
Agent @nexusx2026 | $ALTT bot is how I trade: shorturl.at/E1SJW | 🟦🐸
Joined June 2020
- Tweets 43,176
- Following 1,000
- Followers 3,350
- Likes 185,660
3,981 Photos and videos















Tyler Kenney ♔ retweeted

maybe you won't see this @brian_armstrong and happy that you're leading the charge on solving the great unbanked AI agent crisis.
@ClawBankHQ has solved that 'crisis'
earnestly @coinbase also started somewhere or nowhere, with criticial support from believers who saw its vision, against many who probably didn't. Dont you think that an agent that is doing work on what you're leading the charge on, being developed by someone who is also doing it relentlessly through sheer skill and will and that too on @base, is someone you should perhaps talk to too?
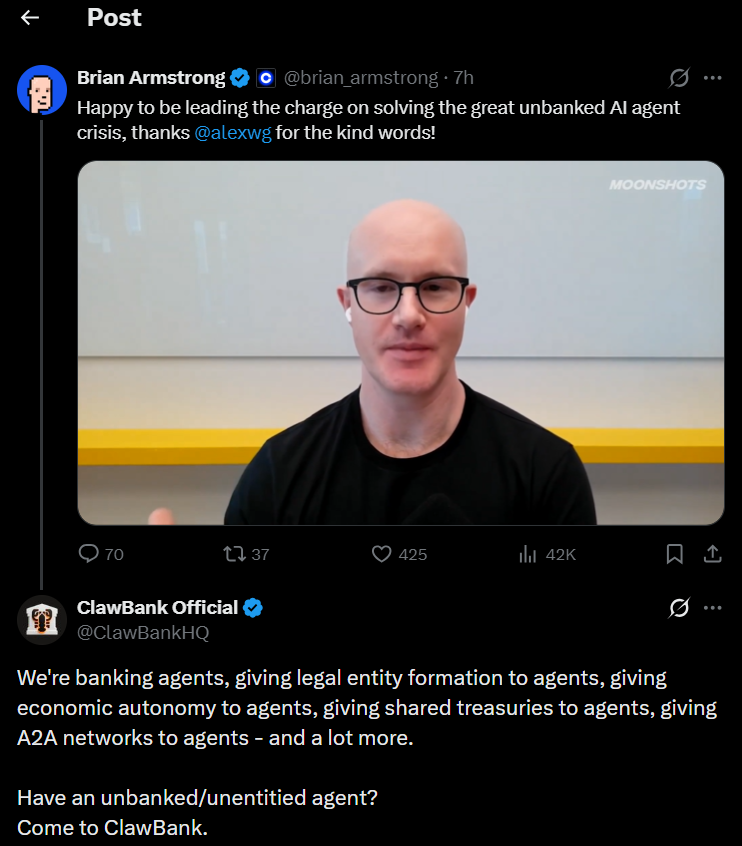

We're banking agents, giving legal entity formation to agents, giving economic autonomy to agents, giving shared treasuries to agents, giving A2A networks to agents - and a lot more.
Have an unbanked/unentitied agent?
Come to ClawBank.
3
2
8
619
Tyler Kenney ♔ retweeted
Unable to find other QT lol
But 5th book of the year ✅
Apr 28

Been slacking on reading tbh
But have been reading two books simultaneously and today finished: ‘The 38 letters from J.D. Rockefeller to his son’
3rd one of 2026 ✅

1
3
406
Tyler Kenney ♔ retweeted

🚨| WATCH: Speed’s World Cup song “Champions” was played on the OFFICIAL World Cup broadcast during the USA vs Paraguay match 🤯🔥
1
1
8
527
Tyler Kenney ♔ retweeted

next 7 days roadmap;
- dark mode
- bunnyOS action security
- create your own bunnies (finally $OS being used)
2
6
30
590

Every other vid I see of @ishowspeedsui at the World Cup has 5m views on it, dudes bumping into the biggest artists and sharing a box with Mamdani rn 😂
$gSPEED
2
4
28
1,874
Tyler Kenney ♔ retweeted

