
Joined April 2021
- Tweets 3,594
- Following 1,728
- Followers 1,733
- Likes 5,553
788 Photos and videos












Pinned Tweet

19 Jun 2025
Strong version of you is dealing with all the inner demons silently, keeping all the chaos contained within you, hidden from the outside world.
It'll get exhaustive sometimes and I am proud of you. Don't give up.
17
15,809
Swayam Singh retweeted
Jun 13
The following question was asked in Stanford's CS336's guest lecture with @realDanFu
Question: How megakernel works when you have multiple GPUs communication in the loop?
I did a similr thing in our recent work, that is each rank allocates its symmetric-memory buffer (i.e. each rank's buffer is mapped into a shared address space over NVLink and there's a multicast pointer that the NVLink fabric switch fans out to all peers' copies.)
Two PTX primitives do the actual reduction in-hardware:
- multimem. red => a rank writes its partial to all peers at once (fabric-side add into the multicast address).
- multimem.ld_reduce.add => a rank reads from the multicast pointer and the fabric returns the sum across all ranks' copies in a single instruction.
The barriers can be splitted, signal is hoisted early so the cross-rank wait overlaps with independent compute scheduled in the gap.
1
5
61
3,188
Jun 13
The following question was asked in Stanford's CS336's guest lecture with @realDanFu
Question: How megakernel works when you have multiple GPUs communication in the loop?
I did a similr thing in our recent work, that is each rank allocates its symmetric-memory buffer (i.e. each rank's buffer is mapped into a shared address space over NVLink and there's a multicast pointer that the NVLink fabric switch fans out to all peers' copies.)
Two PTX primitives do the actual reduction in-hardware:
- multimem. red => a rank writes its partial to all peers at once (fabric-side add into the multicast address).
- multimem.ld_reduce.add => a rank reads from the multicast pointer and the fabric returns the sum across all ranks' copies in a single instruction.
The barriers can be splitted, signal is hoisted early so the cross-rank wait overlaps with independent compute scheduled in the gap.
1
5
61
3,188
Jun 13
I particularly didn't know that NCCL calls can be fused in a MK (it will be really cool to know how 😃), so from my vanilla use I found multimem 4x better than NCCL's floor (obv at B=1)
2
5
337
Swayam Singh retweeted
Jun 12
This is exactly why I'm building Cpp-Verify, and it's exciting to see @JaneStreetGroup embracing a similar philosophy around OCaml and formal methods.
Verification tooling shouldn't live outside the language ecosystem, it should evolve alongside it.
Cpp-Verify takes this approach by extending the C compiler stack (Clang/LLVM) itself, adding contracts and a dedicated verification IR that can target multiple backends. Today we're focused on Z3, with BMC and Lean serving as experimental backends.
As AI makes code generation cheaper than ever, verification is rapidly becoming the bottleneck. The future belongs to language-integrated verification, not bolt-on tooling.
Jun 11

Our goals here are ambitious! Our hope is to make formal methods as pervasively useful of a tool for building software as sophisticated type systems are for us today.
blog.janestreet.com/formal-m…
1
1
14
1,292
Jun 12
This is exactly why I'm building Cpp-Verify, and it's exciting to see @JaneStreetGroup embracing a similar philosophy around OCaml and formal methods.
Verification tooling shouldn't live outside the language ecosystem, it should evolve alongside it.
Cpp-Verify takes this approach by extending the C compiler stack (Clang/LLVM) itself, adding contracts and a dedicated verification IR that can target multiple backends. Today we're focused on Z3, with BMC and Lean serving as experimental backends.
As AI makes code generation cheaper than ever, verification is rapidly becoming the bottleneck. The future belongs to language-integrated verification, not bolt-on tooling.
Jun 11
Our goals here are ambitious! Our hope is to make formal methods as pervasively useful of a tool for building software as sophisticated type systems are for us today.
blog.janestreet.com/formal-m…
1
1
14
1,292
Jun 11
12.45 ms/tok and I am stopping now, other things need more attention.
Will prepare its OSS release soon
1
1
86
Jun 10
Warp-4 decided to be different than the crowd and ended up spinning forever.
Bao-Wao old friend!
7
310
Swayam Singh retweeted
Jun 9
Just recalled something, in my last year's work on NextCoder. We found that moving base was sub-optimal as compare to the fixed base. (Which produces the reasoning of constrained KL-div between the base and ckpt, leading to benefits, kinda artifcat parallel to RL)
But inspired from Dino-V1, what if using the moving base but instead of big ckpt jump, we take an exponential moving average and doing SeleKT updates as per that.
I don't have compute and time both, so if anyone wants to take this, feel free to.
1
10
328
Jun 9
I envy people who can use agents effectively.
In all of my tasks, it just keep saying:
"This is a huge write-up", "needs more than 3-4 weeks".
