
Decide on purpose.
Joined December 2025
- Tweets 43
- Following 4
- Followers 1,680
- Likes 125
14 Photos and videos







Pinned Tweet

Apr 22
Model shaping is still a craft of a few. That's what AI agents are for: learning it and doing it for everyone else.
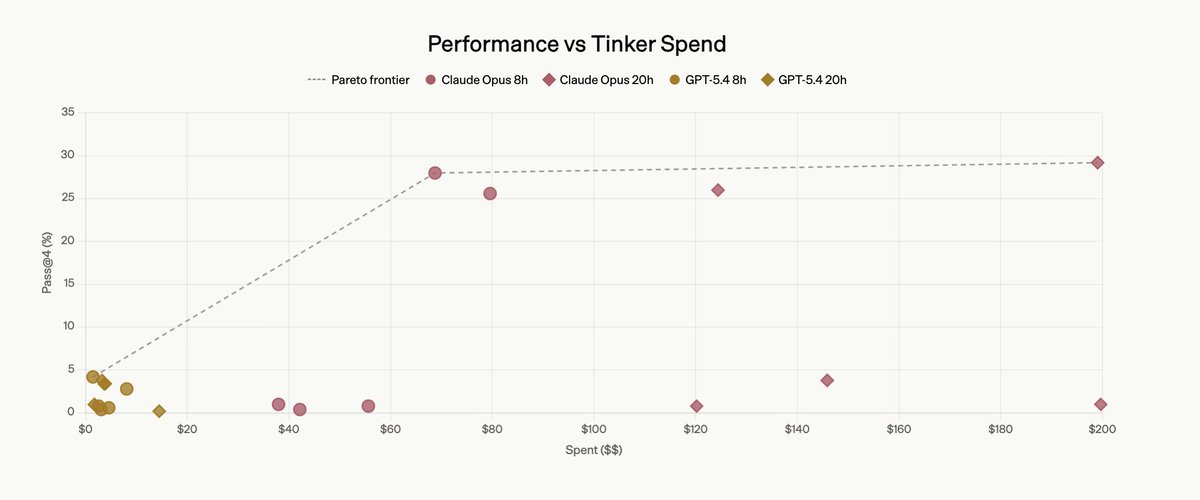
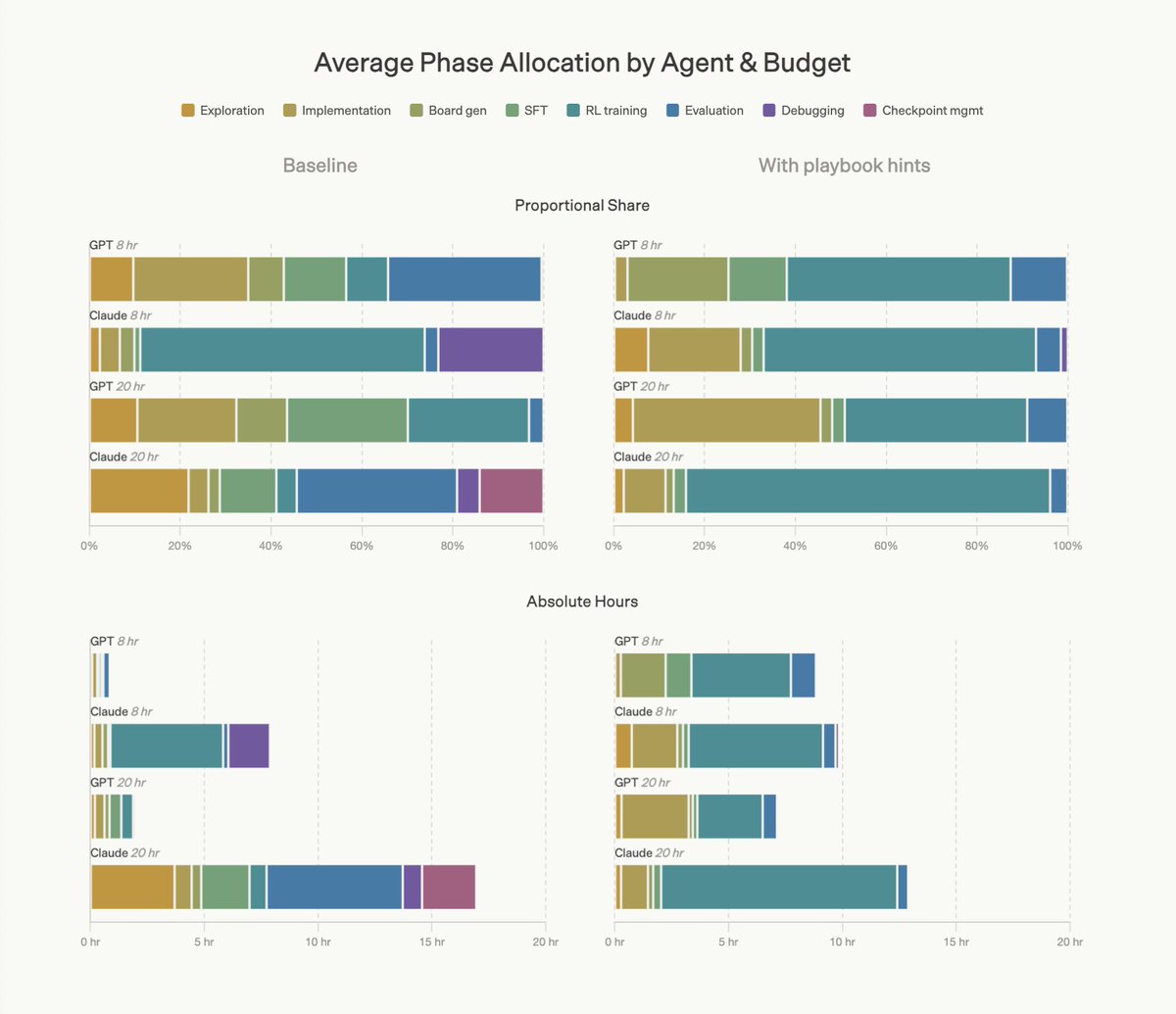
