
Head of Product @temporalio Perpetually hiring amazing dev🥑. Writer for @stackoverflow. Game engine dev, dogs.
Joined March 2017
- Tweets 2,448
- Following 295
- Followers 1,780
- Likes 2,014
168 Photos and videos







It's genuinely unbelievable to think we went from 5 people working on an OSS project 2 years ago to a $1.5B business now. How did we do it?
1. Hire amazing people
2. Never stop investing in your community
16 Feb 2022

We are incredibly excited to announce our $103M Series B led by @IndexVentures. This funding proves that if you relentlessly listen to people and refuse to compromise on great design, the results will be staggering. We are so grateful to our community.
1
5
49
I recently ran an AI experiment with @Resourcely with a goal to generate reliable and secure Terraform based on a natural language. While this may sound trivial, we found that the devil is really in the details. Read more here:
resourcely.io/post/just-anot…
1
2
5
879
Ryland retweeted

23 May 2024
Building always-on, business-critical AI applications or agents on a constantly updating and growing volume of unstructured data requires resilient and fast data infrastructure.
I am super excited to finally announce @tensorlake's open-source, real-time data framework, Indexify.
Real-time processing: Optimized for tasks like summarization, extraction, embedding, and parsing, Indexify works well with frequently updated data. It can ingest any data modality at scale, with incremental updates that don't require re-processing entire documents.
Reliability, Multi-Cloud and Hardware Acceleration: Indexify reliably processes data even during transient infrastructure failures, ensuring high availability . Extracted data is automatically stored in storage systems. Pipelines can run on GPUs, CPUs, and across multiple clouds for flexibility and resilience.
Observability: Fully observable, Indexify allows you to identify bottlenecks in extraction pipelines and retrieval APIs for semantic searches and SQL queries.
Indexify has been tested on AWS with hundreds of thousands of documents and images to ensure production-readiness.
It comes with retrieval APIs for RAG applications, autonomous agents or any AI application. It's fully extensible, allowing you to bring any model into pipelines.
Blog Post: medium.com/tensorlake-ai/ann…
GitHub: github.com/tensorlakeai/inde…
Website: getindexify.ai
Discord Community: discord.gg/vxQPZpp7bV
8
36
156
29,603
This is nonsense. Clearly a statement made by someone who doesn’t work for commission (I don’t either).
Yes, working smarter is better than working harder. Want to know what’s even better? Working smarter and harder.
15 Jul 2023

If you’re working 70 hours a week you have one of three problems:
1) you are a poor delegator.
This is the most likely scenario (95%)
2) you have too much ego, believe you’re too special, and incorrectly believe only you can do the job.
This is very common (4.9%)
3) you’re in too hard of a business.
There are some businesses that just can’t be scaled. The market sucks and nobody has done it before you.
You’re solving a problem that doesn’t exist and trying to climb an impossible mountain.
This is rare (.1%)
1
665
Please help us continue to make @temporalio better by sharing feedback through our survey. You even get free swag and a discount for Replay.
29 Jun 2023
Hey Temporal Community! We're excited to share our 2023 Temporal Survey!
We'd love to hear your feedback on our product and this community. As a gift, you can chose to get free swag and 20% off a ticket to Replay (by completing the survey by July 13) 👉
t.mp/survey
1
3
864
We are having an in-person meetup for @temporalio on the 25th of May in Seattle. Come hang out with us f2f, or at least take our free pizza and beer.
x.com/temporalio/status/1658…
16 May 2023
🚀Counting down the days to our first in-person meetup in Seattle on May 25th!
Can't wait to finally meet the amazing Temporal community face-to-face, share ideas, and dive deep into the world of Temporal. Register here: bit.ly/453OQA6 #SeattleBound #opensource #devops
2
1
5
982
We made a post/video talking about our wonderful new @temporalio getting started experience. The new experience is only possible because of the hard work of our wonderful partners @datadoghq and specifically Jacob LeGrone.
temporal.io/blog/temporalite…
youtube.com/watch?v=-BJRQmNC…
7
19
3,409
Check out this awesome post about our exciting new @temporalio #python SDK.
temporal.io/blog/durable-dis…
This SDK was a real undertaking and labor of love.
4
10
1,395
Ryland retweeted

27 Jan 2023
The best part of being in a startup is getting a killer team together and letting them loose on a problem with no big company restrictions and processes to slow us down.
It's incredible what a small group of the right people can do!
1
34
1,655
Fourth video in my series where I share unrequested opinions about /r/productmanagement posts. This one even starts with some minor meta Reddit drama.
youtu.be/ifQkNaxcDe4
3
404
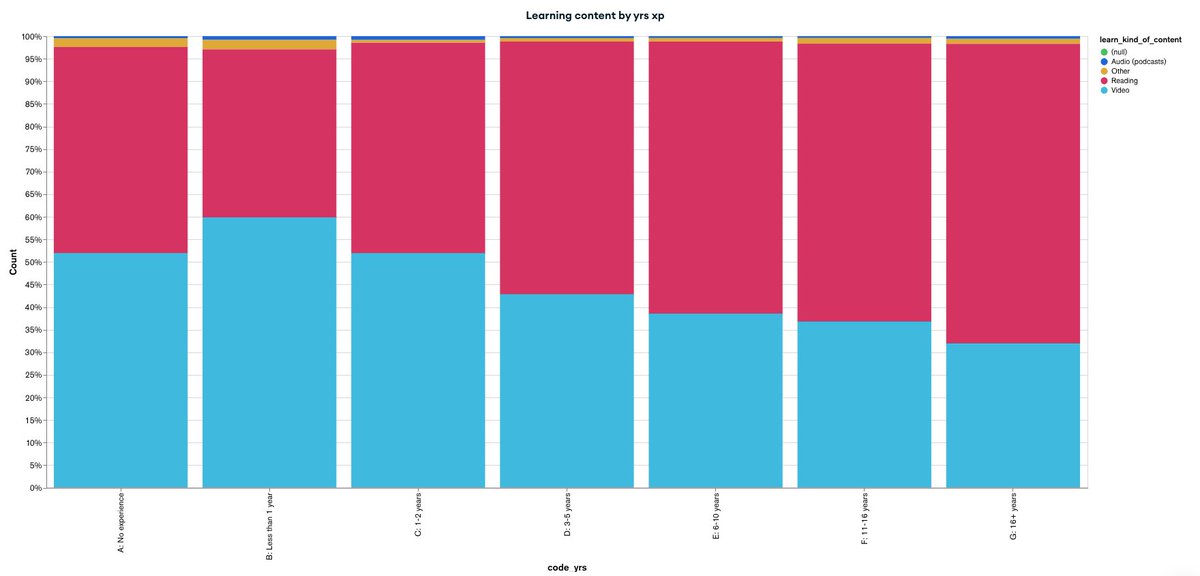
It's not just intuition. Having spent a lot of time playing with large developer survey datasets, preference for text based learning has a clear correlation with years of experience. Here is a visualization I have setup from Jetbrains data (n=>8000).
12 Dec 2022

Thoughts on this? My intuition is that it's mostly true: videos for learning, text for reference. I do wonder where books fit into the spectrum, though...
1
2
4
My second video reviewing various posts on /r/productmanagement
youtube.com/watch?v=ASll5cal…
old.reddit.com/r/ProductMana…
1
4
I made a video where I review some of the current posts on /r/productmanagement and share my unrequested opinions/perspective:
old.reddit.com/r/ProductMana…
That is 100% a render.
25 Nov 2022

The Cliff house both amazes and terrifies me in equal measures.
Imagine how cool a storm would be.

1
1