
Principal @Atlassian | Helping engineers reach Staff/Principal | 1:1 Mentorship & Mock Interviews | 90 System design fundamentals - puneetpatwari.in
Joined December 2025
- Tweets 1,313
- Following 122
- Followers 19,130
- Likes 1,128
86 Photos and videos











Pinned Tweet

Jun 11
I've been a backend Engineer for 12 years. Today, I'm a Principal Engineer at Atlassian.
I've designed systems that handle millions of requests. Sat on both sides of system design interviews.
Reviewed more architecture docs than I can count.
Starting today, I'm breaking down the fundamentals of scaling for the next 25 days.
If you're learning system design bookmark this thread, you're going to get a lot of learning from this.
119
922
11,847
815,163
Jun 11
I've been a backend Engineer for 12 years. Today, I'm a Principal Engineer at Atlassian.
I've designed systems that handle millions of requests. Sat on both sides of system design interviews.
Reviewed more architecture docs than I can count.
Starting today, I'm breaking down the fundamentals of scaling for the next 25 days.
If you're learning system design bookmark this thread, you're going to get a lot of learning from this.
119
922
11,847
815,163
Day 4 is here 👇x.com/system_monarch/status/…

I've started a 25-day series on Scaling and Architecture.
One topic per day.
Day 1: Load Balancing
Day 2: CDN
Day 3: Caching (the 5 layers)
Today is Day 4: Cache Invalidation.
Caching data is easy. Knowing when to throw it away is where every team I've worked with has gotten burned at some point.
Write-through. Write-behind. Write-around. TTL vs event-driven. Breaking down each one today.
Follow along if you're preparing for system design interviews. Thread below 👇
(90 system design fundamentals in one guide → puneetpatwari.in)
2
505
I've started a 25-day series on Scaling and Architecture.
One topic per day.
Day 1: Load Balancing
Day 2: CDN
Day 3: Caching (the 5 layers)
Today is Day 4: Cache Invalidation.
Caching data is easy. Knowing when to throw it away is where every team I've worked with has gotten burned at some point.
Write-through. Write-behind. Write-around. TTL vs event-driven. Breaking down each one today.
Follow along if you're preparing for system design interviews. Thread below 👇
(90 system design fundamentals in one guide → puneetpatwari.in)
2
6
69
3,895
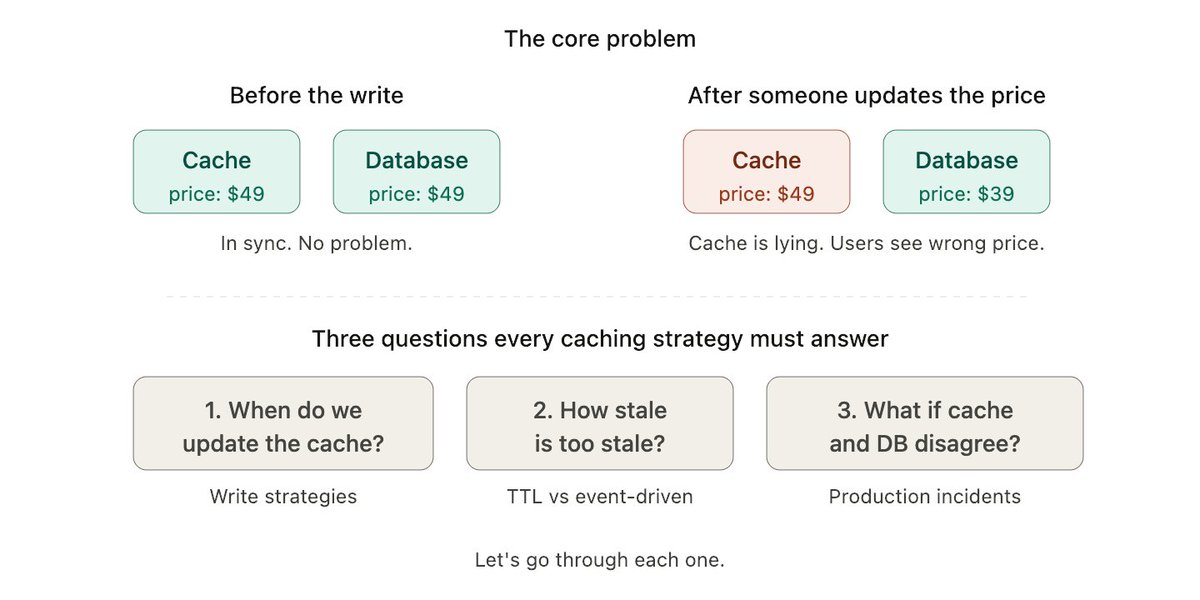
Ok so you've picked a write strategy. Now the other half of the problem.
