
Economics & AI @ @METR_Evals (ex-openai) tecunningham.github.io
Joined March 2009
- Tweets 649
- Following 3,041
- Followers 9,927
- Likes 12,865
64 Photos and videos







Jun 10
Q: what can we say about the fixed-point of agent optimization loops? I can't find much on this.
Suppose you ask an agent to produce an output, then keep improving it, over and over. What happens?
E.g. write a paper, tell a joke, write a computer game, optimize an algorithm. (1/n)
2
3
23
3,758
Jun 10
You could perhaps categorize failures in this way:
1. The loss landscape is high-dimensional and it's too hard to find the gradient.
2. The loss landscape is low-dimensional but non-convex, and you get stuck in local maxima.
3. You don't know the true loss (non-verifiable) and so you end up in a part of the landscape that is OOD, and so self-verification is miscalibrated.
1
3
965
Jun 10
The most relevant work I could find uses pretty old models:
1. Self-Refine (Madaan et al. 2023), uses GPT-4. Finds quality increases in simple problems over a few iterations, then plateaus.
2. Huang et al. (ICLR 2024), "LLMs Cannot Self-Correct Reasoning Yet", uses GPT-4t. GSM8K grades get *worse* with self-correction.
3. Telephone game (Perez et al., ICLR 2025). Uses GPT-4o-mini. But this is just *repeating* stuff, not optimizing something.
2
4
435
Jun 8
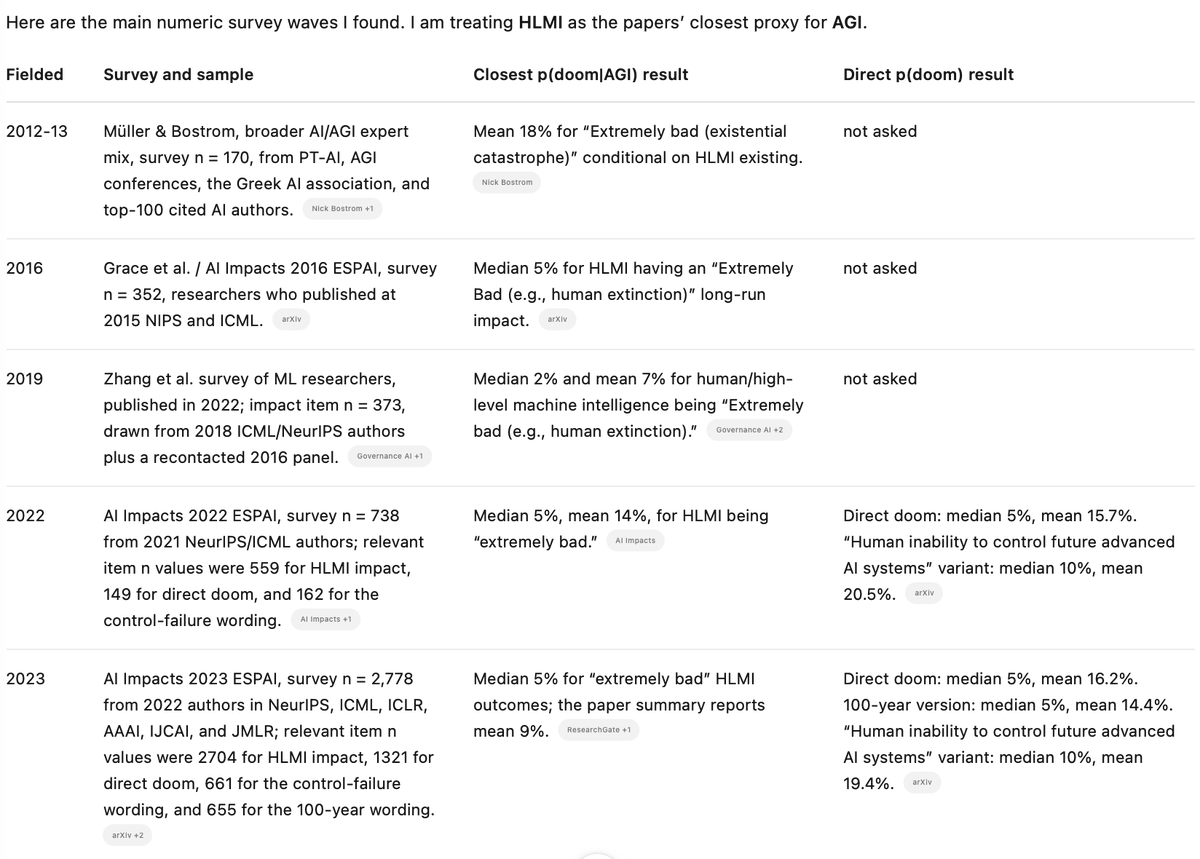
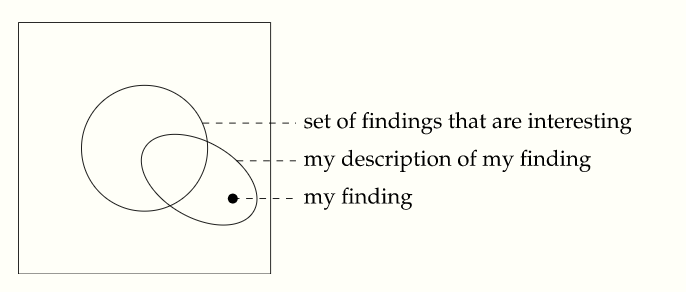
A list definitions of RSI and associated concepts (there are a lot!).
It's mostly agent-written. Tell me if I'm misquoting or missing any:
