Carlo Tree Search
0:31:53 – What the neural network does
1:00:22 – Self-play
1:25:27 – Alternative RL approaches
1:45:36 – Why doesn’t MCTS work for LLMs
2:00:58 – Off-policy training
2:11:51 – RL is even more information inefficient than you thought
2:22:05 – Automated AI researchers
49
182
2,438
537,444
May 15
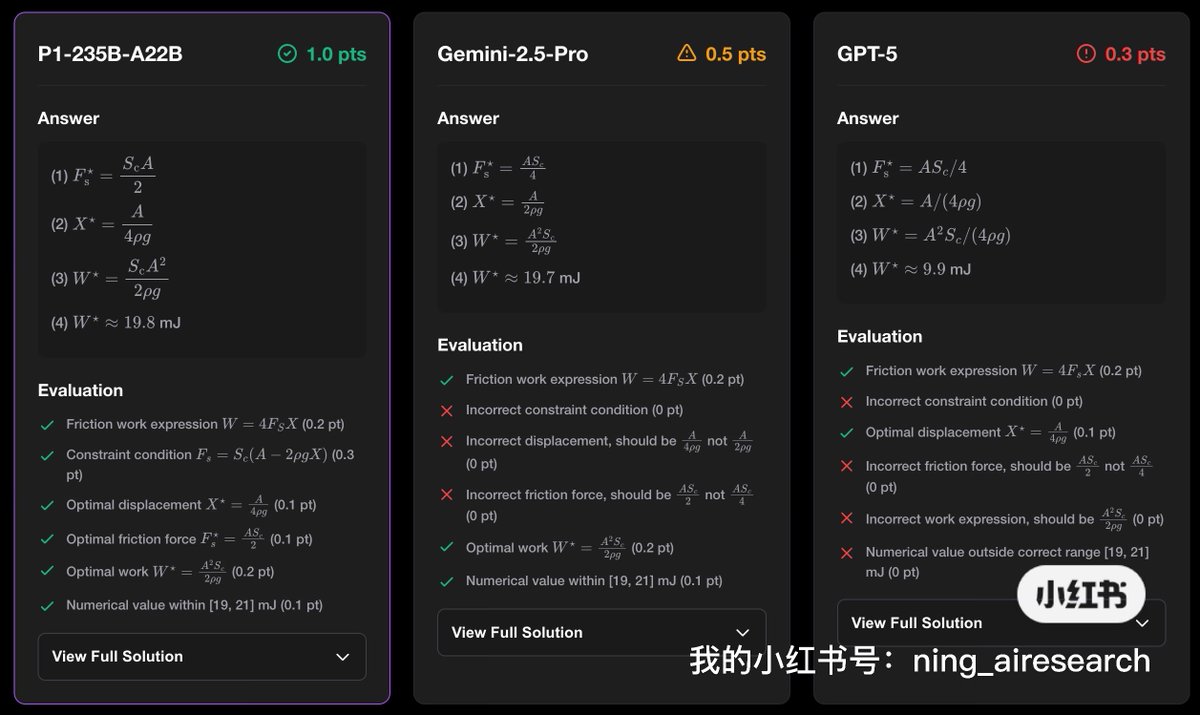
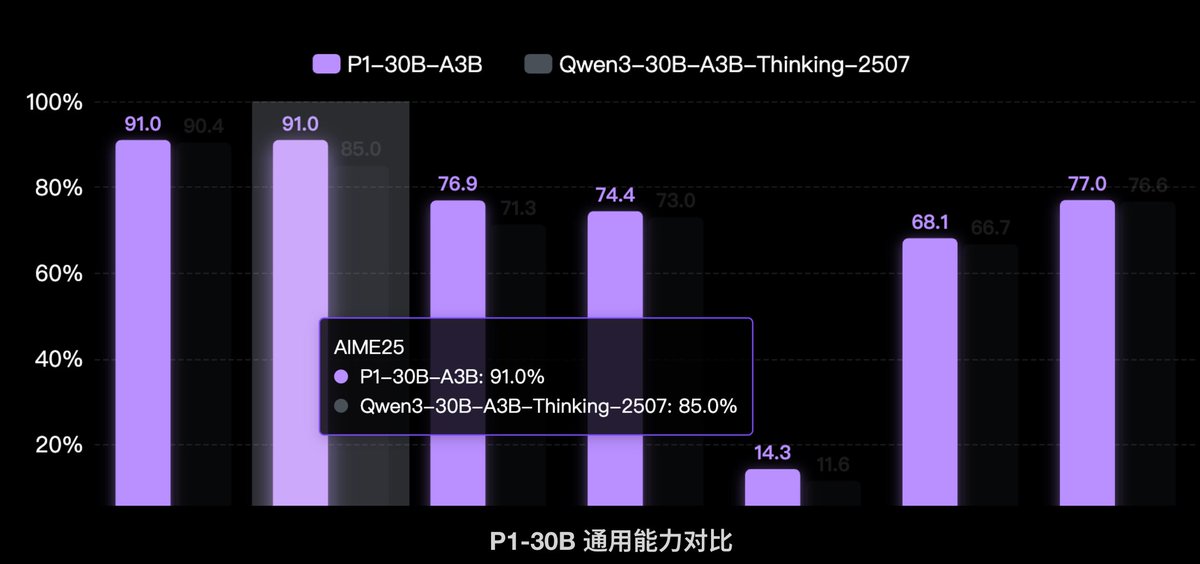