How do you actually expire stale data?
Two approaches:
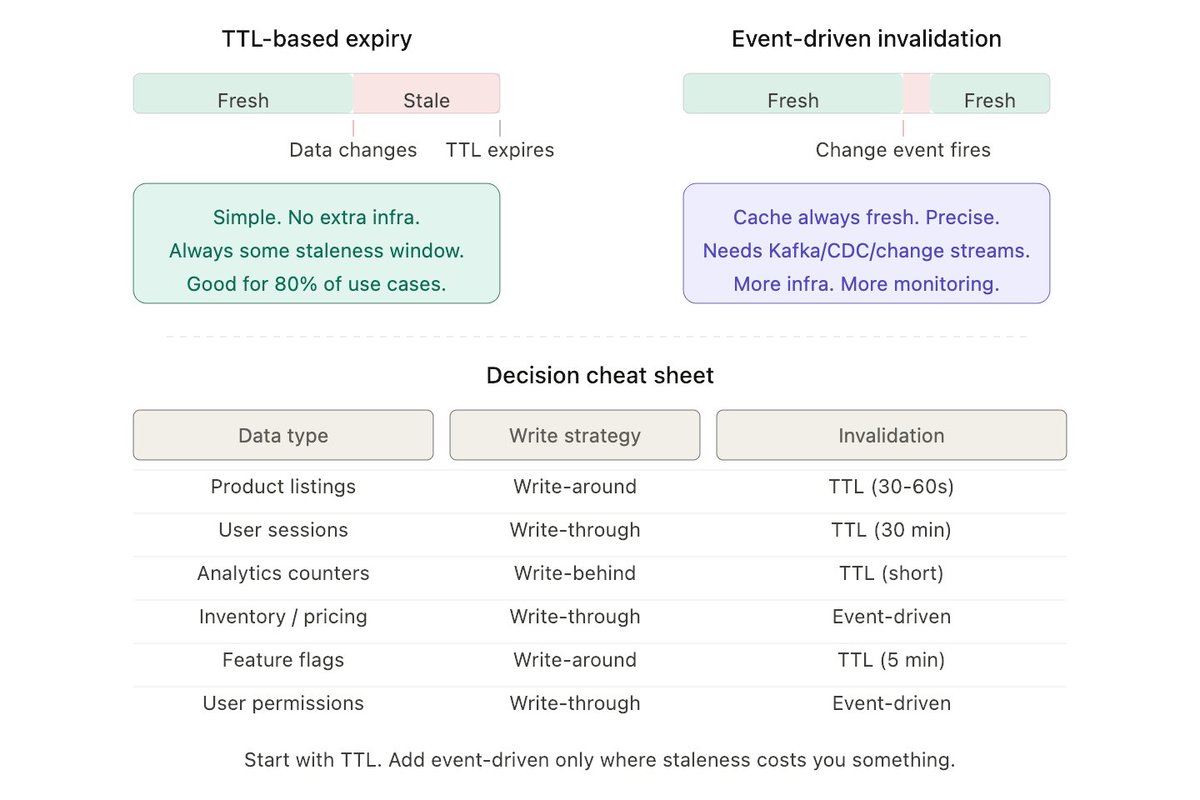
1. TTL-based expiry (time-to-live)
Set a timer on every cache entry. When the timer runs out, the data is automatically deleted. Next read triggers a fresh fetch.
