
Joined April 2023
- Tweets 37
- Following 268
- Followers 93
- Likes 472
5 Photos and videos




Andy Tang retweeted

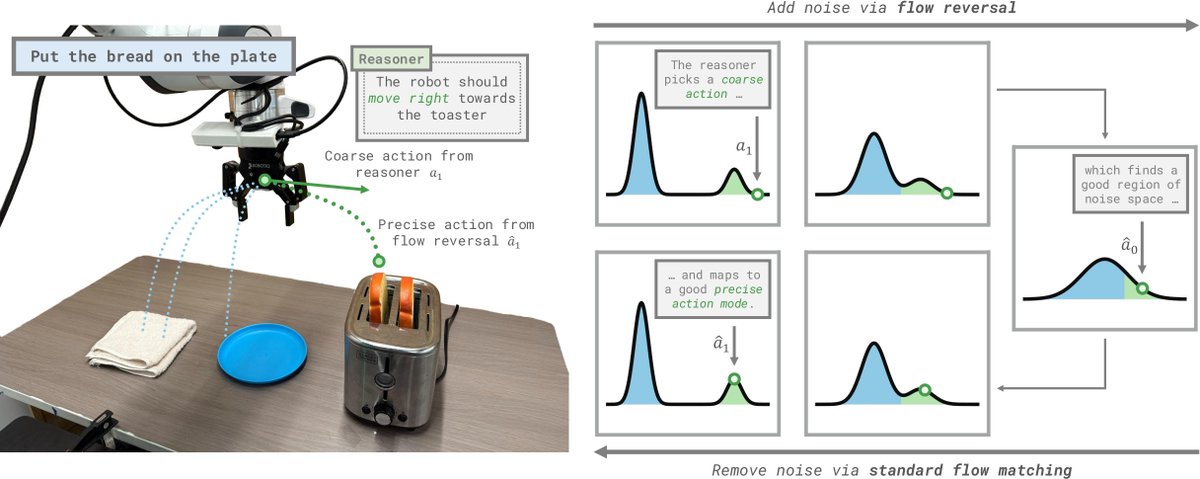
How can we elicit useful, semantically meaningful behaviors from generalist policies? We introduce Flow Reversal Steering (FRS) as a method to refine coarse, semantically meaningful commands into effective robot actions!
flow-reversal-steering.githu…
1/N
1
1
26
1,476

Jun 12
Generalist robot policies learn many useful skills, but struggle to select good behaviors for new tasks. To solve this, we introduce Flow Reversal Steering (FRS), a method to refine coarse semantic guidance into precise, in-distribution motions.
flow-reversal-steering.githu…
1/N
3
8
42
6,899
Jun 12
Also check out Will's thread here:
x.com/verityw_/status/206546…

Generalist robot policies learn many useful skills. How can we elicit relevant behaviors when faced with new tasks? We introduce Flow Reversal Steering (FRS): a way to refine coarse actions produced by semantic reasoning into similar precise ones!
flow-reversal-steering.githu…
1/N
1
1
121
Jun 12
And check out Sergey's thread here:
x.com/svlevine/status/206528…
Jun 12