tecunningham.github.io/posts…
2
9
48
6,593
tom cunningham retweeted

Jun 6
Enjoyed giving a talk about the economics of AI at the econometric society meeting this morning. Some motivating facts/ideas that all economists should know about AI below. 1/n
6
52
251
40,779
Jun 3
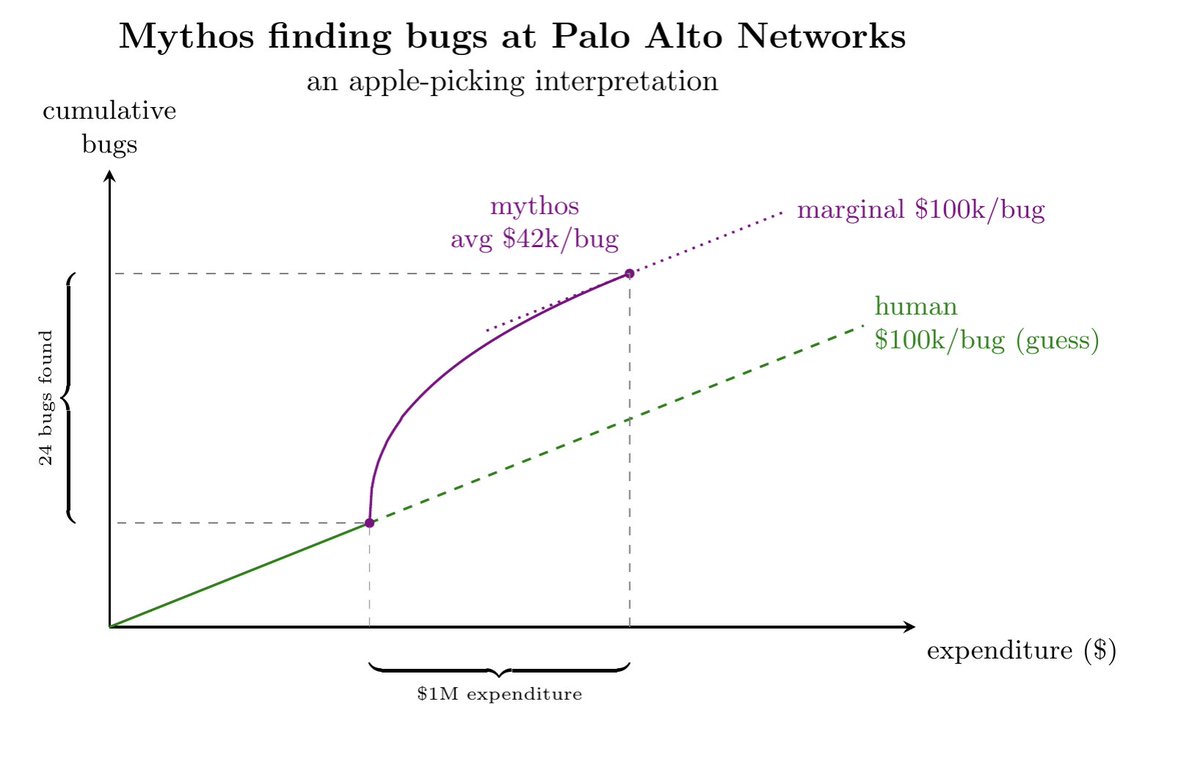
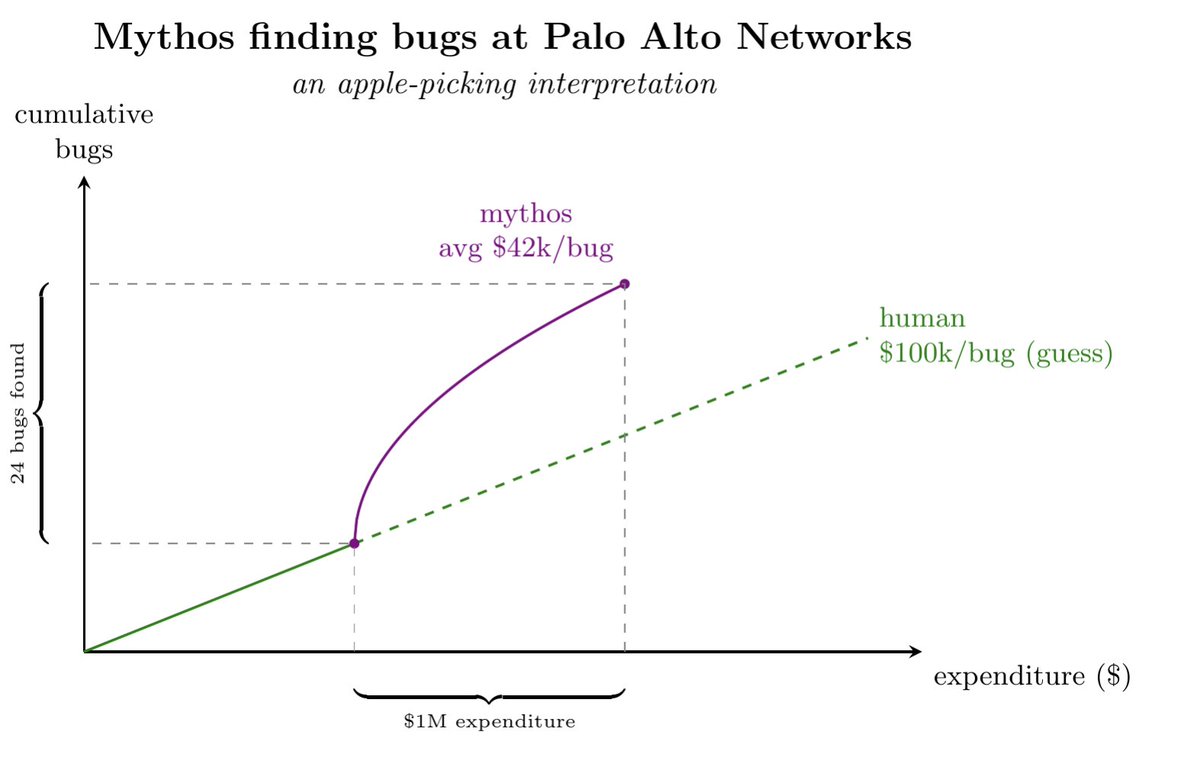
My very speculative reconstruction of the economics of using LLMs to find bugs:

Mythos at Palo Alto Networks "found more than two dozen critical vulnerabilities in around three weeks, roughly five times what the company would typically find using existing tools"
But the company "burned through more than $1 million worth of tokens using Mythos"
10
12
118
16,399
Jun 1
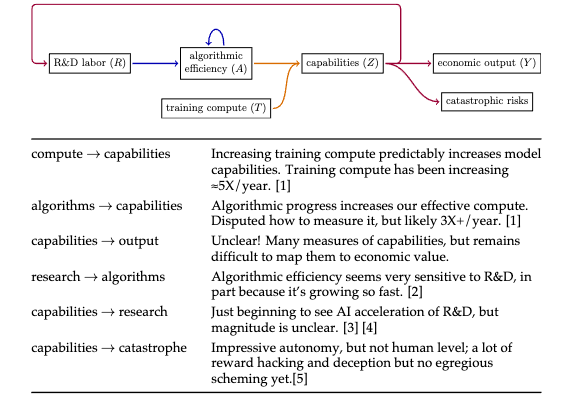
