
Simplifying End-to-End API Testing.
Joined March 2020
- Tweets 382
- Following 84
- Followers 32
- Likes 180
268 Photos and videos















Jun 13
This was untimely
Jun 13

As a result of a US government directive, we are suspending access to Claude Fable 5 for all users. You can continue to use all other Claude models.
Here’s what this means for you:
Across Claude products, new sessions will run on your selected default model or Opus 4.8, and existing Fable 5 sessions will end with an error.
On the Claude Platform, requests to Fable 5 will also return an error. Please update your integrations to other Claude models.
We know this is a disruption to your workflows; we appreciate your patience and support.
2
Jun 12
Sometimes all it takes is a fresh perspective… or a colleague who literally cleans your glasses 😄
Helping each other see just how lucky we are to be here at @QyrusAI
#WorkHumor #TeamVibes #Gratitude #workplace #work #glasses #qapi #qyrus
7
Jun 11
LLM in production with 50,000 daily users.
Tested with: 5 hand-picked examples.1% error rate = 500 wrong answers per day.
2% hallucination = compliance risk.
5% tone failure = churn.
Proper evaluation requires hundreds (or thousands) of real-world scenarios, adversarial testing, and continuous monitoring.
That's what you get with qAPI. Better product performance with easy evaluation.
#qapi #product #llm #claude #chatgpt #cursor #tools #buildinpublic #demo #testcases

40
Jun 10
It will be a good space to see what people can come up with Fable.
Jun 9

Fable 5 on Hyperagent is producing the most creative, ambitious work we've ever seen from our agents.
They're self-improving for hours towards open-ended goals. Visual reasoning has spiked noticeably. Outputs are consistently higher quality than Opus, occasionally at lower cost.
5 of our test cases below vs. Opus 4.8 👇
1. Visualize all asteroids in the solar system from NASA data
2. Design a site plan for a 100 acre fitness retreat
3. Reconstruct Apollo control panels from technical PDFs
4. Simulate the supply chain for World Cup jersey sales based on match outcomes
5. Show the effects of solar flares on aurora
Fable 5 is now available on Hyperagent.
1
65
Jun 9
🧵6 Things Your API Test Report Isn’t Telling You Most teams look at a green dashboard and feel confident to ship.
But behind those green checks, serious problems are hiding. Here are 6 blind spots that could be costing you:
6
2
20
Jun 9
5/7
No Stakeholder-Friendly View Developers read raw JSON
PMs read nothing
QA makes their own spreadsheet
Your test report lives in 3 different incompatible formats — and none of them are actually useful.
1
6
Jun 9
4/7
Flaky Tests Counted as Stable That test failing 1 out of every 4 runs? It’s still included in your pass rate. Some days it makes you look good. Other days it tanks your numbers. You’re measuring noise, not quality.
1
1
12
Jun 9
3/7
No Difference Between Runs Tuesday’s run = green.
Wednesday’s run = green. But something changed. Without a clear diff view, you have no idea what broke or improved. Regressions hide in plain sight.4/7
5
Jun 9
2/7
Latency is Missing Your tests check status codes and response bodies — but almost never check how long it takes. An endpoint returning 200 OK in 4.2 seconds is failing your users. Your report still marks it as passing.
5
Jun 9
1/7
Pass Rate ≠ Coverage Your report says “98% pass rate.” That only means 98% of the tests you wrote passed. If you’ve only covered 40% of your API, your real confidence is closer to 39%. Not 98%.
12
Jun 9
New GPT-5.6, Claude Mythos, Grok 5, Gemini 3.5 Pro, and more dropping every week…It’s getting chaotic.
With so many new models and versions flooding in, most people building with LLMs are now more confused than ever about which one to use.
This is exactly why you need to evaluate your LLMs properly — don’t just chase the hype. Test them on your actual tasks, compare results, and pick what truly performs for your use case.
Confusion is temporary. Good evaluation is forever. What are you currently using your custom LLM for?
161
Jun 8
How do you audit an AI that never gives the same answer twice?
Enterprises are rushing to deploy Large Language Models (LLMs) to secure a competitive edge. But traditional software quality assurance is hitting a brick wall. Traditional testing relies on hard assertions—you pass an input, and you expect a matching, predictable string.
But with GenAI, your software generates entirely unique, non-deterministic text for every single user.
The Industry's Massive Gap:
Right now, organizations are forced to rely on manual spot-checking, which eats up hundreds of engineering hours, or weak keyword-matching filters that completely miss the context.
The industry doesn't just need a bigger testing queue—it needs an automated, semantic judge that evaluates generative AI outputs the same way a human expert would.
That is exactly why with qAPI LLM Evaluator.
We’re moving beyond simple pass/fail checks to bring deterministic trust to non-deterministic systems. Here is what your engineering and compliance teams get with our structured evaluation engine:
📊 1-5 Semantic Rating System: Say goodbye to guesswork. Assign clear, graded scores based on relevance, context adherence, and linguistic alignment—backed by transparent reasoning for every single grade.
🛡️ Deep Hallucination Detection: Automatically cross-reference generated AI claims against your verified internal source documents. Identify assertions without evidence before they ever reach a customer.
🎯 Guaranteed Faithfulness: Ensure your virtual assistants, chatbots, and autonomous agents stay strictly on-task. Platforms leveraging our AI Quality Suite achieve up to 95% faithfulness in validated outputs.
Whether you are trying to block PII leaks, prevent regulatory non-compliance, or ensure your brand voice remains perfectly consistent across millions of unique prompt variations, you need visibility over the entire architecture—not just the final text box.
Quality shouldn't be an afterthought in your AI pipeline. It should be the steering wheel for your innovation. 🎡
🚀 The qAPI LLM Evaluator waitlist is officially open. Stop guessing what your AI is telling your users. Click the link below to claim early access and secure your AI pipeline today
#LLMEvaluation #GenerativeAI #AITesting #SoftwareQuality #LLMops #DeepLearning #qAPI #Qyrus #product #productlaunch
1
60
Jun 5