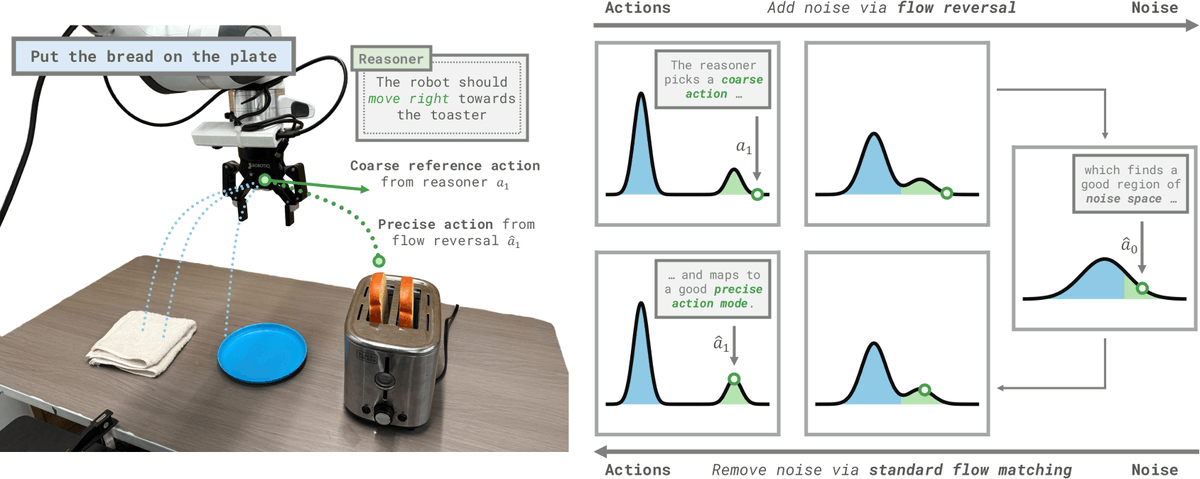
Flow reversal steering allows "steering" diffusion-based VLAs with high-level actions, for example from VLM reasoning. This also lets us run RL in the diffusion noise space with exploration guided by high-level reasoning: think through a task, then practice it! 👇
1
92
Jun 12
FRS also can speed up and improve noise space reinforcement learning, by focusing policy exploration on semantically sensible strategies. Adding one FRS success in the replay buffer allows our method to attain high performance on tasks that standard RL completely fails on.
5/N
1
2
65
Jun 12
We hope that FRS can be a stepping stone to a world where robots can adjust fine-grained behavior by integrating all kinds of semantic knowledge and reasoning!
Had a blast on this project with co-lead @verityw_, and amazing collaborators @ajwagenmaker, @chelseabfinn, @svlevine.
1
59
Andy Tang retweeted

Jun 12
Flow reversal steering allows "steering" diffusion-based VLAs with high-level actions, for example from VLM reasoning. This also lets us run RL in the diffusion noise space with exploration guided by high-level reasoning: think through a task, then practice it! 👇
5
58
542
61,434
Andy Tang retweeted

Apr 22
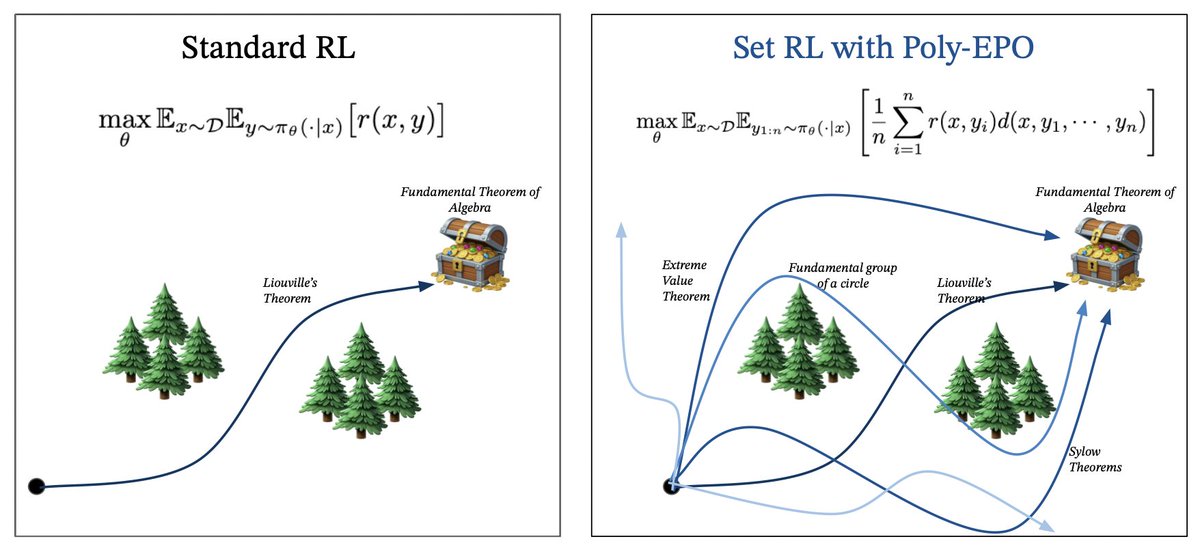
Deploying language models in scientific discovery domains requires extraordinary amounts of test-time compute for search algorithms. An ideal training algorithm should be designed with this goal in mind - that we want agents to learn how to not only exploit but also optimistically explore novel strategies. The agent should learn how to synergistically explore and exploit.
We propose Poly-EPO, a set RL algorithm that explores and discovers diverse reasoning paths. Work with @jubayer_hamid (co-lead), Shreya, @ShirleyYXWu, @HengyuanH, @noahdgoodman, @DorsaSadigh, and @chelseabfinn.
3
22
109
52,366
Andy Tang retweeted