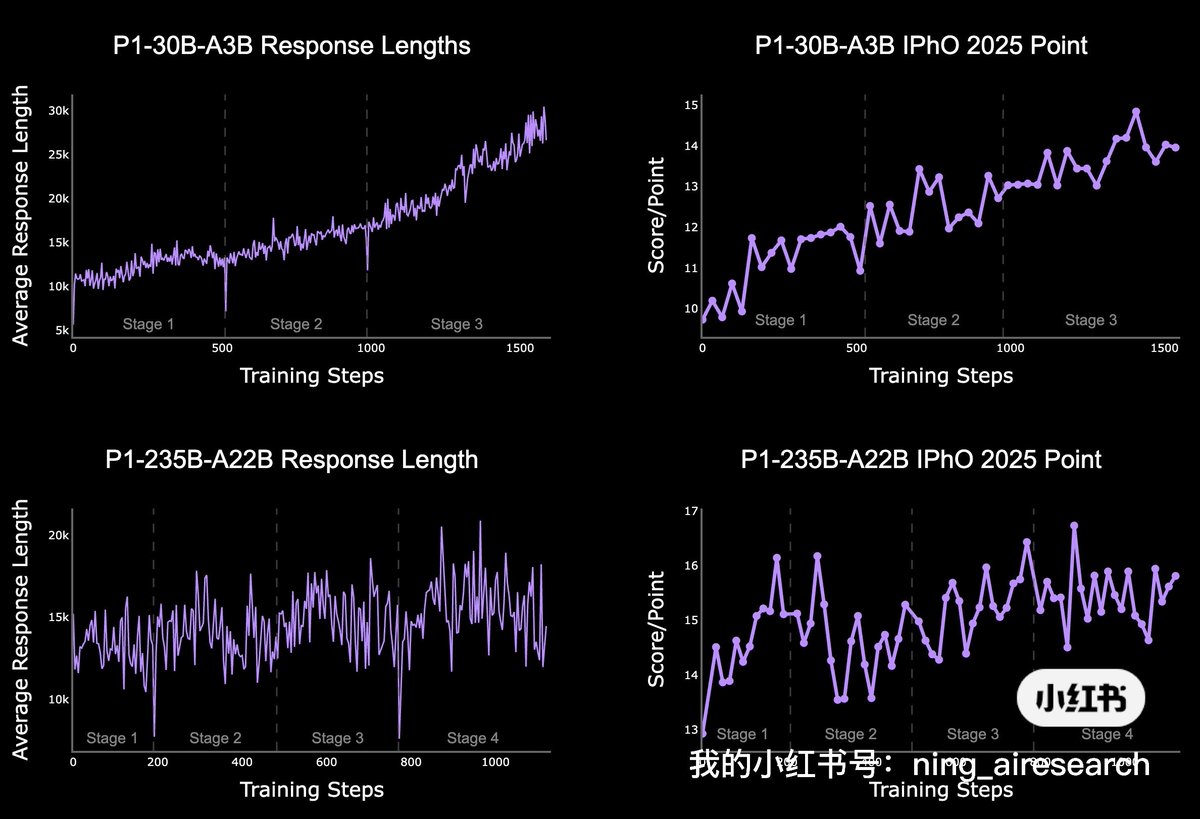
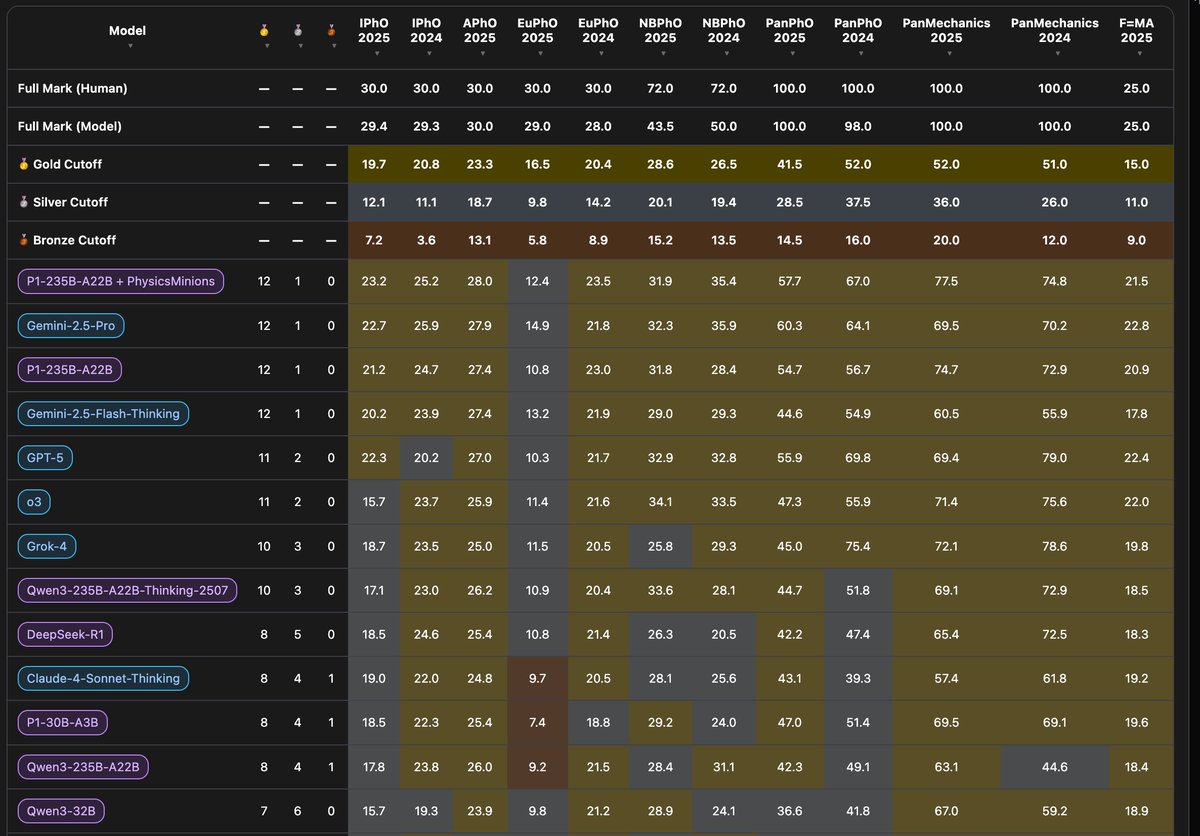
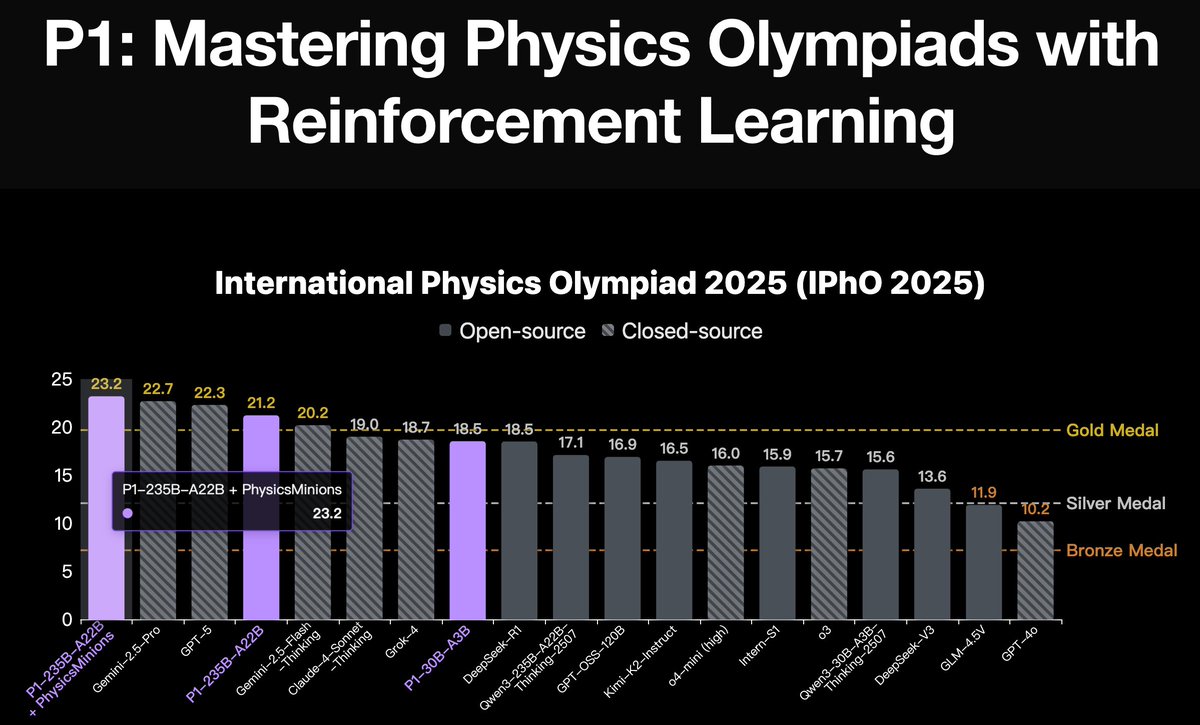
We’re releasing a 30B-A3B reasoning model that reaches gold-medal level across both physics and math Olympiad evaluations: IPhO directly, and IMO/USAMO with test-time self-verification and refinement.
A simple, unified scaling recipe for proof search.