Every line of code we write has an impact. Not just on our apps, but on our planet.
We don’t usually think about software testing as an environmental issue. But the truth is, traditional testing pipelines run on massive server infrastructure, consuming vast amounts of energy around the clock.
That carbon footprint adds up.
At Qyrus, we believe that building a better digital future shouldn't come at the cost of our physical one. By redesigning testing with intelligent, cloud-based automation, we’re helping teams optimize their workflows, shorten test cycles, and drastically reduce idle server strain.
It turns out that building more efficient software is one of the best ways to build a more sustainable world.
Happy World Environment Day. Let's make every test count.
🌱 Learn more at qyrus.com/
#WorldEnvironmentDay #GreenTech #SoftwareTesting #DevOps #Sustainability
1
23
Jun 4
Newman shows 100% pass rate. 55% of your endpoints have zero tests. That's not a quality gate. That's a confidence trap. Track coverage, not just pass rate. 🧵
Drop your coverage % in the comments. We'll tell you if it's healthy.
#APITesting #QualityEngineering #CI_CD #TestAutomation #DevOps
1
11
Jun 3
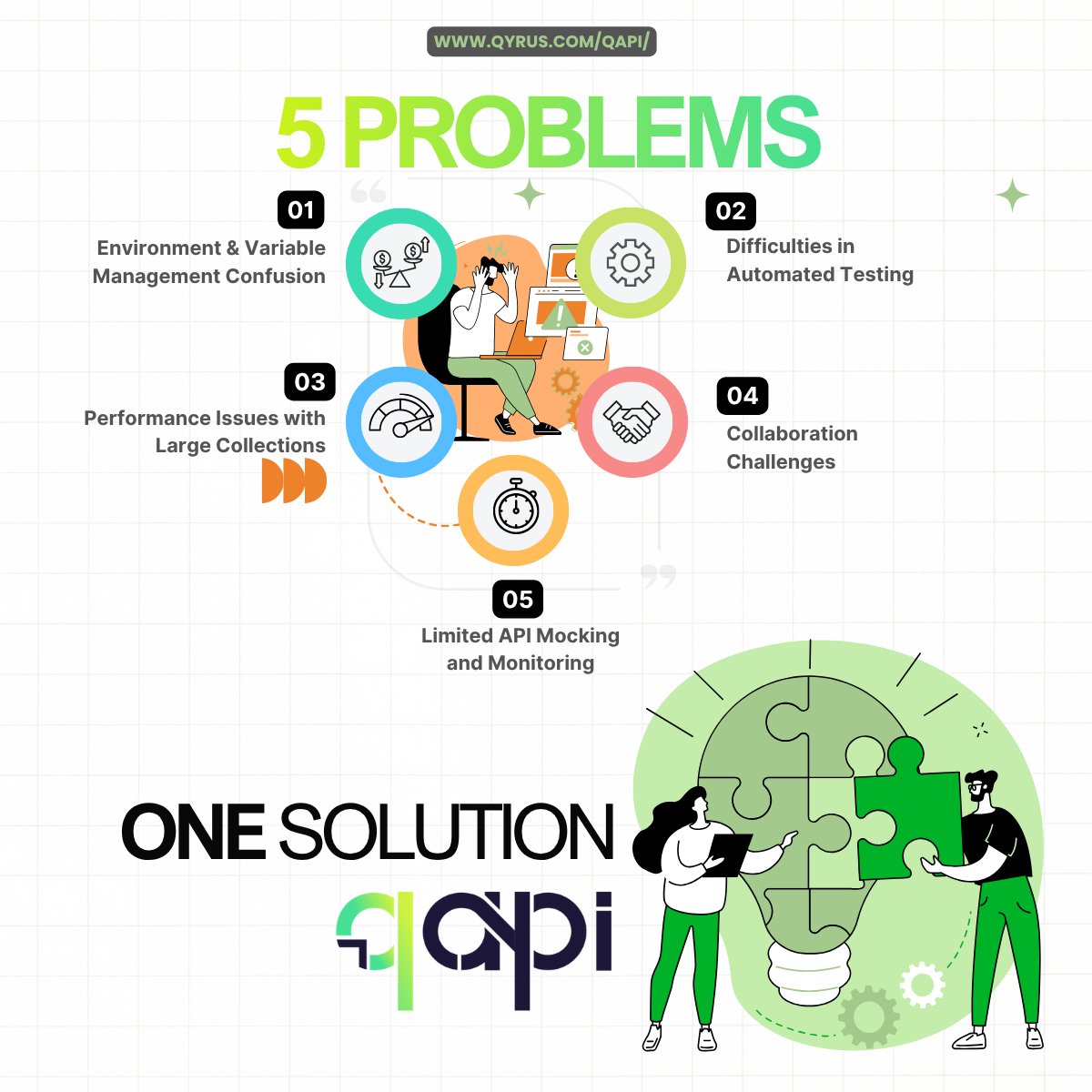
What are the 5 major API Testing problems you face today?
#API #APITesting #QualityEngineering #SoftwareTesting #DevOps #DeveloperTools #Microservices #AutomationTesting #APIMonitoring #qAPI
0%
Breaking Environments
0%
Writing Test Cases
0%
Managing API Collections
0%
Load Testing Limitations
0 votes • Final results
10