Mar 30
How can we autonomously improve LLM harnesses on problems humans are actively working on?
Doing so requires solving a hard, long-horizon credit-assignment problem over all prior code, traces, and scores.
Announcing Meta-Harness: a method for optimizing harnesses end-to-end

78
284
1,762
592,983

How can robot policies be trained to best leverage VLMs' CoT reasoning and in-context learning for generalization?
The key is Steerable Policies: vision-language-action models that can be flexibly controlled in many ways!
steerable-policies.github.io
1/9

6
35
139
23,390
Andy Tang retweeted

1 Oct 2025
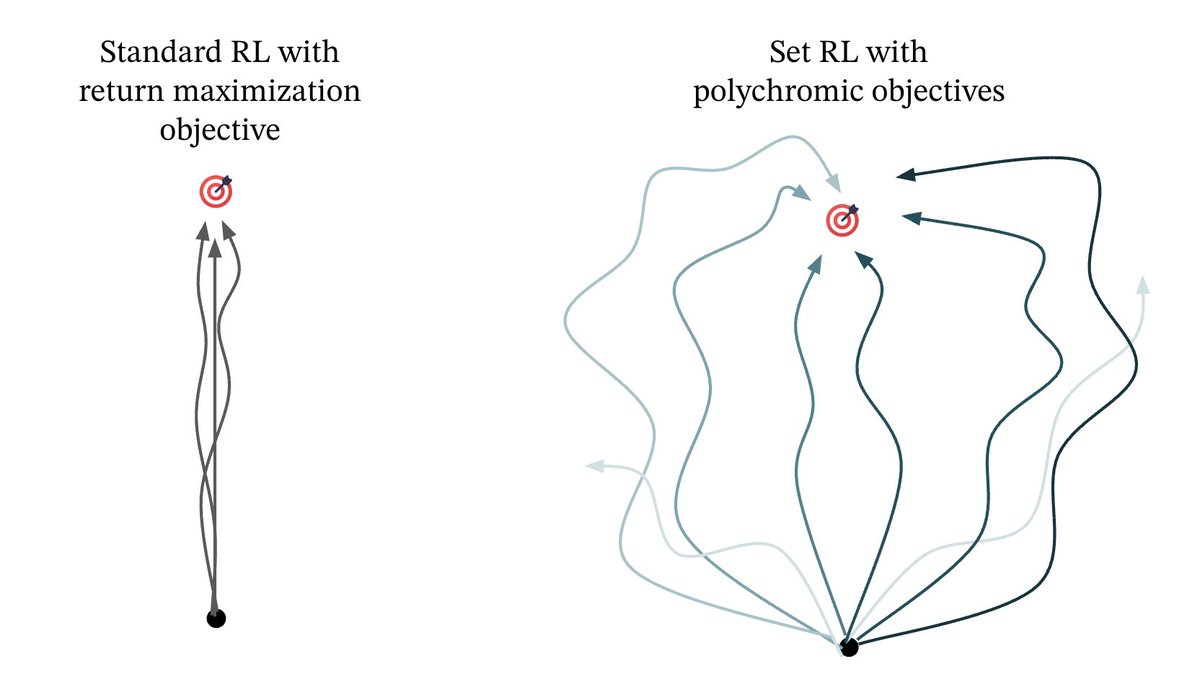
Exploration is fundamental to RL. Yet policy gradient methods often collapse: during training they fail to explore broadly, and converge into narrow, easily exploitable behaviors. The result is poor generalization, limited gains from test-time scaling, and brittleness on tasks where strategic exploration is necessary. We introduce a framework for training a policy over sets of generations and use it to induce exploration.
Work with @ifdita_hasan (co-lead), @ellenjxu_ , @chelseabfinn and @DorsaSadigh at Stanford 🧵
18
139
1,040
198,663
Andy Tang retweeted