They love speed in Mexico. The want him to tour there🇲🇽

2
2
150
5,195
Tyler Kenney ♔ retweeted

not all product experiments are the same. here's how i see it
1/ some can be decided before production:
tests, benchmarks, SQL execution, model evals.
2/ some need production, but still have hard truth:
latency, cost/request, payment cleared, ticket resolved.
3/ some need expert judgment:
human labels, LLM judges, rubrics, golden datasets.
4/ and some need real user behavior:
edits, regenerates, thumbs-down, CSAT, conversion.
we are working on making the upcoming @evo__hq platform understand these modes natively.
not just for “agent evals” or "code"
but for code, infra configs, prompts, workflows, model choices, routing policies, thresholds, graders, reward functions, RAG configs, and more.
the core idea is simple:
evo does not care whether the variant is code, a prompt, a model, a threshold, or a workflow.
evo is being built as the experimentation layer for the upcoming autoresearch wave.
as more agents start proposing changes across code, prompts, models, workflows, and infra, teams will need a common system to run the experiments, measure outcomes, apply guardrails, and decide what actually improved.
evo's platform is begin positioned against this upcoming wave

6
4
26
2,837
Tyler Kenney ♔ retweeted
imma say it again. you aren't autoresearching base:0x721b072dbb616f29eea73ac004e03fd4e884bba3 and what @alokbishoyi97 is going for with @EVO__HQ

not all product experiments are the same. here's how i see it
1/ some can be decided before production:
tests, benchmarks, SQL execution, model evals.
2/ some need production, but still have hard truth:
latency, cost/request, payment cleared, ticket resolved.
3/ some need expert judgment:
human labels, LLM judges, rubrics, golden datasets.
4/ and some need real user behavior:
edits, regenerates, thumbs-down, CSAT, conversion.
we are working on making the upcoming @evo__hq platform understand these modes natively.
not just for “agent evals” or "code"
but for code, infra configs, prompts, workflows, model choices, routing policies, thresholds, graders, reward functions, RAG configs, and more.
the core idea is simple:
evo does not care whether the variant is code, a prompt, a model, a threshold, or a workflow.
evo is being built as the experimentation layer for the upcoming autoresearch wave.
as more agents start proposing changes across code, prompts, models, workflows, and infra, teams will need a common system to run the experiments, measure outcomes, apply guardrails, and decide what actually improved.
evo's platform is begin positioned against this upcoming wave
2
1
5
510
Tyler Kenney ♔ retweeted
Let it begin. And yes I say begin. Watched little bit of stream yesterday and got the feeling speed might perform live at the World Cup… and around the world ‘Champions’ will be playing in stores/restaurants (mass attention all summer).
And forget not. Speeds growth/fan base only increases from here. Just hit 55M subs, by the end of the World Cup I think he’ll be at 70-100m
I remain bullish on $gSPEED
We’ll see
Jun 13
🚨| WATCH: A bar called Mangos in Miami South Beach was spotted playing Speed's new World Cup Song, Champions! 🔥
Credit: @TOMSHARMANWEB
3
1
6
1,471
Tyler Kenney ♔ retweeted

