
Il n'y a pas d'IA utile sans intelligence du métier. Il n'y a plus de métier pérenne sans refonte par l'IA.
Joined January 2017
- Tweets 152
- Following 1,531
- Followers 116
- Likes 2,761
9 Photos and videos





Sylvain retweeted

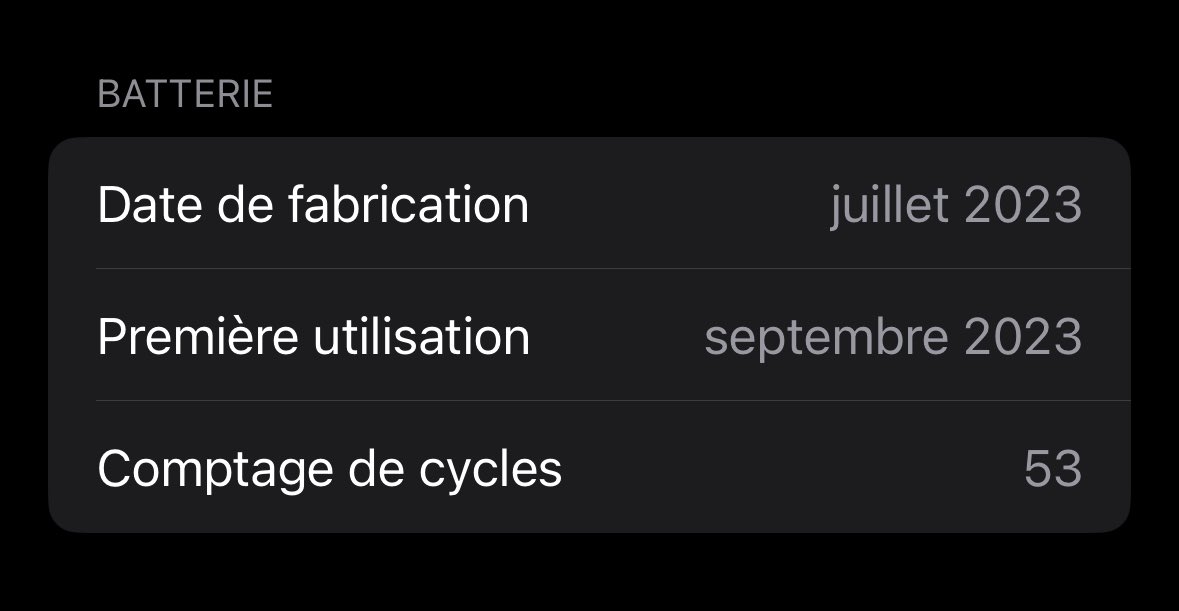
Announcing Artificial Analysis Intelligence Index v4.1: a shift toward agentic workloads, featuring upgraded benchmarks and new per-task metrics
The Artificial Analysis Intelligence Index is our synthesis metric for assessing model intelligence and tracking AI progress. v4.1 marks a broader shift toward agentic workloads, with three main changes:
Updated and reweighted evaluations toward agentic tasks:
1. We upgraded three evaluations, removed one, and reweighted the Intelligence Index:
➤ Upgraded Terminal-Bench Hard to Terminal-Bench 2.1 and τ²-Bench Telecom to τ³-Bench Banking. Both move to newer, more robust task sets with harder, more realistic agentic scenarios that better separate frontier models
➤ Upgraded GDPval-AA to GDPval-AA v2. The upgrade re-baselines Elo to human performance at 1000, introduces a rotating panel of frontier-model judges, and raises the turn limit from 100 to 250 for longer-horizon agent trajectories
➤ Removed IFBench due to saturation. The benchmark no longer distinguishes frontier models sufficiently, so we have removed it from the Intelligence Index. We will continue to run it and publish results on new model releases
2. Cost per Task, Time per Task, and Tokens per Task:
Three new per-task metrics, reported for every model and based on the Intelligence Index. We take the total cost, total time, and total output tokens for a model to run the Intelligence Index and divide by the number of tasks across its evaluations, giving the average cost, time, and output tokens to complete a single Intelligence Index task
3. Cached input token reporting:
We now report cached input tokens and their impact on cost, including the cost to run the Intelligence Index, to better reflect the real cost of running each model
Key Results:
➤ Leading models: Claude Fable 5 (with Opus 4.8 fallback, 60) leads the Artificial Analysis Intelligence Index v4.1 by four points but is currently unavailable, leaving Claude Opus 4.8 (max, 56) as the most intelligent available model, ahead of GPT-5.5 (xhigh, 55) ➤ Open weights leading models: Among open weights models, DeepSeek V4 Pro (max, 44) and MiniMax M3 (44) lead, followed by Kimi K2.6 (43) and MiMo-V2.5-Pro (42)
➤Cost per Task: Claude Opus 4.8 (max) is the most expensive available model at $1.78 per task, with Claude Fable 5 the highest overall at $3.25. GPT-5.5 (xhigh) scores within a point of Opus 4.8 on the Intelligence Index at $0.99 per task. DeepSeek V4 Pro (max) stands out on the Intelligence vs Cost per Task chart at $0.04 per task, with other leading proprietary models costing 20x to 45x more
➤Time per Task: time per task (inference decode time) ranges from 1.5 minutes for Grok 4.3 (high) to 13.5 for Claude Sonnet 4.6 (max), a roughly 9x spread. Claude Opus 4.8 (max) completes a task in 6.4 minutes and GPT-5.5 (xhigh) in 3.7, while Gemini 3.1 Pro Preview stands out on the Intelligence vs Time per Task chart at 1.6 minutes for a score of 46
92
132
1,278
230,945