A very big picture of what's happening with AI (slides from a talk at UCSB):
5
20
109
12,194
Jun 1
[1]: epoch.ai/trends
[2]: epoch.ai/gradient-updates/th…
[3]: metr.org/blog/2026-05-11-ai-…
[4]: tecunningham.github.io/posts…
[5]: metr.org/blog/2026-05-19-fro…
1
2
10
1,560
Jun 1
The last line would probably be better: "Impressive autonomy, but not human level; a lot of reward hacking, some deception, but no egregious scheming yet."
1
4
1,088
Jun 1
End of an era at OpenAI -- Pamela did a streak of great work founding/running the econ research team, I’m grateful she hired me into it, and we continued many of the projects she started.
Jun 1

was rejected from posting the below to a billboard in kansas city, so hit slack instead :openai-heart:

2
69
6,921
May 29
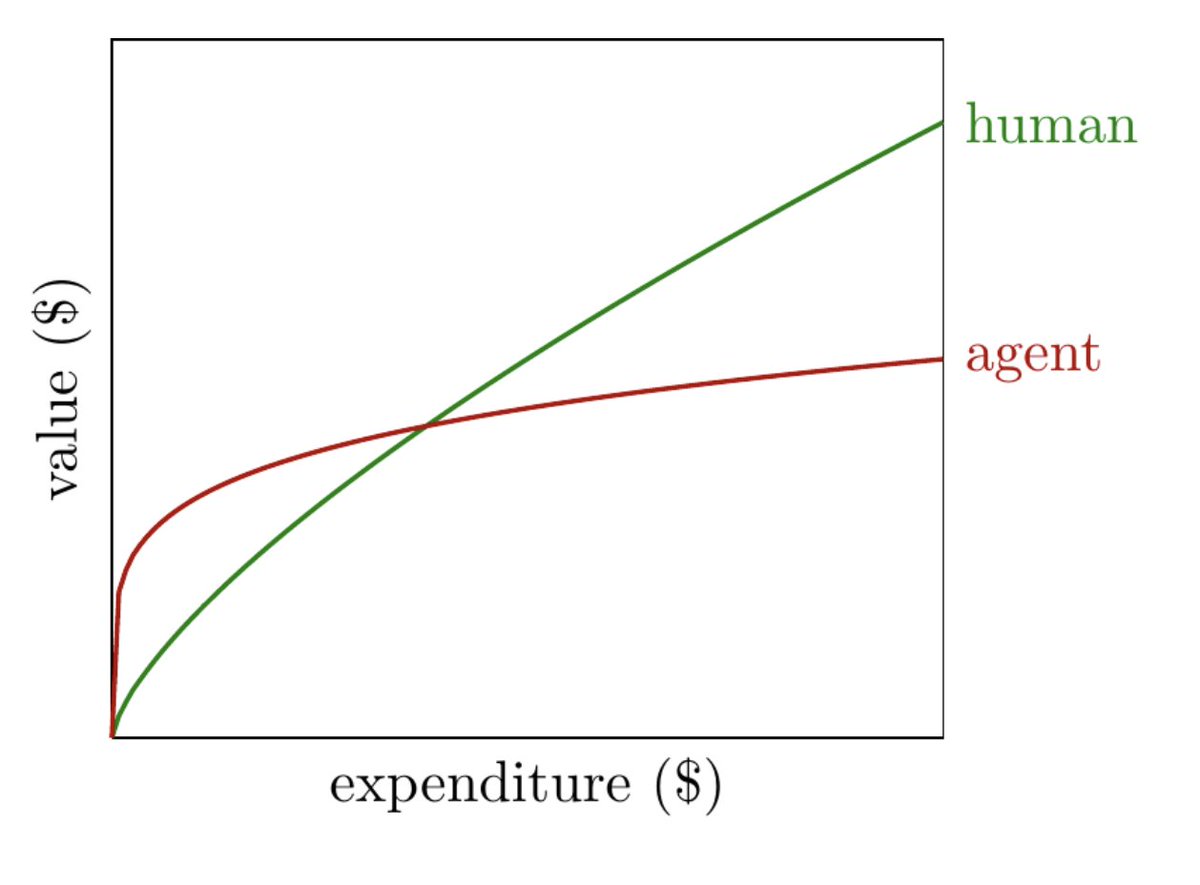
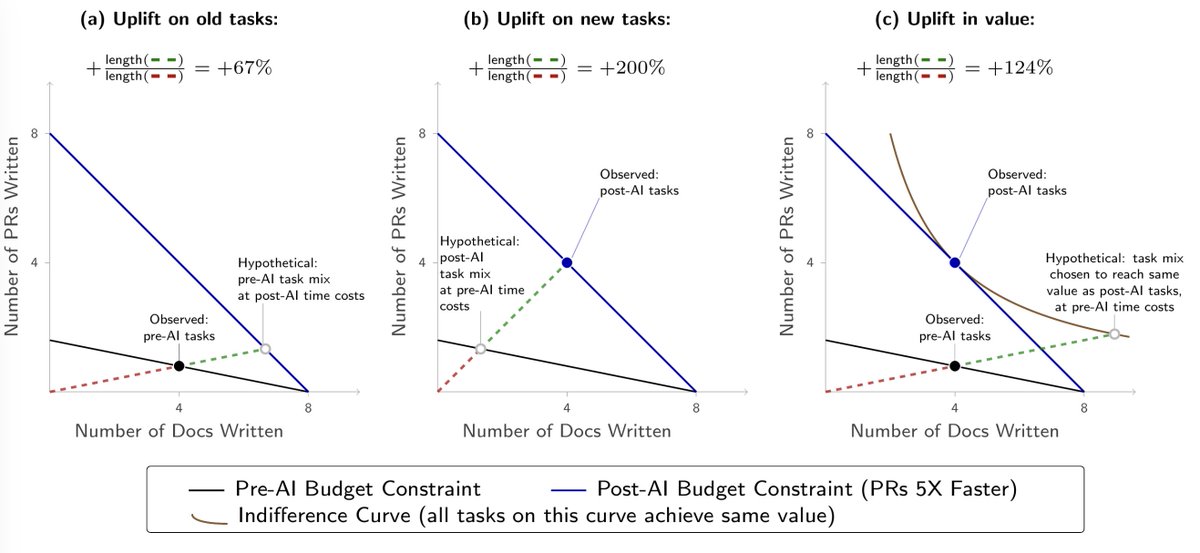
I think most domains look like this at the moment: the returns to expenditure on agents diminish much more quickly than the returns to expenditure on human labor: (1/n)
34
99
708
182,549
May 29
A test for this: if you doubled your token use, how much would you increase the value you get from AI? This gets elasticity.
My guess would be it's much less than double. (and if you don't usually hit your token limits then implied marginal value is zero).
2
1
62
4,746
May 29
Inference-time scaling rotates the red curve upwards, increasing the elasticity.
But there's also the countervailing force of distillation: once an agent solves a problem once, it then becomes cheap to do it again.
