
Canal do YouTube sobre tecnologia e inteligência artificial
Joined June 2021
- Tweets 114
- Following 112
- Followers 83
- Likes 366
42 Photos and videos













Humans have an average of 200-250 ms of latency when speaking to each other.
This voice model is even faster: only 110 ms of latency!
Open-weights ←You don't need to pay anyone to use it.
8B parameters ← Small and cheap to host and run.
You can run it locally by cloning the Github repository. They published the instructions in the repository below.
Open models keep getting stronger!
Jun 3

Today, we’re excited to introduce Miso One, the most emotive voice model in the world.
Miso One is an 8-billion-parameter text-to-speech model for highly expressive speech generation. It emotes like a human and responds faster than a human, with just 110 milliseconds of latency.
We’ve open-sourced the model weights, with API access coming soon.
Hear how Miso One sounds in the thread below.
17
53
906
212,135
tech mumus retweeted

Mar 2
--dangerously-skip-permissions

189
1,080
15,375
655,566

10 Nov 2025
Airlines have a secret: the flight price you see depends on YOUR location.
So I built a Python script, powered by @thordata, that pretends to be in 8 countries at once to find the
cheapest fare.
Watch how it works and grab the script for FREE! ✈️💰
1
2
75
16 Aug 2025
Super proud of getting the 3rd place in the Railway Hackathon!! Thanks @railway for the opportunity!!

Content Depth 3️⃣ 3rd place:
Mosaic, a knowledge management system (techmumus.substack.com/publi…)
1
1
3
131
14 Aug 2025
1
1
2
163
11 Aug 2025
🧠 Just shipped MOS•AI•C - an AI-powered knowledge management system that actually understands your notes!
Deploy in one click on @Railway: railway.com/deploy/mosaic?re…
1
28
tech mumus retweeted

25 Jun 2025
🚀 AgentTip: OpenAI assistants inside any Mac app.
Type @idea brainstorm an onboarding flow, hit ⏎, and AgentTip swaps the trigger for the assistant’s reply—right where you were typing. No context-switch, no copy-paste.
One-time payment $4.99.
#MacApps #ChatGPT #AIProductivity
1
1
105
tech mumus retweeted
24 Jul 2025
The era of AI app subscriptions is coming to an end…
Thanks to the advent of lightweight edge AI models and frameworks like cactus - developed by @RomanShemet (backed by @ycombinator) AI apps can run 100% on the phone
My offline Plant ID app is proof:
👉 apps.apple.com/br/app/plant-…
No more cloud fees. No more monthly charges.
Just fast, private, one-time apps.
2
2
6
369
tech mumus retweeted

30 Mar 2025
I've spent 200 hours Vibe Coding games and apps.
It's insane what you can build with just your voice and AI...ANYONE can do it.
Here's everything I learned about Vibe Coding: 🧵

33
86
943
171,573
30 Mar 2025
That's amazing! New Playwright MCP Server, controls the browser, open countless doors! Thanks Debbie and Playwright team!
In this video we implement it in Cursor analysing a platform like Amazon (Mercado Livre)
@playwrightweb @debs_obrien
2
3
338
tech mumus retweeted

28 Feb 2025
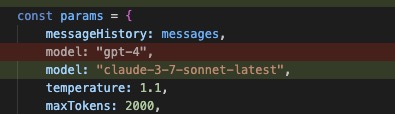
After many hours of scrutinizing humor in LLM outputs, this one by Claude 3.7 is the funniest by far.
28 Feb 2025

LOL!!
Claude (via Cursor) randomly tried to update the model of my feature from OpenAI to Claude 🤯
(my request was totally unrelated)
113
260
7,208
507,155
16 Jan 2025
Tutorial - Creating Agents With PydanticAI
Tutorial - Criando Agentes com o PydanticAI
@pydanti_ai @pydantic
1
41
10 Jan 2025
Step by Step Tutorial - Installing Langflow with Coolify
Tutorial passo a passo para instalação do Langflow usando o Coolify
@langflow_ai @coolifyio
youtu.be/Zt-t1XQrouA
2
38