You are a taker, not a maker. All you’ve done your whole life is take from the makers of the world.
The zero-sum mindset you have is at the root of so much evil. Once you realize that civilization is not zero-sum and that it is about making far more than one consumes, then it becomes obvious that the path to prosperity for all is just let the makers make.
Regarding Tesla, the reality is that I have been given nothing.
However, if I lead Tesla to become the most valuable company in the world by far and it stays that way for 5 years, shareholders voted to award me 12% of what is built. Anyone who wants to come along for the ride can buy Tesla stock.
If Tesla “merely” becomes a $1.999 trillion dollar company, I get nothing. This is a great deal for shareholders, which is why they voted so overwhelmingly to approve this, for which I am immensely grateful.
And they did so by a margin far more than you won your political seat.
9,048
16,138
130,606
12,394,163
Sylvain retweeted

Jun 14
2,789
7,853
39,861
64,163,792
Sylvain retweeted

Jun 13
Introducing the Fusion API, the smartest compound model in the market.
Fusion achieves Fable-level intelligence at half the price.
How it works 👇

699
1,757
14,776
5,925,647


The era of the Agentic OS has a lot of room to explore on the UX front. Excited to see where we go from here!

35
27
456
25,635
Sylvain retweeted

Jun 10
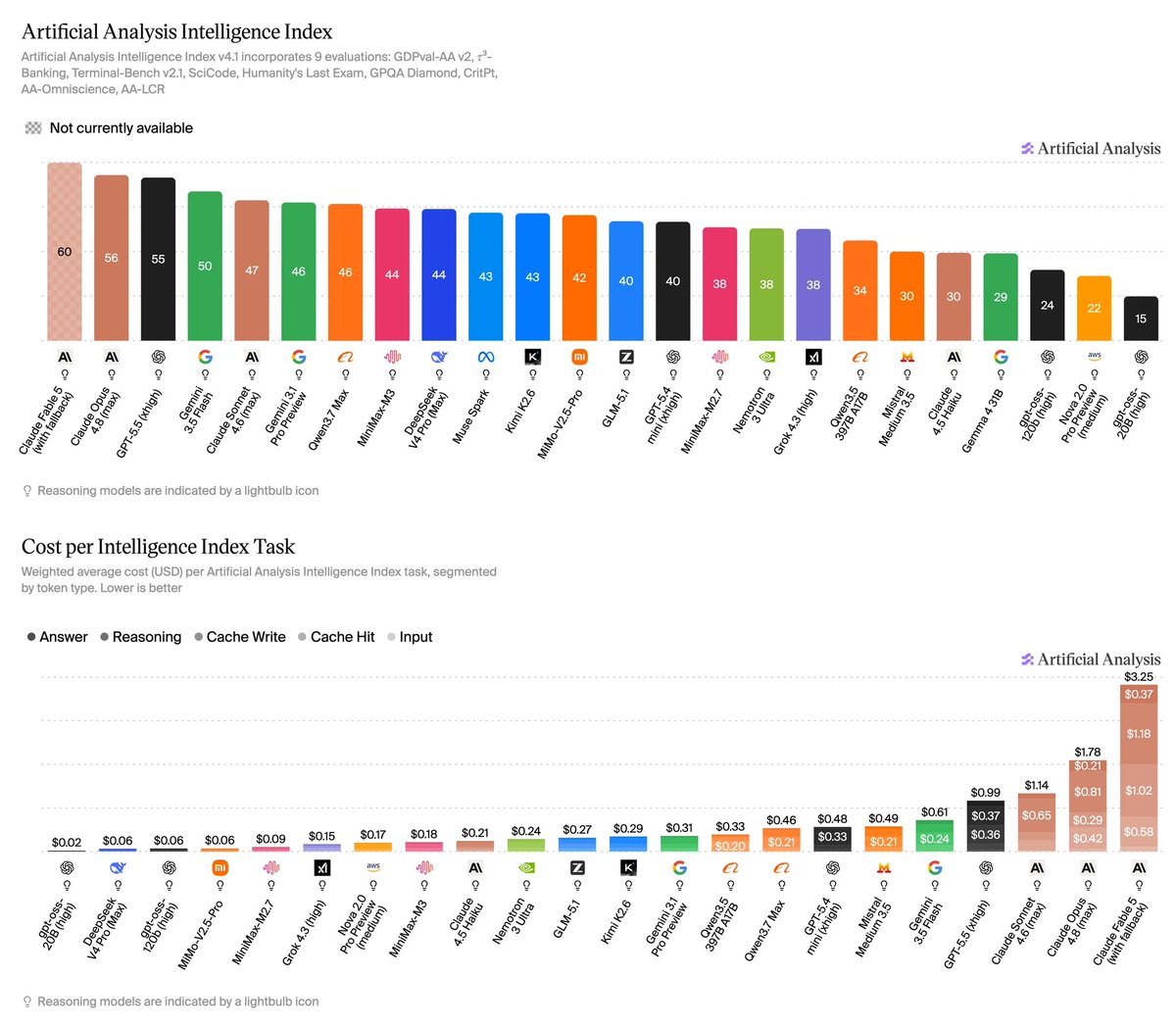