26 Jun 2025
Very happy to share that our work on learning long-history policies received the Best Paper Award from the Workshop on Learned Robot Representations @RoboticsSciSys ! 🤖🥳
Check out our paper if you haven't already! long-context-dp.github.io
Thank you to all the organizers and the amazing collaborators @tangerinecoder, @liu_yuejiang and @chelseabfinn!


15 May 2025

Giving history to our robot policies is crucial to solve a variety of daily tasks. However, diffusion policies get worse when adding history. 🤖
In our recent work we learn how adding an auxiliary loss that we name Past-Token Prediction (PTP) together with cached embeddings enables us to reliably add longer history context to our robot policies! 🧠
We also show how PTP enables some test-time scaling techniques for robotics! 🚀
2
11
85
11,415
Andy Tang retweeted

16 Jun 2025
Even the smartest LLMs can fail at basic multiturn communication
Ask for grocery help → without asking where you live 🤦♀️
Ask to write articles → assumes your preferences 🤷🏻♀️
⭐️CollabLLM (top 1%; oral @icmlconf) transforms LLMs from passive responders into active collaborators.
Website: aka.ms/CollabLLM
Github: github.com/Wuyxin/collabllm
Blog: wuyxin.github.io/collabllm/#…
Paper: arxiv.org/pdf/2502.00640
🎯 Key insight: Rewards responses not by immediate helpfulness, but by their long-term impact on the conversation trajectory.
@MSFTResearch @StanfordAILab @stanfordnlp

9
60
209
72,563
Andy Tang retweeted

19 May 2025
How can robots autonomously handle ambiguous situations that require commonsense reasoning?
*VLM-PC* provides adaptive high-level planning, so robots can get unstuck by exploring multiple strategies.
Paper: anniesch.github.io/vlm-pc/
1
18
93
24,113
Andy Tang retweeted

17 May 2025
How do we make a scalable RL recipe for robots?
We study batch online RL w/ demos.
Key findings:
- iterative filtered imitation is insufficient
- need diverse policy data, eg using diffusion policy
- policy extraction can hinder data diversity
Paper: pd-perry.github.io/batch-onl…
15 May 2025

Robotic models are advancing rapidly—but how do we scale their improvement? 🤖
We propose a recipe for batch online RL (train offline with online rollouts) that enables policies to self-improve without complications of online RL
More: pd-perry.github.io/batch-onl…
(1/8)
3
24
169
22,863
Andy Tang retweeted

17 May 2025
🧠Memory is crucial for robots — to handle occlusions, track progress, stay coherent, etc. Yet, most VLA truncate context.
🤔Why is long-context hard for robot policies? And how can we fix it?
📄Our new paper: Learning Long-Context Diffusion Policies via Past-Token Prediction
15 May 2025
Giving history to our robot policies is crucial to solve a variety of daily tasks. However, diffusion policies get worse when adding history. 🤖
In our recent work we learn how adding an auxiliary loss that we name Past-Token Prediction (PTP) together with cached embeddings enables us to reliably add longer history context to our robot policies! 🧠
We also show how PTP enables some test-time scaling techniques for robotics! 🚀
2
10
46
3,602
15 May 2025
Was super fun exploring this! Most modern policies don't use history -- Diffusion Policy in particular gets a lot worse. We identify a simple ingredient for history improvement, and use it to improve efficiency and performance of long-context policies.
15 May 2025
Giving history to our robot policies is crucial to solve a variety of daily tasks. However, diffusion policies get worse when adding history. 🤖
In our recent work we learn how adding an auxiliary loss that we name Past-Token Prediction (PTP) together with cached embeddings enables us to reliably add longer history context to our robot policies! 🧠
We also show how PTP enables some test-time scaling techniques for robotics! 🚀
2
5
700