Some rules of thumb I use:
- Config data, feature flags → TTL of 5-10 minutes
- Product listings, search results → TTL of 30-60 seconds
- User session data → TTL of 30 minutes
- Versioned static assets → TTL of 1 year (filename changes per version anyway)
Why it works: Dead simple. No extra infrastructure. Set it and forget it.
Where it breaks: You're always accepting some staleness. If the TTL is 60 seconds, a user might see outdated data for up to 60 seconds after a change. For a product listing? Nobody cares. For a bank balance? That's a support ticket.
2. Event-driven invalidation
Instead of waiting for a timer, you actively delete or update the cache the moment the underlying data changes.
How:
- Database writes trigger an event (via CDC, a message queue, or app-level hooks)
- A consumer listens for that event and invalidates the cache immediately
Why it works: Cache is always fresh. No staleness window. Precise.
Where it breaks: You need infrastructure for it. A Kafka consumer or a database change stream (Postgres logical replication, MongoDB change streams, DynamoDB streams). More moving parts. More things to monitor. More things that can fail silently.
Which one should you use?
Honestly? Start with TTL. For most data in most systems, a 30-60 second staleness window is invisible to users.
Add event-driven invalidation only for data where staleness actually costs you something:
- Inventory counts (overselling)
- Pricing (showing wrong price)
- Permissions/auth (security risk)
- Real-time features (chat, live dashboards)
Everything else? TTL. Don't over-engineer it.
Quick decision cheat sheet:
Format: What you're caching → Strategy → Invalidation
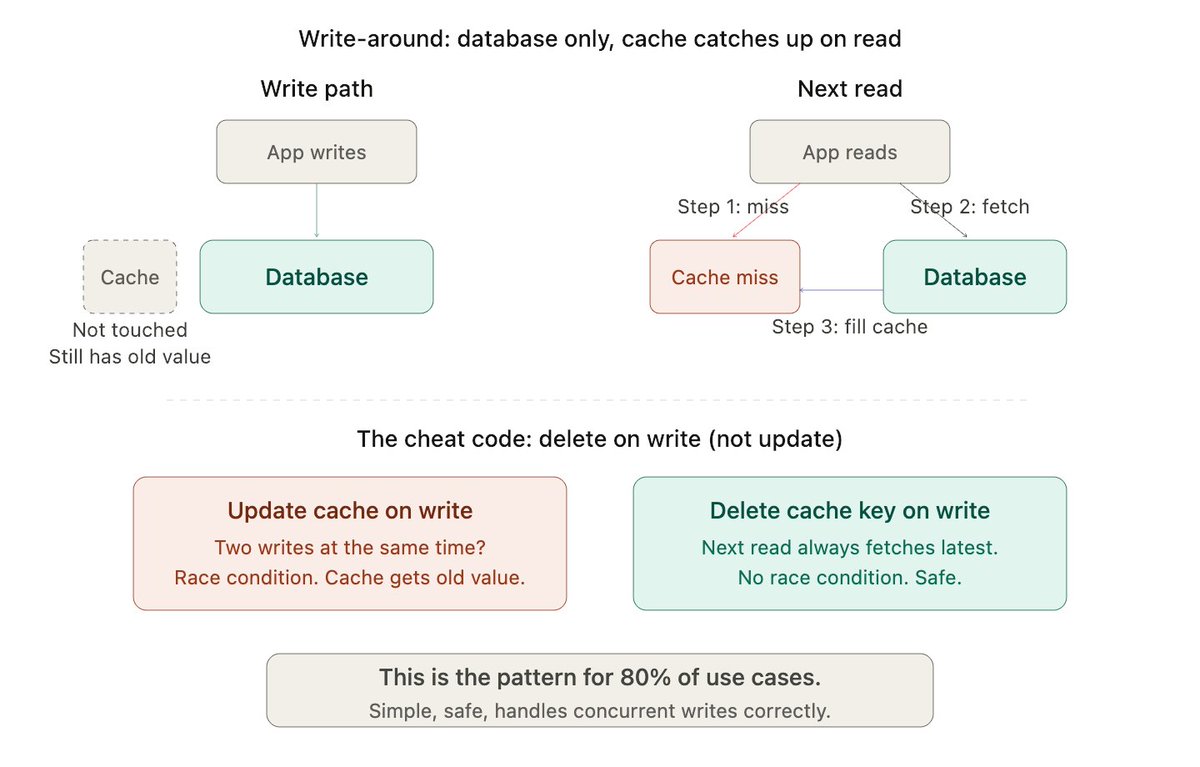
1) Product listings → Write-around → TTL (30-60s)
2) User sessions → Write-through → TTL (30 min)
3) Analytics counters → Write-behind → TTL (short)
4) Inventory / pricing → Write-through → Event-driven
5) Feature flags → Write-around → TTL (5 min)
6) User permissions → Write-through → Event-driven
1
2
349
That's Day 4. The full picture of cache invalidation.