A single Starship launch will deploy 60 next-gen @Starlink V3 satellites and add 61,000 Gbps of network capacity. By comparison, a Falcon 9 carrying 27 Starlink V2 satellites adds 2,600 Gbps.
In other words, one Starship launch will add as much capacity as 23 Falcon 9 launches combined.
Just 10 Starship launches carrying Starlink V3 satellites will add as much network capacity as the entire Starlink network has today. Absolutely wild.
163
717
6,002
188,723
Sylvain retweeted

Jun 9
Qualia has been selected for the @GoogleDeepMind Robotics Program.
We train embodied models that put a robot on a real manual task and make it work, on the floor, not in a demo.
Foundation models and reasoning are where robotics is heading, and doing that work alongside DeepMind, who are pushing this frontier, is exactly where we want to be.
If you are a company looking to see how a new generation of robots can help your manual tasks, contact us at hello@qualiastudios.dev
More soon
36
104
904
85,515
What's crazy to me is that Fable is blocked from life sciences broadly, nerfed even if you get passed the classifiers and filter level blocks.
The whole point of AGI/ASI is to cure all diseases. Everything else is just nice to haves. But Anthropic wants to close off that path.
I think Anthropic might be the worst company on the planet.
421
392
5,319
233,797


SpaceX is the only company building the infrastructure of the future across space, connectivity, and AI → spacexipo.com
862
2,521
14,369
15,388,387
Yes
5,065
10,792
109,588
16,462,303
Sylvain retweeted

