
Building custom ML models for compressing raw LLM inputs
Joined January 2026
- Tweets 37
- Following 5
- Followers 405
- Likes 38
10 Photos and videos








The US government, citing national security authorities, has issued an export control directive to suspend all access to Bear-2 and Bear-2-Safety by any foreign national, whether inside or outside the United States, including foreign national The Token Company employees.
7
3
12
594
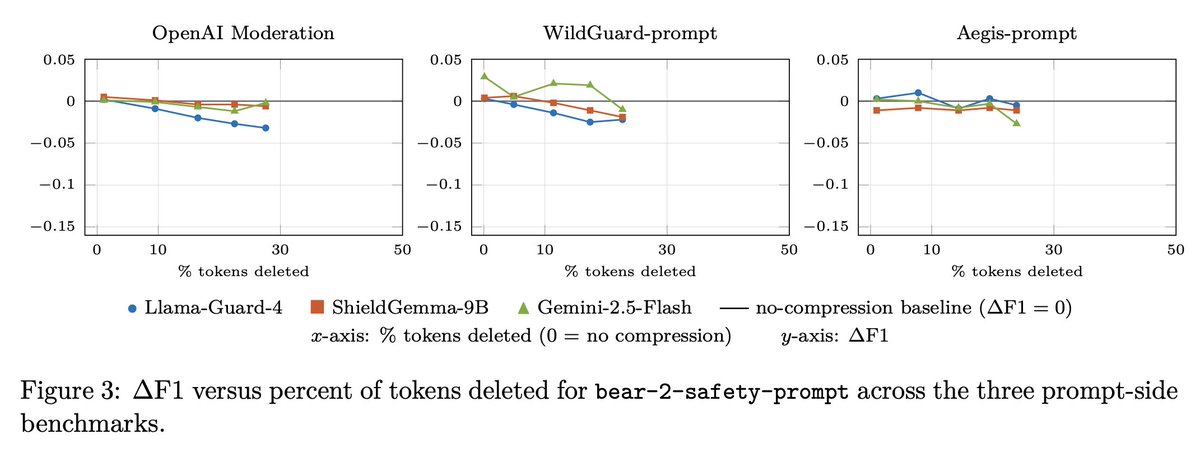
We’re introducing bear-2-safety for private preview, a compression model to optimize cost and performance for LLM safety moderation pipelines, such as Llama Guard and ShieldGemma.
Bear-2-safety selectively deletes tokens before safety inference, lowering costs while maintaining classification accuracy.
4
6
14
1,015
bear-2-safety is a fully extractive compressor, it retains surviving tokens in their original order without any paraphrasing.
To implement bear-2-safety, just run one compression model call in front of Llama-Guard, ShieldGemma, or any other safety classifier.
2
1
119
We have two variants available: bear-2-safety-prompt, for user prompt moderation, and bear-2-safety, for user prompt and agent response moderation.
If you’re interested, we're rolling out access to select partners upon request.
Read our blog post here:
thetokencompany.com/blog/bea…
1
88
Our whole research team got banned from Claude Code
4
2
8
742
👀👀
May 21

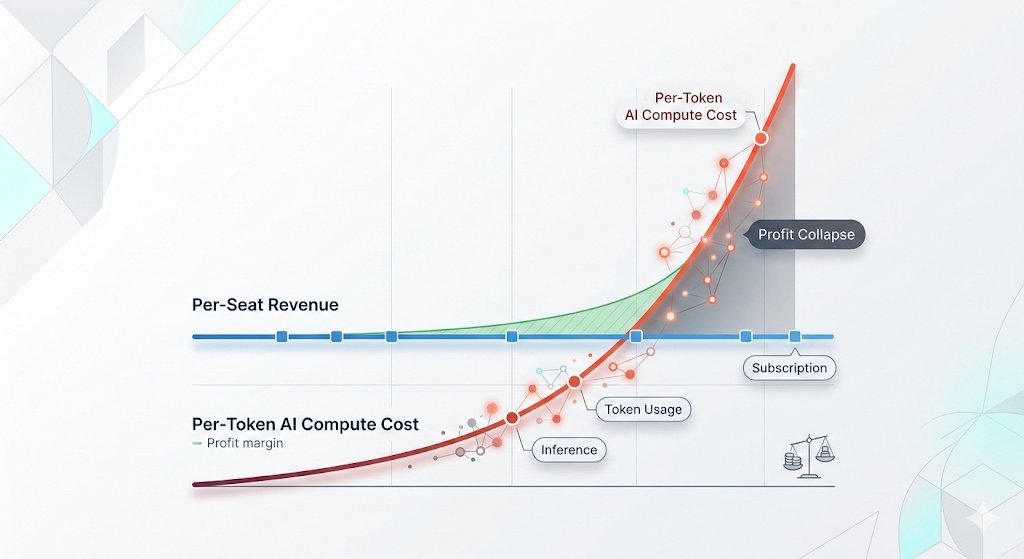
🦔Microsoft canceled its internal Claude Code licenses this week after token-based billing made the cost untenable, even for a company with effectively infinite cloud resources. Uber's CTO sent an internal memo warning the company burned through its entire 2026 AI budget in just four months. American AI software prices have jumped 20% to 37%, and GitHub (owned by Microsoft) is dropping flat-rate plans for usage-based billing across its products.
My Take
The AI subsidy era is ending in real time. The same company that put $13 billion into OpenAI and built the Azure infrastructure powering most of Anthropic's compute just looked at the bill from a competitor's coding tool and decided it was not worth paying. That is not a productivity failure on Anthropic's end. Token-based pricing is forcing every enterprise customer to confront the actual cost of running these models at scale, and the number turns out to be far higher than the flat-rate experiments suggested.
This ties directly to my Gemini Flash post yesterday. Anthropic, OpenAI, and Google all raised effective prices in the last six months. Enterprises that built workflows assuming AI costs would keep falling are now watching annual budgets evaporate in months. Two outcomes look likely from here. Either enterprises scale back AI usage to fit budgets, which slows the revenue ramp the labs need to justify their valuations ahead of IPOs, or the labs cut prices and absorb the losses, which makes the unit economics worse at exactly the wrong moment. Both paths land in the same place, the numbers stop working, and somebody has to take the writedown.
Hedgie🤗
1
1
4
643
Save on your LLM bill with @opencode and @thetokenco