To recap the week so far:
- Day 1: Load Balancing
- Day 2: CDN
- Day 3: The 5 caching layers
- Day 4: Cache invalidation strategies
Tomorrow (Day 5): Rate Limiting. Your system has a breaking point. Rate limiting is how you make sure you find it on your terms, not your users'.
90 system design fundamentals in one guide → puneetpatwari.in
Follow for the rest of the series 🔔
291
Jun 13
Have you ever wondered:
You update your profile pic on Instagram.
Your friend in another city still sees the old one for 30 seconds.
But your bank balance is always exactly right, everywhere, instantly.
Why does one system tolerate stale data and the other can't?
23
2
68
9,586
Jun 13
Candidate said their API "queries the orders table by user_id."
Interviewer asked: "How many rows in that table?"
"Around 200 million."
"Is user_id indexed?"
Silence.
One missing index.
That's the difference between 40ms and 40 seconds.
7
48
5,017
Jun 13
Building AI features in production?
How many of these can you actually explain:
Embedding drift
Chunking strategies
Reranking
Prompt injection
Hallucination detection
Guardrails architecture
Token budget management
Streaming vs batch inference
Fine-tuning vs RAG tradeoffs
Eval frameworks
Tool use / function calling
Context window management
4
8
64
2,659
Jun 13
If Zomato sends push notifications to 50M users when a sale starts...
Are they literally making 50M API calls to Firebase at once?
62
33
1,865
351,668
Jun 13
Your microservice calls a downstream payment API.
That API starts responding in 12 seconds instead of 200ms.
Your thread pool fills up. Requests start queuing. Your service goes down too.
One slow dependency took out your entire system.
What should you have done differently?
11
4
77
11,865
Jun 13
If an AI app stores 500M embeddings for semantic search...
Is it really doing a distance calculation against all 500M vectors on every query?
6
21
5,447
Jun 13
Senior backend interview in 2026.
How many of these can you explain clearly:
Event sourcing
Saga pattern
Bulkhead isolation
Token bucket vs leaky bucket
Consistent hashing
Write-ahead logging
Backpressure
Tombstone records
Bloom filters
Vector clocks
Gossip protocol
Idempotency keys
Read-your-writes consistency
If it's less than 8, you're not ready.
12
63
548
32,181
Jun 13
Have you ever wondered:
When you delete an Instagram post, it's gone instantly.
But Instagram can "restore" it if you ask support within 30 days.
If it's deleted... where is it living?
3
8
1,976
Jun 13
You see this API in production:
GET /api/v1/transactions?page=48572&limit=50
Table size: 120M rows.
Response time: 14 seconds.
What's your first move?
36
9
226
60,692
Jun 13
Have you ever wondered:
You and your friend both try to book the last seat on BookMyShow at the exact same second.
Only one of you gets it.
But how does the system decide who wins when both requests hit at the same time?