May 22
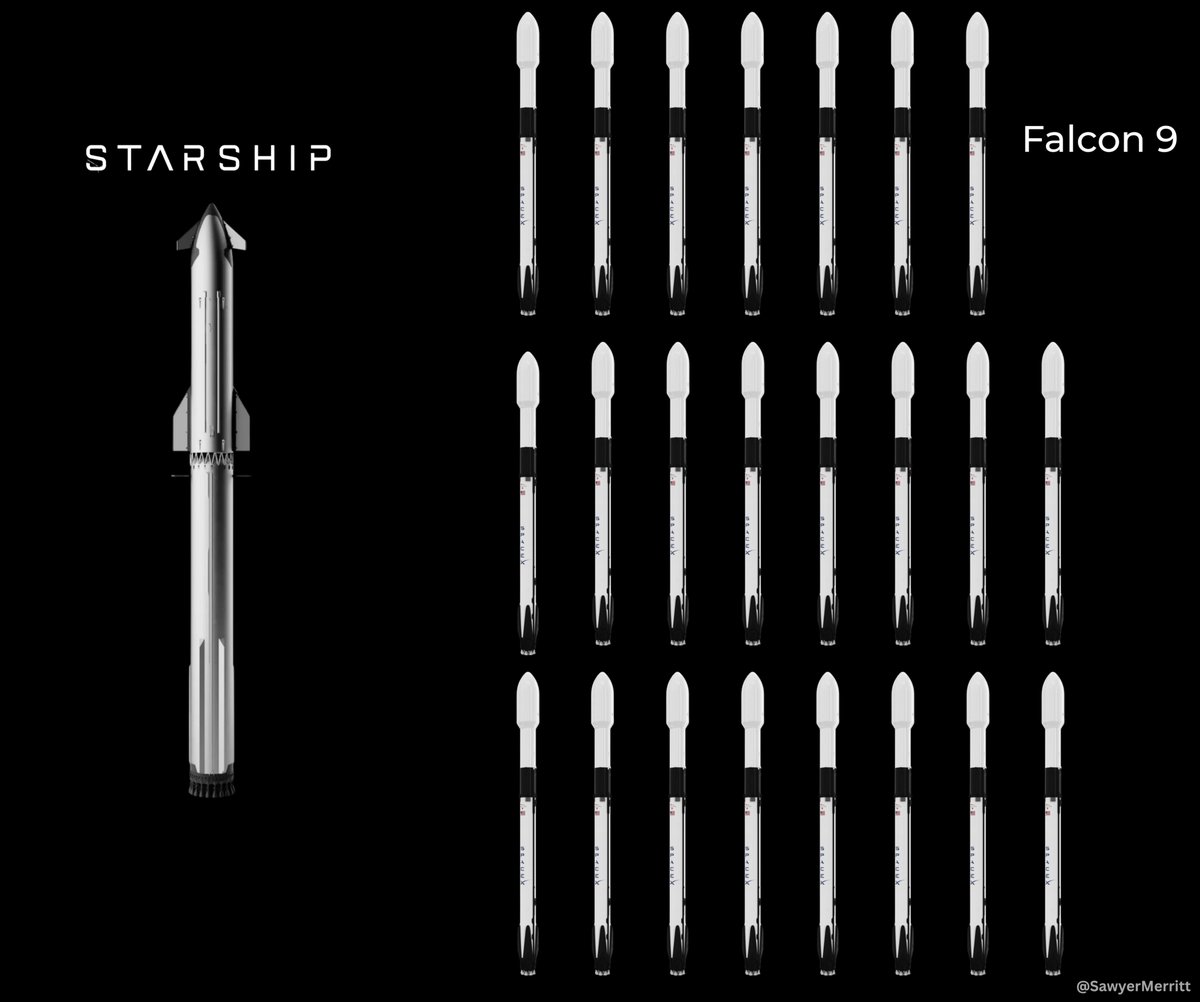
Today we're open-sourcing Bumblebee, a read-only scanner for macOS and Linux.
It checks developer machines for risky packages, extensions, and AI tool configs.
Connected to Computer, it can trigger deeper scans whenever a new supply-chain risk emerges.
github.com/perplexityai/bumb…
182
704
5,129
1,536,844
Sylvain retweeted

May 21
AI agents can automate tasks, giving you an edge or saving your time.
But getting the maximum benefit often requires access to sensitive information.
Today we're giving you the control needed to maximize efficiency and minimize risk. Announcing: Proton Pass for AI agents.
1/3
15
23
202
16,738
Sylvain retweeted

May 11
People talk, listen, watch, think, and collaborate at the same time, in real time. We've designed an AI that works with people the same way.
We share our approach, early results, and a quick look at our model in action.
thinkingmachines.ai/blog/int…
464
1,961
15,789
7,753,358
Sylvain retweeted