2
52
3,953
May 28
My sense is that giving a computer programmer an AI agent is like giving a lumberjack a chainsaw. They can immediately see that it's powerful, & they'll pay a lot for it, but the first time they use it they cut off their leg.
Programmers have a ton of tacit knowledge about how to build software, but now all their instincts need to be recalibrated, & it takes some time.
6
6
52
4,164
tom cunningham retweeted

May 28
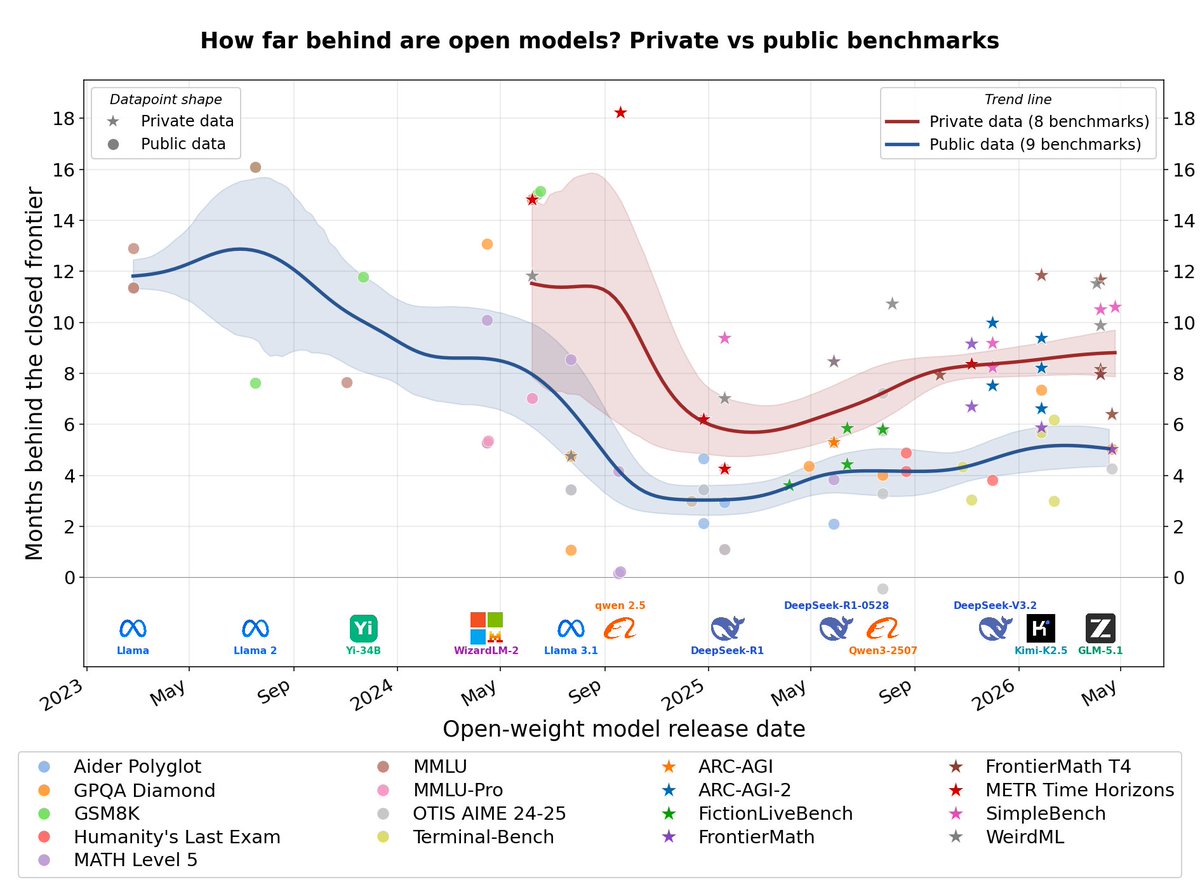
How far behind are open models?
Across 17 selected benchmarks, private ones show a gap of 8-10 months today, almost 2x the gap on public ones (4-6 mo).
More discussion (including limitations), code and blog in the thread.
7
24
204
42,043