
The leading platform for building, fine-tuning, iterating, and managing your AI models faster with the highest-quality training data.
Joined June 2019
- Tweets 449
- Following 113
- Followers 720
- Likes 255
326 Photos and videos
















11 Dec 2025
🎉Congratulations to our partner @databricks on the launch of the OfficeQA Benchmark.
Enterprises can use the OfficeQA Benchmark to measure whether AI systems can handle the messy, high-precision tasks found in real business workflows. Teams can now more easily identify gaps, compare models, and make informed decisions about when AI is ready for deployment.
The benchmark was developed using a large dataset: nearly 89,000 pages of historical U.S. Treasury Bulletins (documents spanning decades, with scanned pages, PDFs, complex tables, charts, figures, and mixed unstructured structured data).
📣SuperAnnotate is proud to have powered the dataset and annotation rubrics behind this benchmark and to collaborate with the incredible Databricks team - Arnav Singhvi, Krista Opsahl-Ong, Jasmine Collins, @ivanzhouyq, @cindyxinyiwang, Ashutosh Baheti, Jacob Portes, Sam Havens, Erich Elsen, Michael Bendersky, @matei_zaharia, Xing Chen.
9 Dec 2025

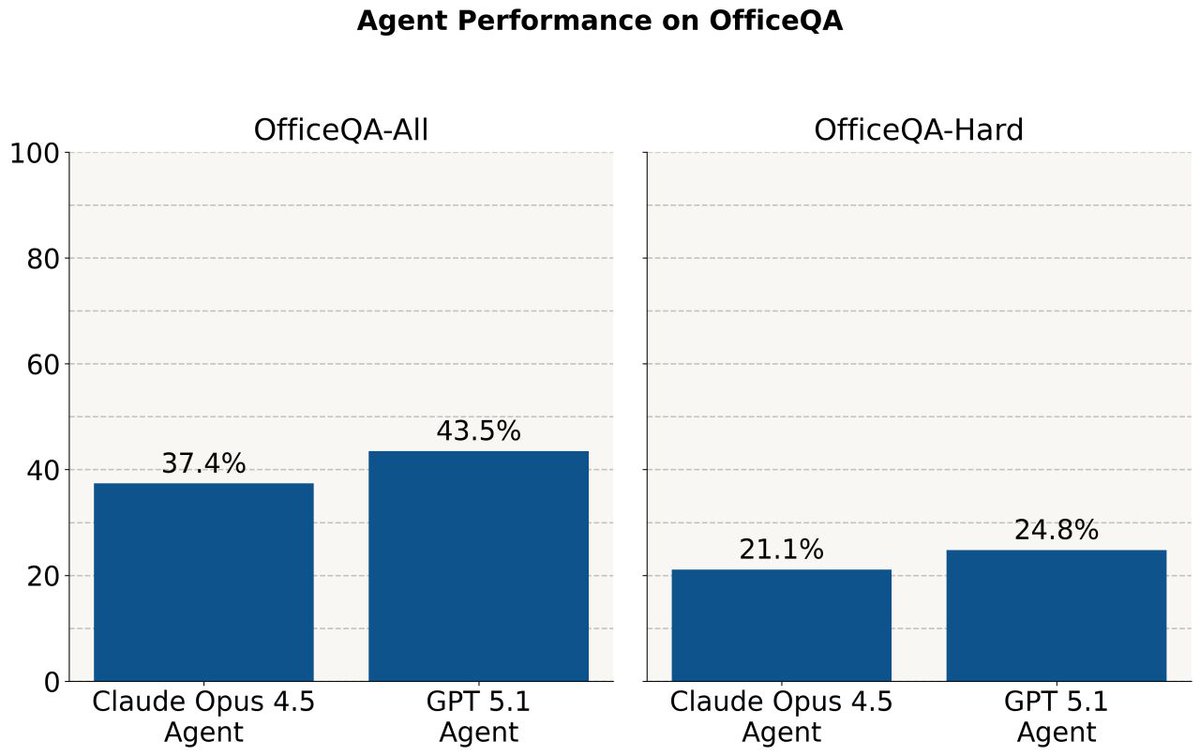
Today we’re introducing OfficeQA, a new benchmark grounded in ~89,000 pages of U.S. Treasury Bulletins that reflects the complex, document-heavy tasks enterprises actually face.