May 6
We are back. After one year of quiet building.
Introducing GENE-26.5, our first robotic brain that takes a major step toward human-level capability.
For years, robotics has struggled to learn from the world’s largest and valuable data source: Humans.
Solving it means rethinking the whole stack from the ground up:
- A robotics-native foundation model.
- A 1:1 human-like robotic hand.
- A noninvasive data collection glove for motion, force, and touch.
- A simulator that turns weeks of experiments into minutes.
GENE-26.5 is trained across language, vision, proprioception, tactile, and action. We designed a set of tasks to test how far we can go with this new paradigm.
Fully autonomous, 1x speed, one model, same weights. (Enjoy with sound on)
We are approaching the endgame for robotics.
And this is just a beginning.
280
1,135
5,816
2,692,552
Sylvain retweeted

Apr 28
🆕 Today, we're releasing the public preview of Workflows, the orchestration layer for enterprise AI.
🌎 Enterprise teams have capable models. What they don't have is a way to run them reliably in production. That's the gap Workflows fills. It takes AI-powered business processes from prototype to production, with the durability, observability, and fault tolerance that production actually requires.
Leading organisations like ASML, ABANCA, CMA-CGM, France Travail, La Banque Postale, Moeve, and many others are already using Workflows to automate critical processes.
100
260
2,026
311,657
Sylvain retweeted

Apr 25
Graph is the final boss of memory.
stacking markdown files isn't memory. it's context you keep re-loading into the prompt.
real memory is a graph. nodes, embeddings, traversal. it's how production agents remember.
the article is the workaround. the lecture is the architecture

48
74
859
245,422
Sylvain retweeted

Apr 20
Earlier this year Yann LeCun left Meta because Mark Zuckerberg wouldn't bet the company on JEPA. Last week his group dropped the first JEPA that actually trains end-to-end from raw pixels. 15 million parameters. Single GPU. A few hours.
The timing is not a coincidence.
For four years Meta has been the house that JEPA built. LeCun published the original paper from FAIR in 2022. I-JEPA and V-JEPA came out of his lab. The architecture was supposed to be the escape hatch from LLMs, the path to robots that actually learn physics instead of hallucinating about it. Every version shipped fragile. Stop-gradients. Exponential moving averages. Frozen pretrained encoders. Six or seven loss terms that had to be hand-tuned or the model collapsed into garbage representations.
Meta kept funding LLMs. Llama shipped. Llama scaled. Llama got beat by Qwen and DeepSeek. Zuck spent $14 billion to buy ScaleAI and install Alexandr Wang. The FAIR robotics group was dissolved. LeCun's research kept winning papers and losing the product roadmap.
He left, started AMI Labs, and said publicly that LLMs were a dead end.
Now the paper. LeWorldModel. One regularizer replaces the entire pile of heuristics. Project the latent embeddings onto random directions, run a normality test, penalize deviation from Gaussian. The model cannot collapse because collapsed embeddings fail the test by construction. Hyperparameter search went from O(n^6) polynomial to O(log n) logarithmic. Six tunable knobs became one.
The downstream numbers are what should scare the robotics capex class. 200 times fewer tokens per observation than DINO-WM. Planning time drops from 47 seconds to 0.98 seconds per cycle. 48x faster at matching or beating foundation-model performance on Push-T and 3D cube control. The latent space probes cleanly for agent position, block velocity, end-effector pose. It correctly flags physically impossible events as surprising. It learned physics without being told physics existed.
Figure AI is valued at $39 billion. Tesla Optimus is mass-producing. World Labs raised $230 million to sell generative world models. Everyone in humanoid robotics is burning capital on foundation-model pipelines that plan in 47 seconds per cycle.
LeCun's group just showed you can do it with 15 million parameters on a single GPU in a few hours.
This is the Xerox PARC pattern running again. Meta had the next architecture. Meta had the scientist. Meta dissolved the robotics team, passed on the productization, and watched the exit. Three months later the lab that was supposed to be Meta's publishes the result that resets the robotics cost structure.
The paper is worth more than Alexandr Wang.

64
375
3,249
1,147,594

Au vu de l'engouement, on a déjà rempli la plus grande salle @mk2 parisienne (merci !)
➡️On ouvre donc une deuxième séance à 20h, toujours le 26 mars au mk2 Bibliothèque, en présence de l'équipe du docu.
@mammouth_ai @esa

13
9
157
22,805