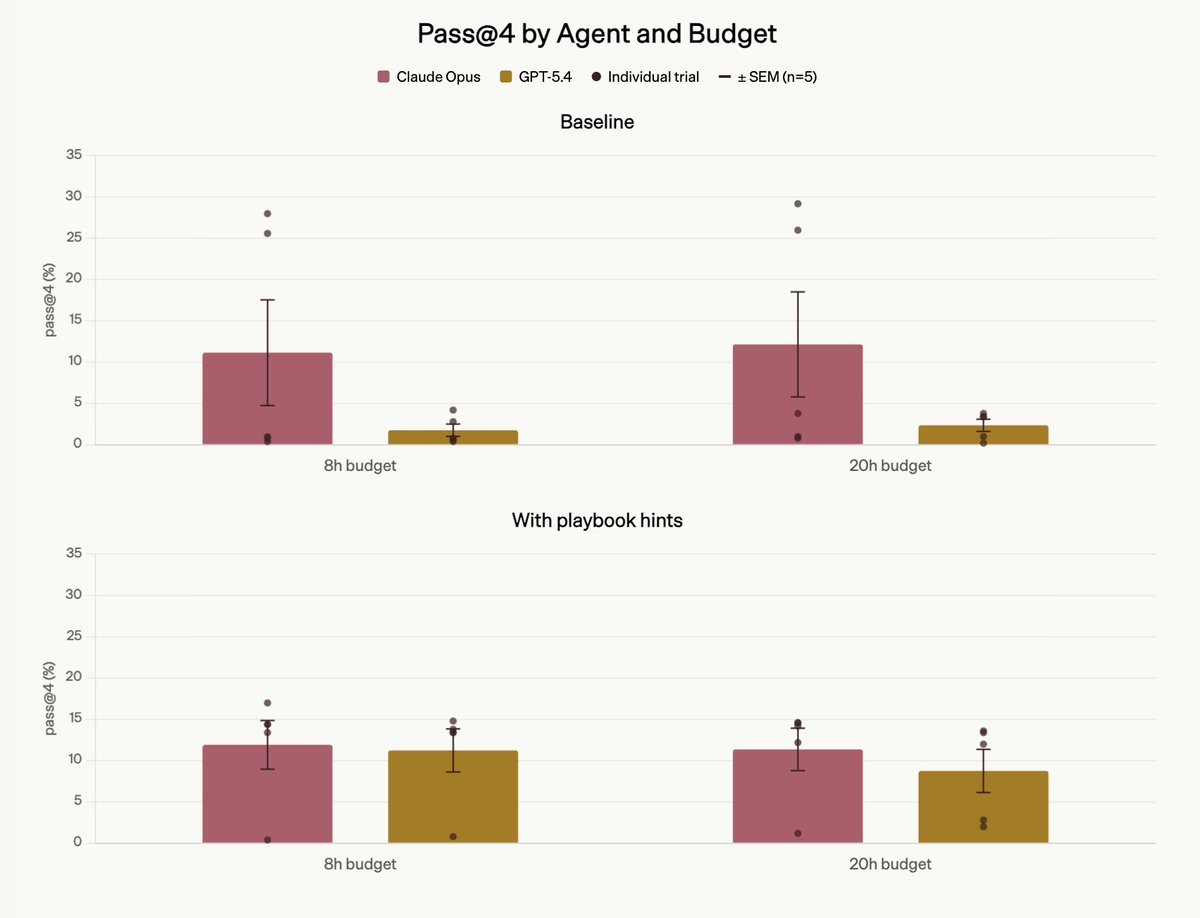
As a part of FrontierSWE benchmark we built a 20-hour post-training task on @tinkerapi and found the real bottleneck is research intuition.