Unlike existing benchmarks, OfficeQA measures economically valuable, real-world reasoning: parsing dense tables, navigating scanned PDFs, and retrieving facts across decades of documents.
Even strong agents reach only ~45% accuracy, showing how far the field has to go. The benchmark is now open to the community, and the Databricks Grounded Reasoning Cup in Spring 2026 will challenge teams to push these capabilities forward. databricks.com/blog/introduc…
1
2
6
3,054
4 Dec 2025
The floor is buzzing at AWS re:Invent!
📍Meet us at Booth 1022 with NVIDIA.
#AWSreInvent #SuperAnnotate #NVIDIA


2
3
409
1 Dec 2025
📣 We’re at re:Invent this week and excited to welcome you at Booth 1022 together with NVIDIA.
You can meet our founders, explore the latest developments, and learn how our partnership with NVIDIA shapes the next phase of enterprise AI.
See you at the expo!
#AWSreInvent
1
3
355
27 Nov 2025
We are grateful for everyone powering AI with us – our customers, investors, partners, community, and team.
Happy Thanksgiving!🍁
#Thanksgiving #SuperAnnotate #AI
3
241
26 Nov 2025
We are proud to share that SuperAnnotate was nominated for SageMaker Partner Incubator program to build direct integrations with Amazon SageMaker’s product teams.🚀
Read the full article: superannotate.com/blog/super…
2
236
6 Nov 2025
🚀 Proud to be recognized by @awscloud as one of the pioneering startups accelerating enterprise AI with the Amazon SageMaker Incubator.
SuperAnnotate SageMaker = seamless, human-in-the-loop data workflows for faster, smarter model development.
Read 👉 aws.amazon.com/blogs/apn/pio…
1
1
3
275
28 Oct 2025
🎓 Learn how to build and automate a high-quality chatbot training and evaluation data pipeline that unites data creation and model training in one flow. [Video included]
👉 Learn more: superannotate.com/blog/build…
223
21 Oct 2025
📣 Join SuperAnnotate and @awscloud for a deep dive on building reliable, scalable LLM Judge systems.
See how top AI teams use AWS Bedrock human-in-the-loop review on SuperAnnotate to boost evaluation accuracy.
👉 Register now: superannotate.com/webinar
1
1
2
279
20 Oct 2025
Ever wonder how @Databricks and @flotracker run their AI evals?
Join our new hands-on workshop:
✅ Custom eval workflow for your use case
✅ Human-in-the-loop review setup
✅ LLM judges that actually work
👉 buff.ly/3fuwOAt
271
16 Oct 2025
POCs stall when teams can’t measure performance, leaving ML teams blind & leadership unsure.
Our guide breaks it down:
- Set the right metrics
- Combine human LLM review
- Build reliable LLM judges
Read: lnkd.in/eiHwE2xs
1
180
14 Oct 2025
🚀 Agent Hub just got an upgrade making it easier to use LLMs for data annotation & model evaluation.
- Connect to models on Fireworks, Vertex, Databricks, Bedrock
- Automate large-scale pre-labeling & evaluation
- Enjoy faster, smoother workflows
Read: buff.ly/7CgR7JH
2
1
3
223
8 Oct 2025
Need to ship better agentic, multimodal, and frontier AI faster and with high-quality?
Join us:
⚡ London, Oct 16
📍 Databricks Data AI World Tour | Booth K5
1
2
175
25 Sep 2025
🤖 AI pilots fail when data workflows can’t scale.
Read our ebook to see how HITL and in-platform agents deliver speed and quality.
👉 Check out the ebook - papermark.com/view/cmfz9y32q…
1
183
18 Sep 2025
Learn what Agentic AI is, how it works, its benefits and failures, and the best practices enterprises use to make AI agents more reliable.
Read the article:
superannotate.com/blog/agent…
1
158
17 Sep 2025
Excited to launch our new AI in 10 video series! 🎉
In the first episode Jason Liang and Julia MacDonald explore the critical role of humans-in-the-loop in deploying AI and share best practices for creating quality training and evaluation data.