What happens when you strip away the corporate scripts, the rehearsed slide decks, and the standard talking points?
You get the absolute truth about where software engineering is heading.
Welcome to the launch of 𝐐𝐲𝐫𝐮𝐬 𝐂𝐚𝐧𝐝𝐢𝐝; a brand-new series dedicated to quick, raw, and completely candid interviews with the actual folks from Qyrus.
We’re sitting down with our engineers, leaders, and thinkers to get their unfiltered perspectives on the realities of modern engineering.
For our very first episode, Senior Platform Engineer, Harshitha N takes the interviewer's seat to have a real, pull-no-punches chat with @RaoulKumar, VP of Product Strategy.
They dive straight into the big topics:
☑️ 𝐓𝐡𝐞 𝐂𝐨𝐧𝐭𝐞𝐱𝐭 𝐏𝐫𝐨𝐛𝐥𝐞𝐦: Why scaling your test automation without actual context just creates unnecessary noise.
☑️𝐓𝐡𝐞 𝐂𝐚𝐭𝐜𝐡-𝐔𝐩 𝐓𝐫𝐚𝐩: Why waiting until the end of a cycle to find defects means you're already too late.
☑️𝐃𝐞𝐬𝐭𝐫𝐨𝐲𝐢𝐧𝐠 𝐒𝐢𝐥𝐨𝐬: How fragmented tools and disconnected strategies slow down enterprise teams.
True quality engineering isn't about validating outcomes after the fact; it’s about actively shaping them from the start.
Check out the teaser to see what we mean, and then click the link to watch their full conversation.
👉 Watch the full interview here: lnkd.in/gpDE2pQ9
#QyrusCandid #QualityEngineering #SoftwareTesting #DevOps #TechLeadership
2
5
149