8
1
33
5,099
Jun 13
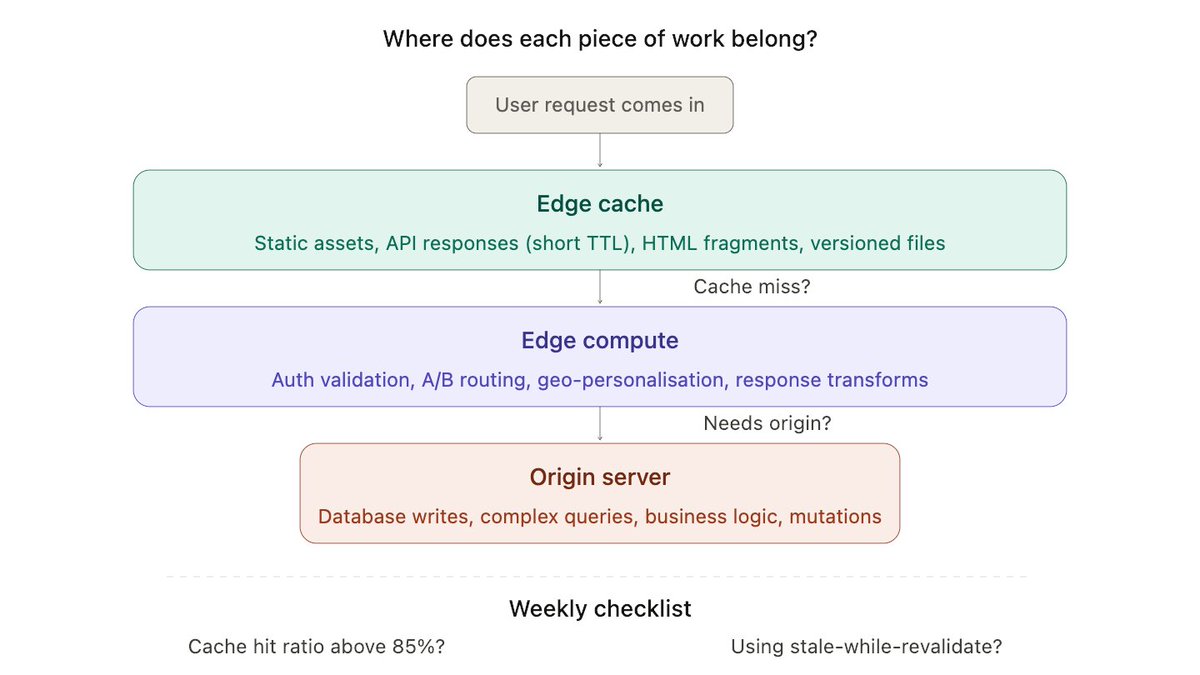
Scaling & Architecture, Day 3/25: Caching 🧵
Ask most engineers "where do you cache?" and they'll say Redis.
That's one layer. There are five.
And here's the thing. Most performance problems aren't solved by adding Redis. They're solved by caching at the right layer.
Sometimes that's the browser. Sometimes it's the OS. Sometimes it's a layer you didn't even know existed.