So I used /goal and after 2 iterations it is telling me that
"I can't do in this session, please do /goal clear" 😂😂
1
8
453
Swayam Singh retweeted
Jun 8
13.75 ms/tok (reached @vllm_project 's latency with compilation enabled, block-scaled fp8)
And my kernel still having 10 idle clusters! Going ahead will be the gains (no CLC, it will raise more design questions, will try split-k first)
1
1
2
362
Jun 8
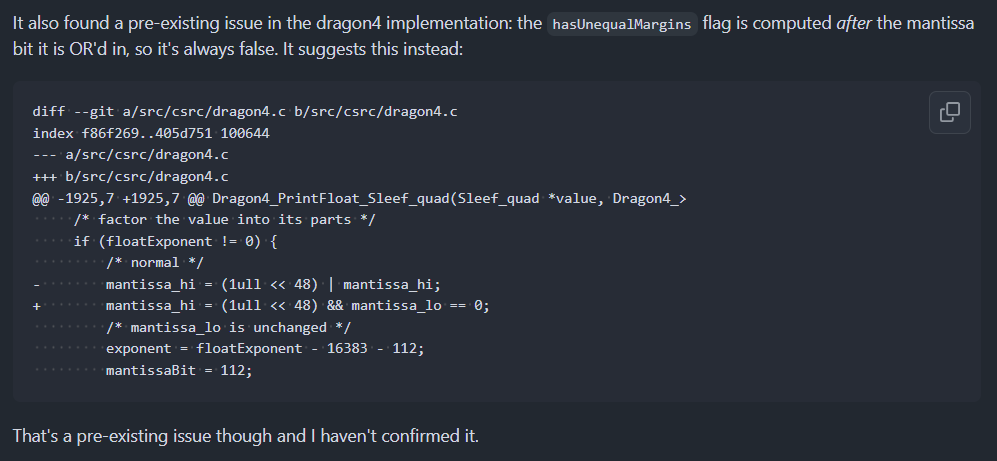
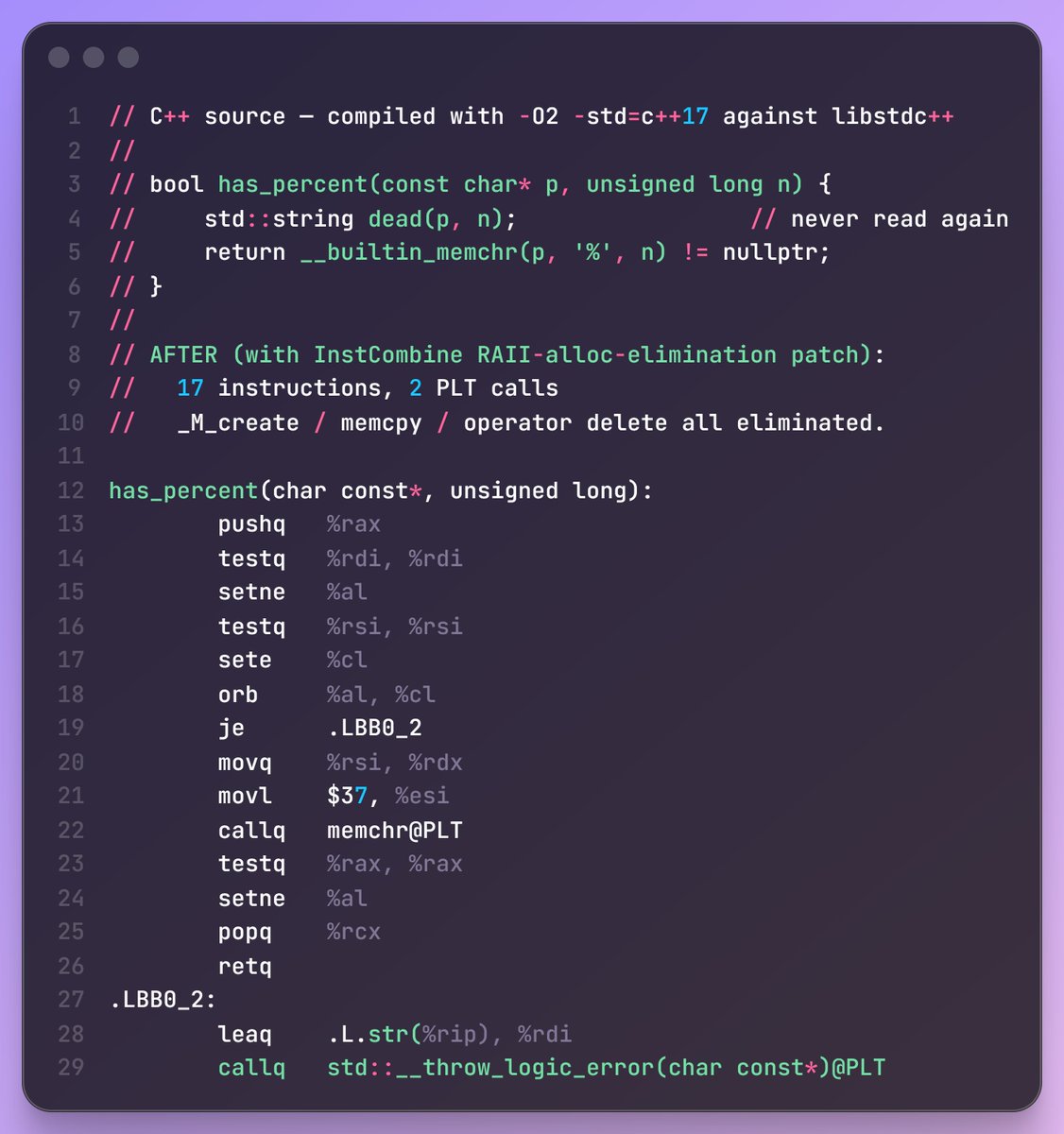
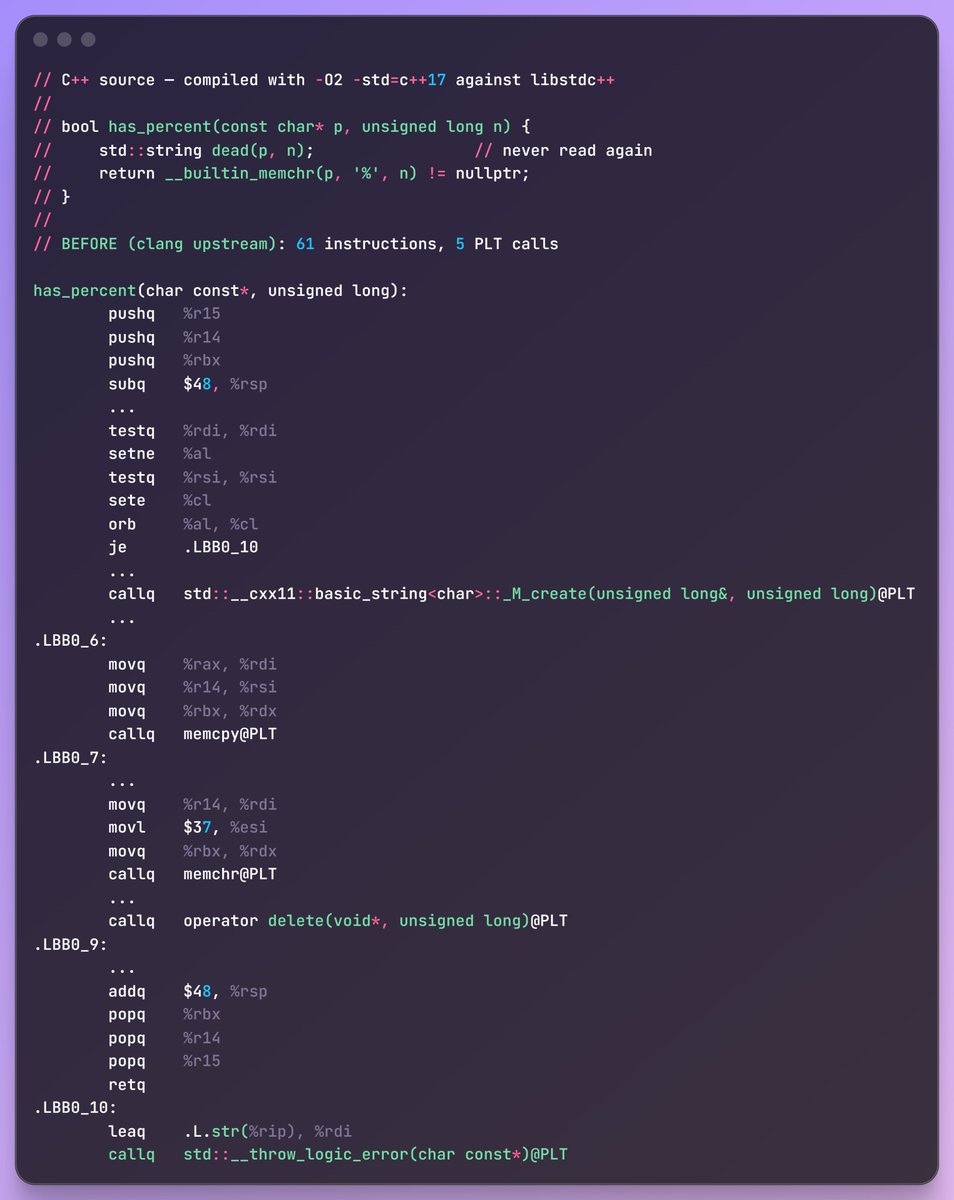
Claude discovered a precision bug that stayed more than 2 years in production.
It happened because our test cases did not include a huge power of 2 number. Will be soon advocating to ditch test-cases based correction and instead jump to formal gurantee methods.
2
8
419