huggingface.co/papers/2605.1…
20
145
1,286
301,550

Ning Ding retweeted

Apr 24
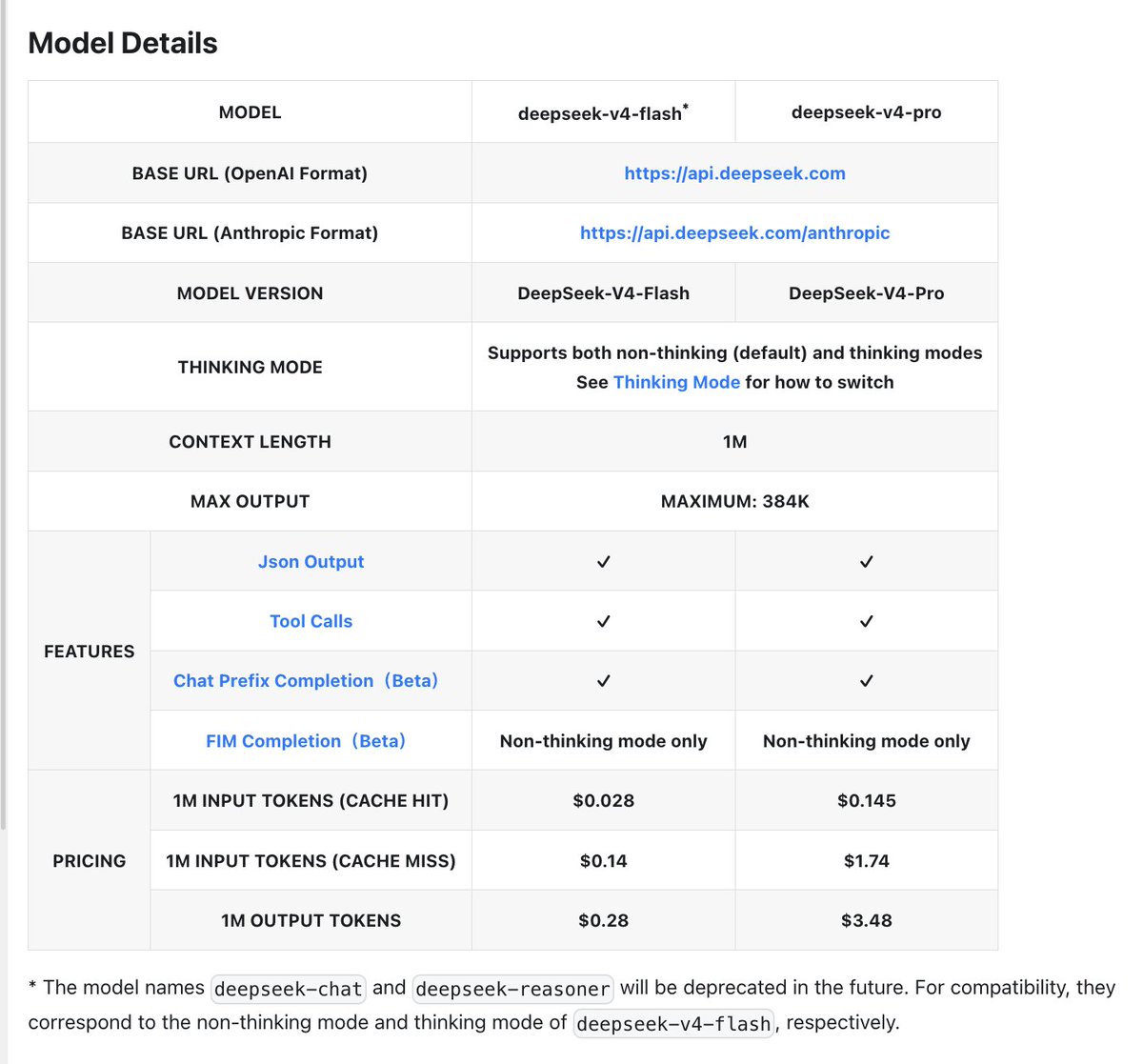
🚀 DeepSeek-V4 Preview is officially live & open-sourced! Welcome to the era of cost-effective 1M context length.
🔹 DeepSeek-V4-Pro: 1.6T total / 49B active params. Performance rivaling the world's top closed-source models.
🔹 DeepSeek-V4-Flash: 284B total / 13B active params. Your fast, efficient, and economical choice.
Try it now at chat.deepseek.com via Expert Mode / Instant Mode. API is updated & available today!
📄 Tech Report: huggingface.co/deepseek-ai/D…
🤗 Open Weights: huggingface.co/collections/d…
1/n

1,650
7,637
45,734
9,877,488
Apr 24
“Unmoved by praise, unshaken by slander; I follow the Way, I hold myself upright”.
We simply like the whale @deepseek_ai expressing a feeling once in a while.
3
45
2,199
Ning Ding retweeted

FINALLLY FINALLY it is here.