The five layers, from closest to the user all the way down to the hardware:
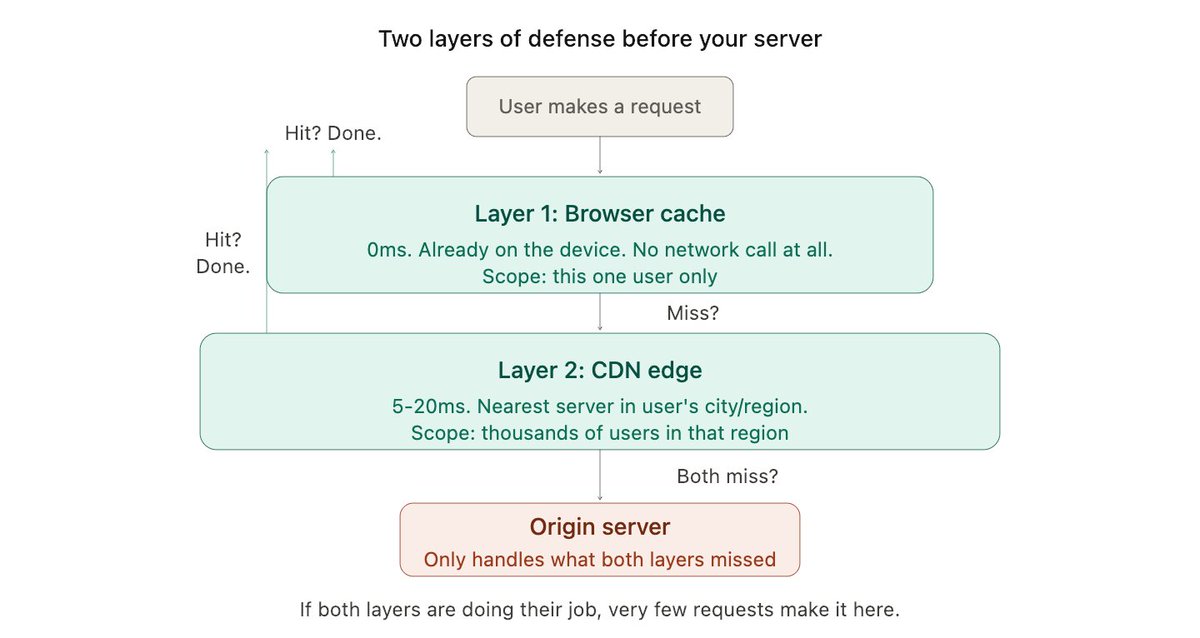
1. Browser cache
2. CDN edge
3. Application cache (Redis/Memcached)
4. Database query cache
5. OS page cache
Each one behaves differently. Different TTLs, different invalidation headaches, different failure modes.
Let me walk through all five. What they actually do, when they help, and when they'll bite you. 👇
1
1
24
3,629
Jun 13
Layer 3: Application cache (Redis / Memcached)
Ok this is the one everyone knows. The one people mean when they say "let's add caching."
But honestly? Most teams use it wrong. They throw Redis in front of their database and call it a day. Then wonder why it doesn't help much.
Let me break down how to actually think about it.
What it does:
Your app stores frequently-accessed data in an in-memory store (Redis, Memcached). Reading from memory is ~1-5ms. Reading from a database is 20-100ms. That's a 10-50x speedup.
The pattern that works (cache-aside):
1. App gets a request
2. Check Redis: "do I have this?"
3. YES → return it (cache hit, 1-2ms)
4. NO → query the database, store result in Redis, return it
5. Next request for same data → step 3 (fast path)
Simple. Effective. This is what 90% of teams should start with.
What to put in it:
- Results of expensive queries (aggregations, joins across big tables)
- Session data
- Frequently accessed objects (user profiles, product details, configs)
- Computed results (leaderboards, recommendation lists, feed rankings)
- Rate limiting counters
What NOT to put in it:
- Data that changes every request (you'll invalidate more than you serve)
- Very large objects (eating up memory for stuff that's rarely accessed)
- Data where staleness = real money lost (use the database directly)
Redis vs Memcached:
People ask this all the time. Simple answer:
Memcached: pure key-value. Multi-threaded. Dead simple. If all you need is "store this string, get this string," it's faster and lighter.
Redis: key-value PLUS data structures. Sorted sets, lists, pub/sub, Lua scripting. If you need a leaderboard, a rate limiter, a queue, or anything beyond simple get/set, Redis.
Most teams pick Redis because it does everything. That's fine. But if you're running a massive session cache and literally just need get/set at high throughput, Memcached is worth considering.
The mistake I see most often:
Teams cache everything with a 1 hour TTL and never think about invalidation. Then users see stale data and they blame caching itself.
Caching isn't the problem. Lazy TTLs are the problem. More on invalidation in tomorrow's thread (Day 4).
2
14
1,722