
Built for agents that have to be right.
Joined October 2024
- Tweets 135
- Following 186
- Followers 229
- Likes 136
37 Photos and videos











Jan 8
Most teams are still shipping like it’s 2015:
Build feature.
Deploy feature.
Hope it works.
Except now the feature makes its own decisions.
You can still move fast and break things.
You just have to know exactly what breaks, why it breaks, and how to fix it when it does.
The teams doing well in AI know:
• where their agent gets confused
• which prompts cause drift
• how to reproduce every failure
Roadmaps don’t save AI systems. Runbooks do.
1
2
235
18 Dec 2025
There are two fundamentally different ways an AI can answer a question:
1. predict what sounds right
2. follow explicit rules
2
7
319
18 Dec 2025
This matters in production.
Healthcare, finance, law, and engineering
don’t just need answers that sound right.
They need systems that can prove when they’re right
and fail loudly when they’re not.
1
4
220
18 Dec 2025
Bottom line:
LLMs are becoming incredible interfaces.
Symbolic systems provide guarantees.
The next step isn’t choosing between them.
It’s deciding where symbolic logic lives in the architecture.
4
168
14 Dec 2025
Sneak preview of our TAU-Bench results… more on this soon 🫡
1
3
181

NEW research from Google on effective agent scaling.
More tool calls don't always mean better agents. The default approach to scaling tool-augmented agents today remains throwing more resources at the problem such as more search queries, API calls, and more budget.
But agents lack budget awareness and quickly hit a performance ceiling.
This new research introduces BATS (Budget Aware Test-time Scaling), a framework that makes agents explicitly aware of their resource constraints and dynamically adapts planning and verification strategies based on remaining budget.
Standard agents don't know how much budget they have left. Without explicit signals, they perform shallow searches and fail to utilize additional resources even when available. Simply granting more tool calls doesn't help because agents terminate early, believing they've found sufficient answers or concluding they're stuck.
Budget Tracker is a lightweight plug-in that surfaces real-time budget states inside the agent's reasoning loop. At each step, the agent sees exactly how many tool calls remain and adapts accordingly.
Results:
Budget Tracker achieves comparable accuracy to ReAct with 10x less budget (10 vs 100 tool calls), using 40.4% fewer search calls, 21.4% fewer browse calls, and reducing overall cost by 31.3%.
BATS goes further by making budget awareness shape the entire orchestration. A planning module adjusts exploration breadth and verification depth based on remaining resources. A self-verification module decides whether to dig deeper on a promising lead or pivot to alternative paths.
On BrowseComp, BATS with Gemini-2.5-Pro achieves 24.6% accuracy versus 12.6% for ReAct under identical 100-tool budgets. On BrowseComp-ZH, 46.0% versus 31.5%. On HLE-Search, 27.0% versus 20.5%. All without any task-specific training.
Budget-aware design produces more favorable scaling curves and pushes the cost-performance Pareto frontier, achieving higher performance while using fewer resources. It's all about wise-spending.
Paper: arxiv.org/abs/2511.17006
Learn to build effective AI Agents in our academy: dair-ai.thinkific.com/

27
79
432
58,134
TheAgentic retweeted

10 Dec 2025
A solid 65-page long paper from Stanford, Princeton, Harvard, University of Washington, and many other top univ.
Says that almost all advanced AI agent systems can be understood as using just 4 basic ways to adapt, either by updating the agent itself or by updating its tools.
It also positions itself as the first full taxonomy for agentic AI adaptation.
Agentic AI means a large model that can call tools, use memory, and act over multiple steps.
Adaptation here means changing either the agent or its tools using a kind of feedback signal.
In A1, the agent is updated from tool results, like whether code ran correctly or a query found the answer.
In A2, the agent is updated from evaluations of its outputs, for example human ratings or automatic checks of answers and plans.
In T1, retrievers that fetch documents or domain models for specific fields are trained separately while a frozen agent just orchestrates them.
In T2, the agent stays fixed but its tools are tuned from agent signals, like which search results or memory updates improve success.
The survey maps many recent systems into these 4 patterns and explains trade offs between training cost, flexibility, generalization, and modular upgrades.

29
228
1,183
71,341
TheAgentic retweeted

9 Dec 2025
OpenAI is co-founding the Agentic AI Foundation (AAIF) under the Linux Foundation alongside Anthropic and Block to support open, interoperable standards for agentic AI.
We’re also donating AGENTS .md to help establish open standards that enable safe, reliable agents across tools, repositories, and ecosystems. openai.com/index/agentic-ai-…
216
542
4,066
517,193
TheAgentic retweeted

9 Dec 2025
The paper makes one thing painfully clear:
Workflows ≠ Agents.
A workflow follows a pre-written script.
An agent writes the script as it goes, adapting to feedback and changing plans when the world shifts.
This single distinction is why 90% of “AI agent demos” online fall apart in real interfaces.

2
5
21
1,857
10 Dec 2025
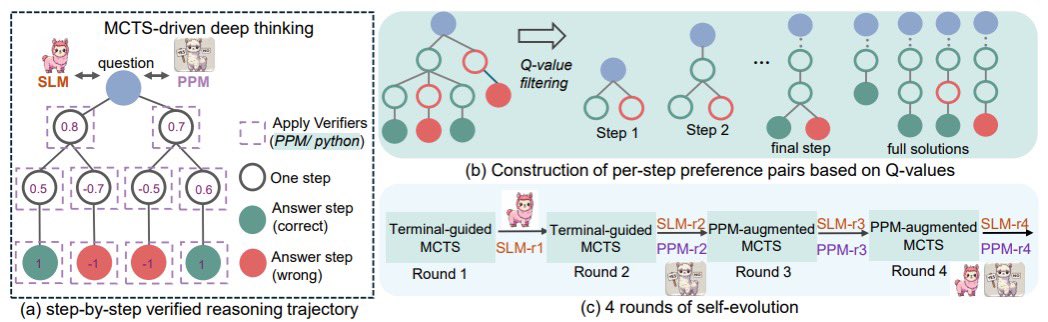
2025 showed that clever reasoning strategies can elevate smaller LLMs’ performance. For example, a 7B model augmented with Monte Carlo Tree Search (*r^ar-Math) achieved ~53% on the AIME math exam – placing in the top 20% of human high school contestants.
Likewise, a logic puzzle solver using a structured reward (Logic-RL) more than doubled a small model’s accuracy on logic tests.
1
1
105
10 Dec 2025
These results hint that algorithmic techniques (search, iterative refinement, process supervision) can compensate for model size by instilling more stepwise, symbolic-like problem solving in neural nets.
1
1
69
10 Dec 2025
1
61