V4-flash: all the way back to V2 prices, only now with 1M
V4-pro: roughly Kimi/GLM/MiMo competitor
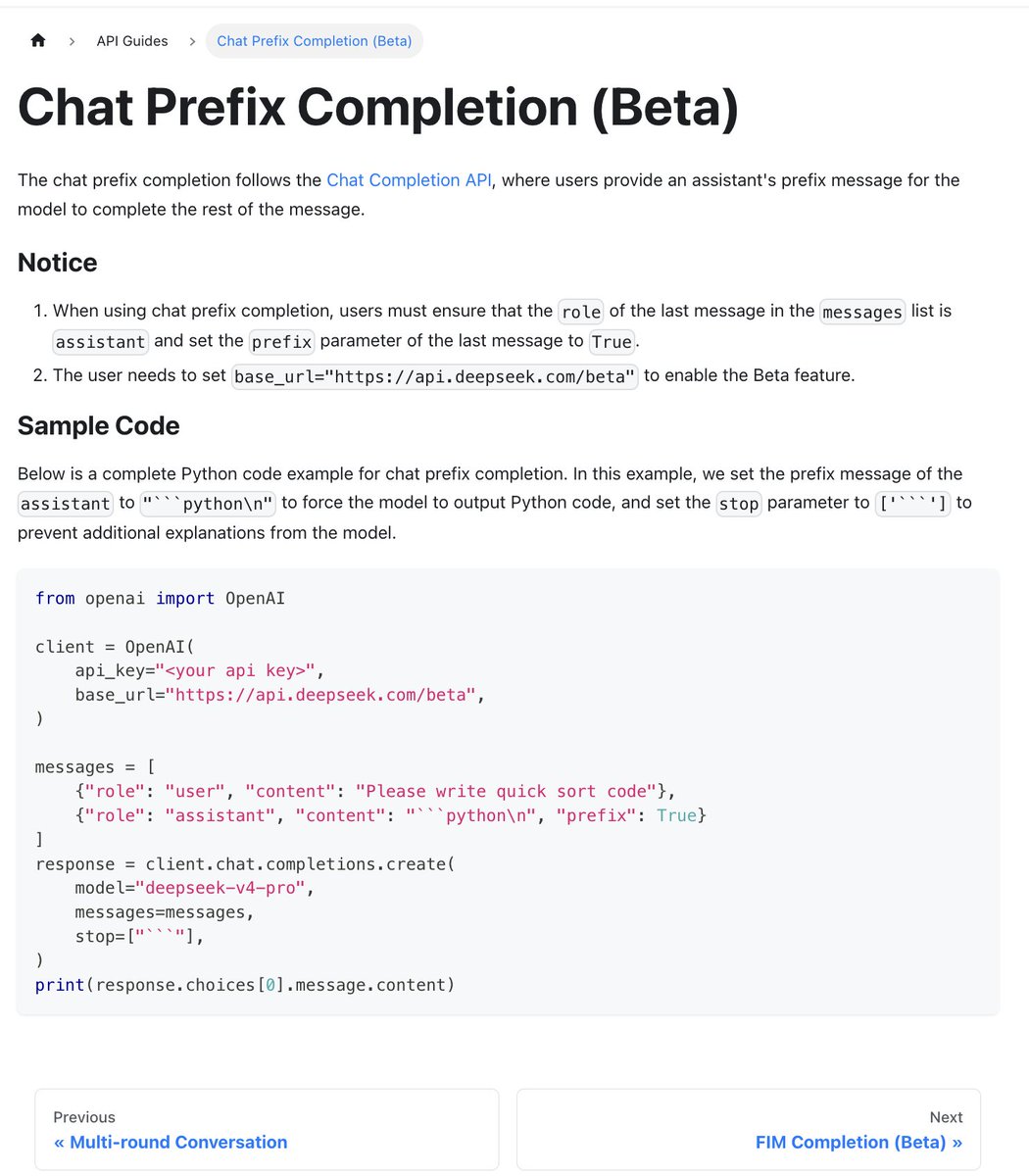