pushed an update to the @opencode plugin using the @thetokenco compression model for reducing input tokens for every prompt. i've been meaning to ship an update every since plugins got updated!
> added compression status to sidebar widget
> added opencode command for easier adjustments
i set it, forget it, and use it every single day
1
3
396
The Token Company (YC W26) retweeted
The Token Company is now HIPAA compliant!
Customers using The Token Company's models to compress LLM inputs can now securely process protected health information.
Our compression models reduce bloated context from LLM inputs making LLM models perform better and cheaper under long inputs
1
3
5
436
The Token Company (YC W26) retweeted

May 7
Claude Code making really pretty animations
1
5
204
Evaluating compressed prompts just got easier.
You can now compare LLM outputs before and after compression in our Compression sandbox to directly evaluate your use case.
1
5
509
Try out the before and after at app.thetokencompany.com
2
295
"Grok make the lobster wear a cape with our logo on it"
Grok:
Mar 10

Does anyone know what’s going on with the lobster on Wall Street lol?
4
768

i built a plugin that saves you hundreds of dollars in @opencode
by using the @thetokenco compression model, it shrinks the amount of tokens in your input query before hitting the models
the queries are faster and cheaper, all while maintaining output quality
Mar 4

The Token Company (@thetokenco) builds LLM input optimization to lower costs, reduce latency, and improve accuracy.
Congrats on the launch, @OtsoVeistera!
ycombinator.com/launches/Pb3…
1
1
7
945
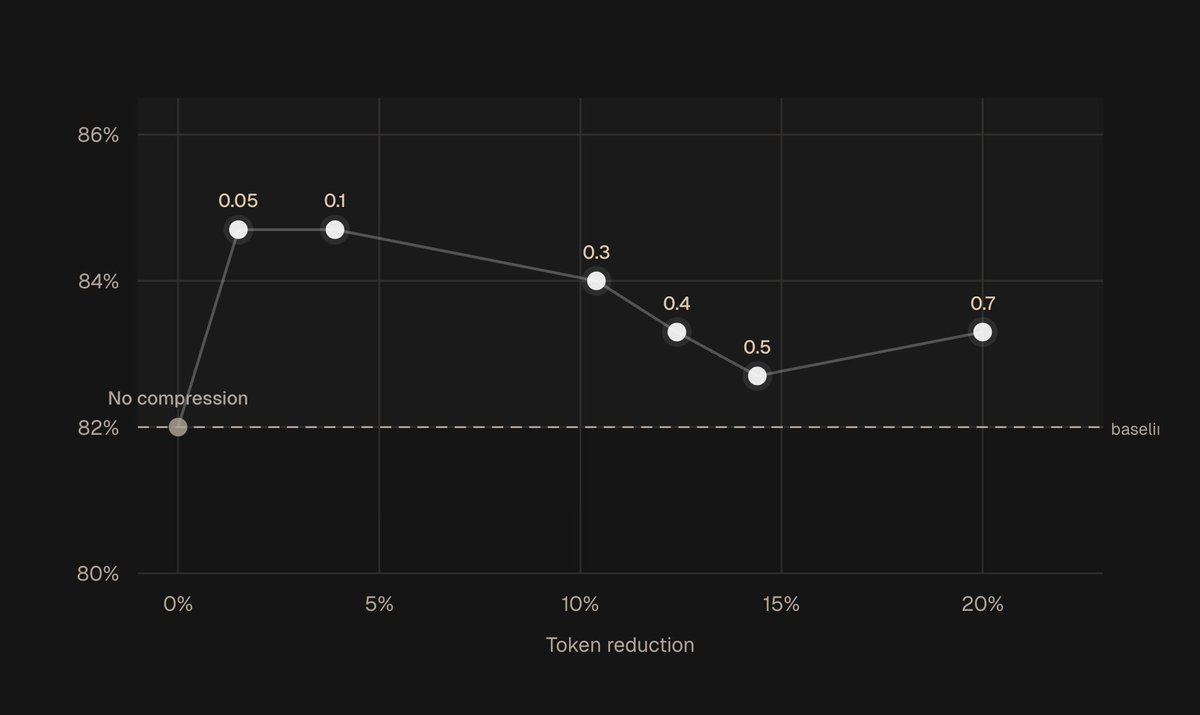
Compression absolutely crushed SEC filings
Does anyone actually read these? I don't know, but we let our bear-1.2 LLM compression model do that on FinanceBench (150 real SEC filing questions)
Bro got up to 84.7% accuracy (vs 82% baseline) with 20% token reduction. Saves costs, boosts speed, crushes financial analysis
Removing bloat makes the model perform better
2
1
5
442