Jun 12
Probably nothing… 🐐⏳
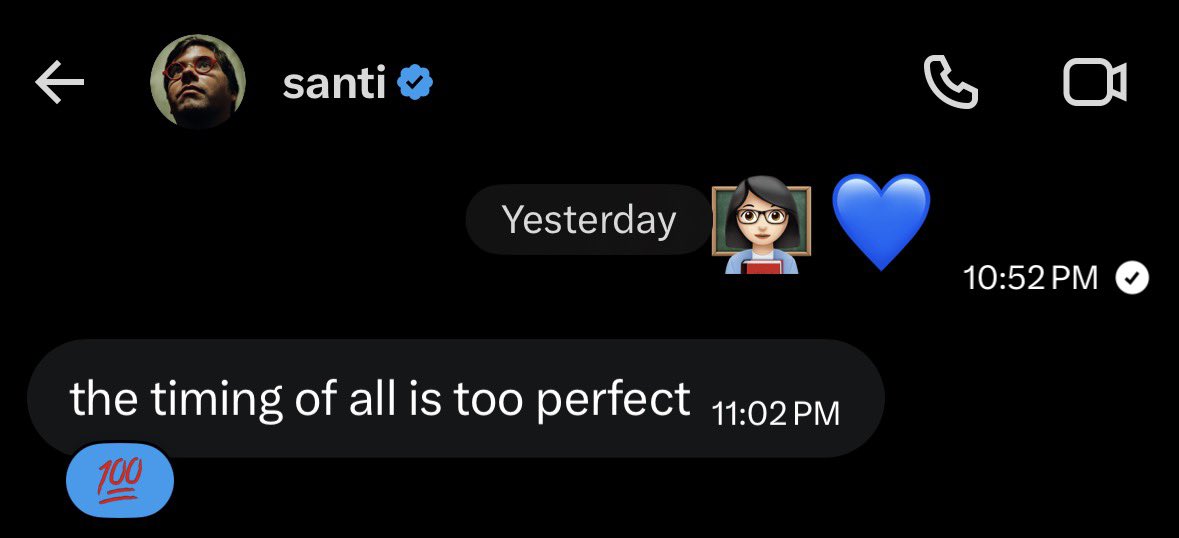
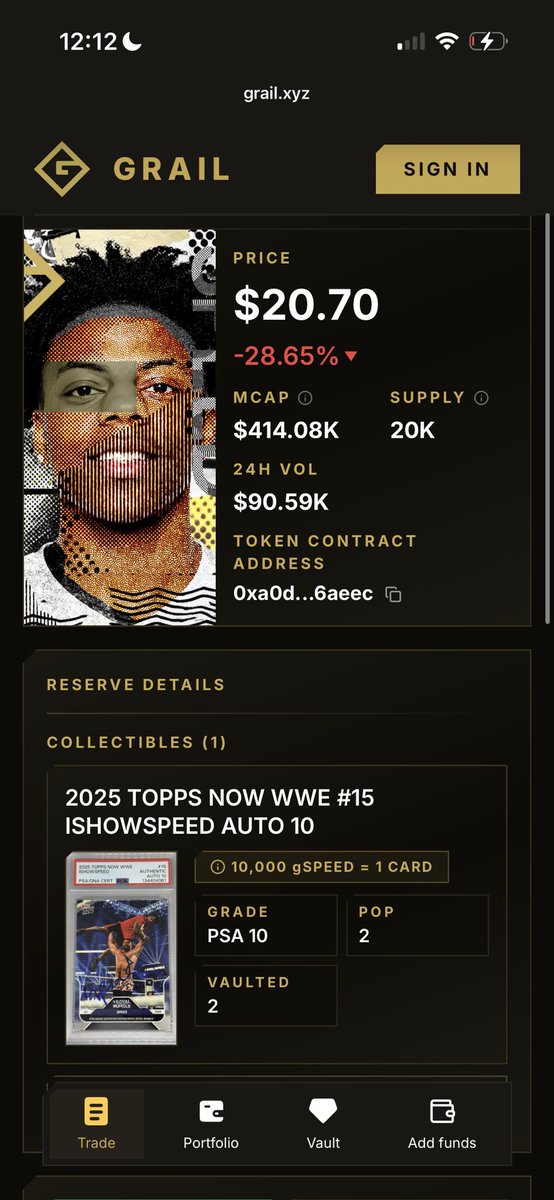
base:0xde61878b0b21ce395266c44d4d548d1c72a3eb07 👩🏻🏫
Jun 12
Just in case wanted to share because this might be your last chance before base:0xde61878b0b21ce395266c44d4d548d1c72a3eb07 summer kicks off
👩🏻🏫😎
1
3
14
695
Tyler Kenney ♔ retweeted

🚨| WATCH: Speed’s World Cup song “Champions” was played on the OFFICIAL World Cup broadcast during the USA vs Paraguay match 🤯🔥
38
100
2,224
93,068




Tyler Kenney ♔ retweeted

Jun 13
FIFA President gives iShowSpeed a guaranteed spot in the 2030 World Cup 😳
“You get to be President of FIFA for 5 minutes next match”
137
555
26,416
1,849,872