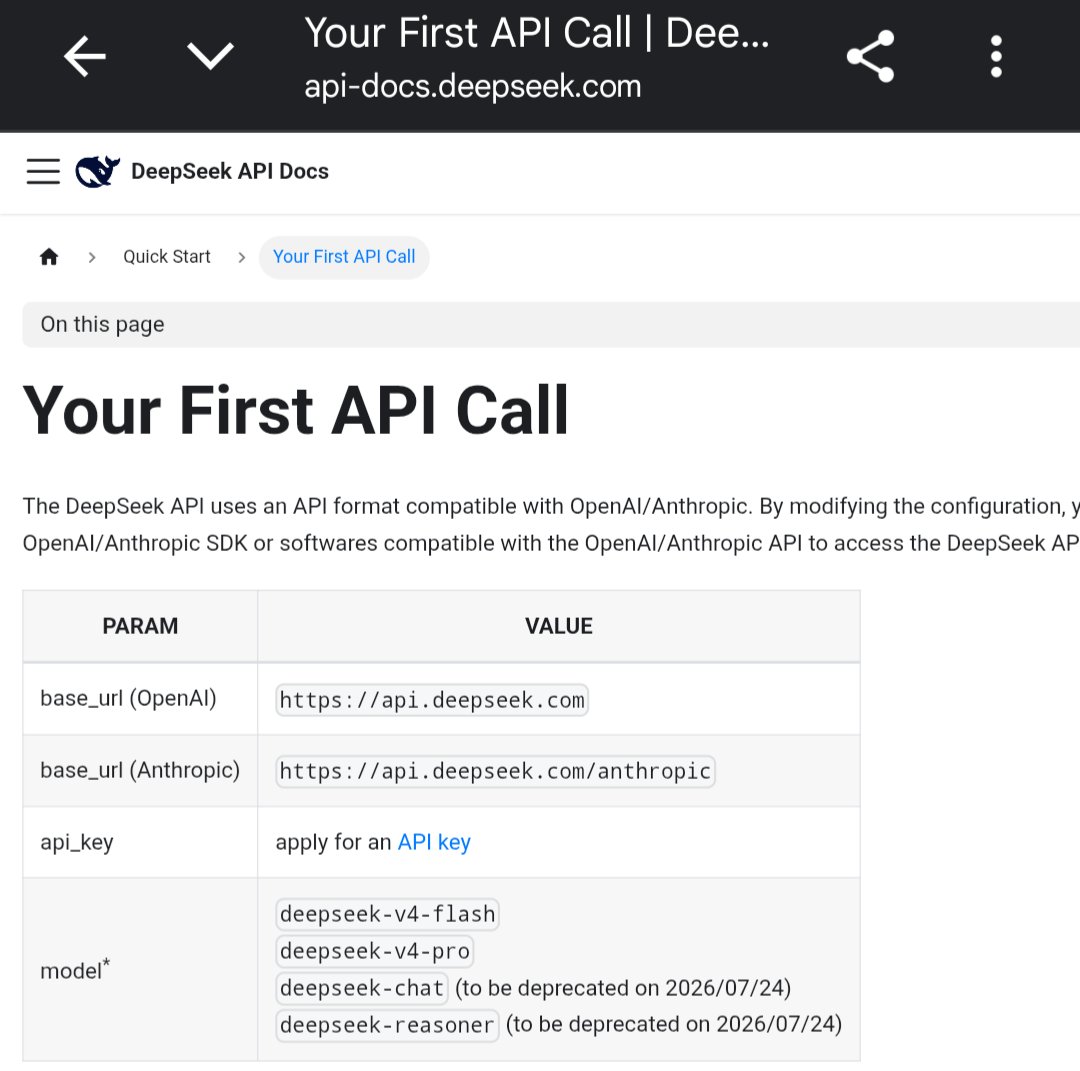
Chat prefix completion and FIM back – thank you! Missed this forever
but what can they do?