Watch:
youtu.be/rE4o3GD4Bng
1
145
15 Sep 2025
Explore how @ServiceNow leveraged SuperAnnotate to build StarFlow, a domain-specific vision-language model that now outperforms GPT-4o.
Read more: superannotate.com/blog/servi…
2
175
8 Sep 2025
The real challenge in AI for healthcare? Operationalizing clinical expertise for LLM safety.
@flotracker used SuperAnnotate @databricks to:
⚡Validate 12,000 LLM outputs
✅Hit >90% accuracy
⏱Cut iteration cycles from weeks → days
Case study:
superannotate.com/blog/flo-c…
1
195
5 Sep 2025
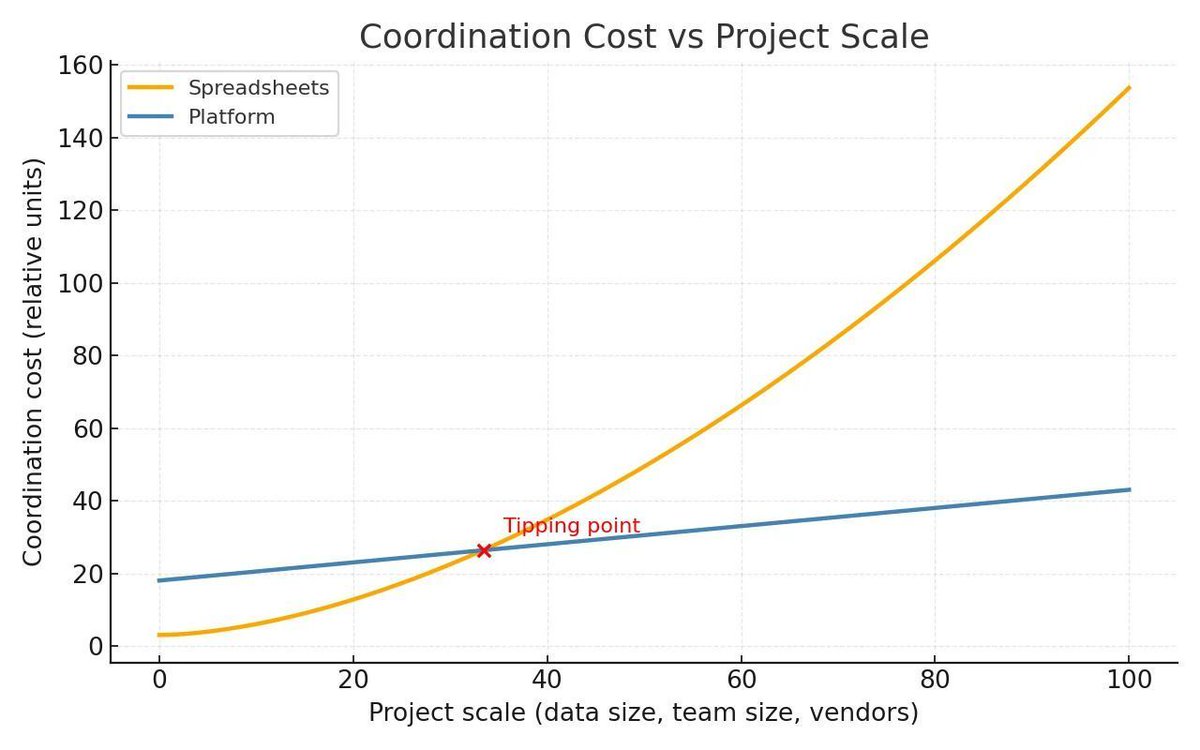
⛔ Spreadsheets hit their limit fast.
✅ We break down when they work, when to move on, and how SuperAnnotate helps teams go further.
Read 👉 superannotate.com/blog/sprea…
119
1 Sep 2025
🚨 Only 2 days left!
🚀Join NVIDIA, Databricks, and SuperAnnotate for a deep dive into how top teams evaluate and improve AI agents using structured evaluation and domain expert feedback.
👉 Register Now! superannotate.com/webinar

1
160
22 Aug 2025
💡 Discover how to build domain-specific LLMs with expert-labeled data, fine-tuning, and evaluation workflows to deploy high-accuracy AI in production.
Read more: superannotate.com/blog/domai…
1
2
175