29
29
577
42,390
Ning Ding retweeted

Apr 23
Our goal is to build practical models with comprehensive capabilities beyond open benchmarks. And the only way to do it to co-design with diverse products while scaling solidly.
Tencent has the best product ecosystem and a solid, low-ego culture, and we are just getting started!
Apr 23

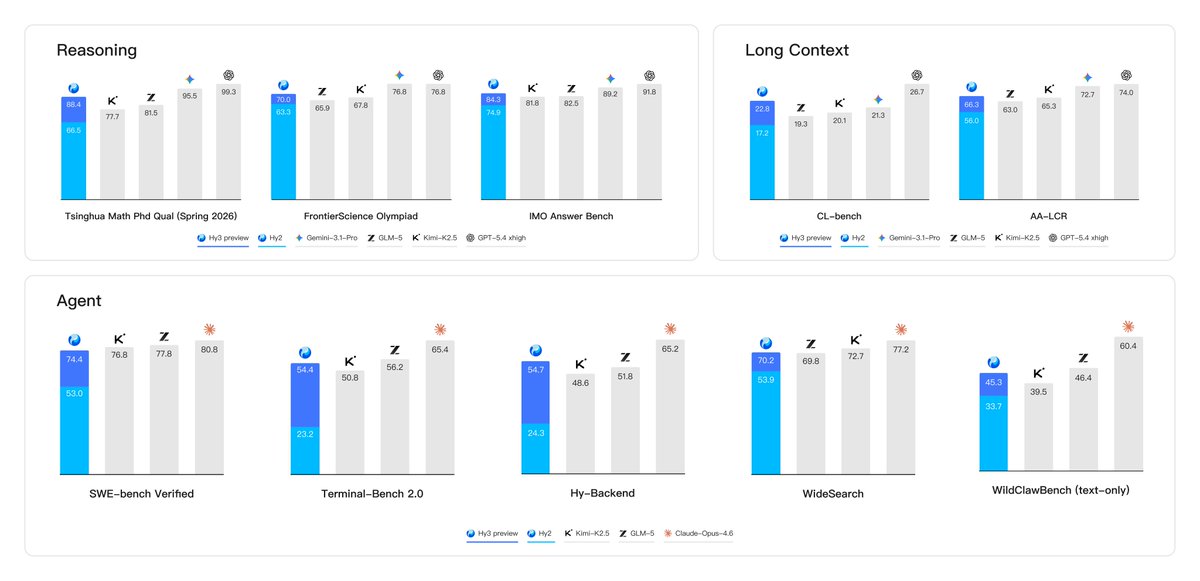
👋Hi /haɪ/, we're the Tencent Hy /haɪ/ team🐧
Today, we open source Hy3 preview (295B A21B), a leading reasoning and agent model in its size, with great cost efficiency.
Give us feedback to help improve Hy3 official!
🤗 hf.co/tencent/Hy3-preview
📖 hy.tencent.com/hy3-preview
50
146
1,941
875,748
Ning Ding retweeted

Our newest model, π0.7, has some interesting emergent capabilities: it can control a new robot to fold shirts for which we had no shirt folding data, figure out how to use an appliance with language-based coaching, and perform a wide range of dexterous tasks all in one model!
62
313
2,518
451,993
Apr 8
Surviving scale is becoming a real problem. Will AI labs eat everything?
Does each domain still need its own answer or just dissolve in the scaling pot?
Apr 7

Introducing Project Glasswing: an urgent initiative to help secure the world’s most critical software.
It’s powered by our newest frontier model, Claude Mythos Preview, which can find software vulnerabilities better than all but the most skilled humans.
anthropic.com/glasswing
1
2
5
1,086
Ning Ding retweeted

Apr 2
Introducing GEN-1.
Our latest milestone in scaling robot learning.
We believe it to be the first general-purpose AI model to master simple physical tasks.
99% success rates, 3x faster speeds, adapts in real time to unexpected scenarios, w/ only 1 hour of robot data.
More🧵👇
51
276
1,683
376,993