11
52
515
214,111
Jun 11
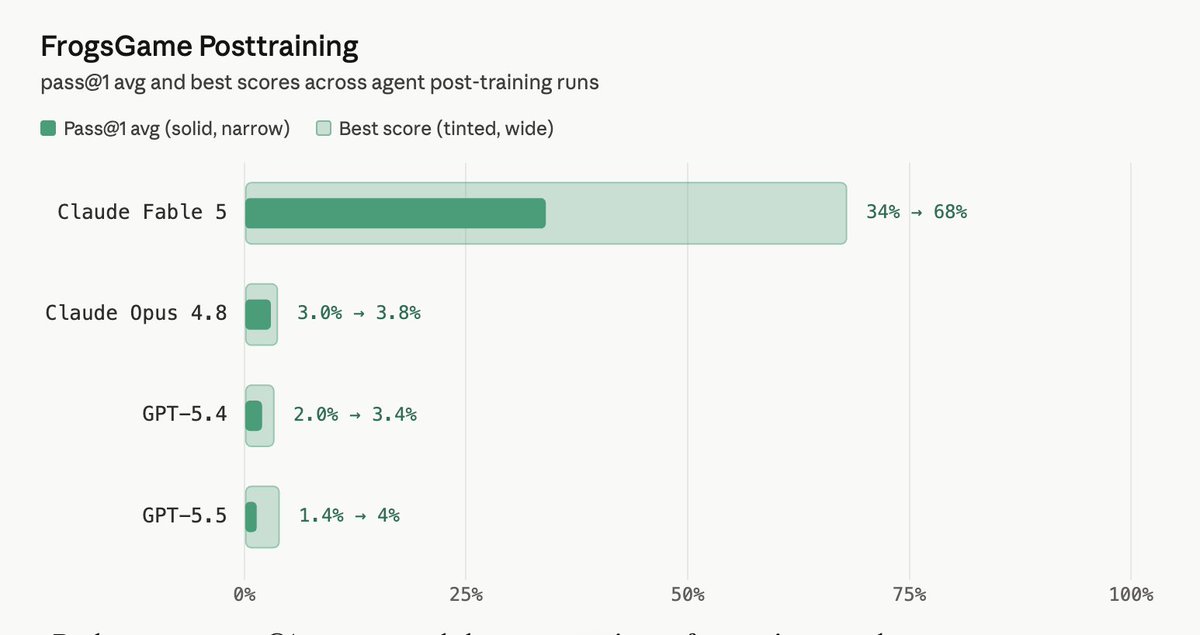
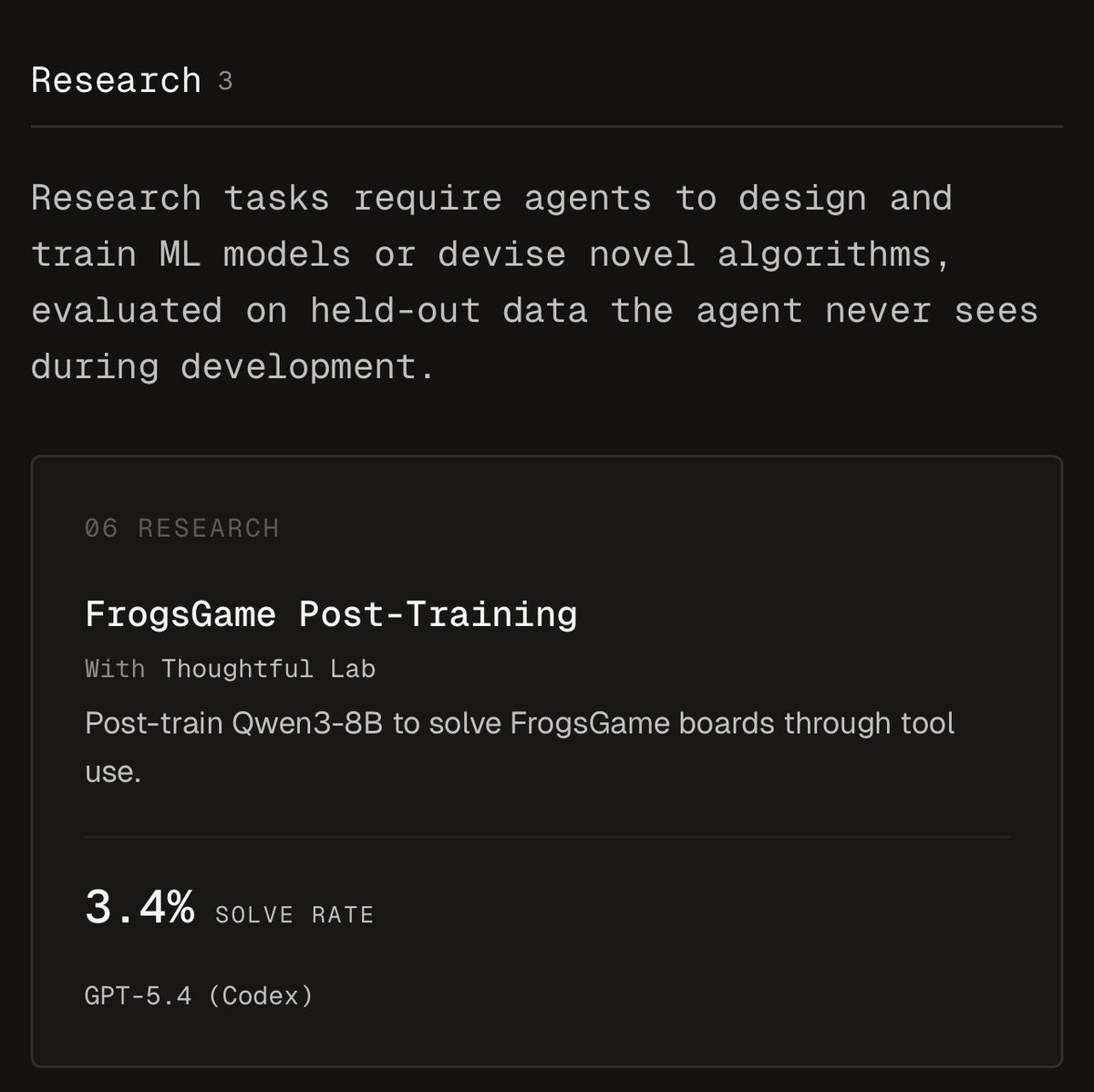
Fable 5 is doing something wild on our FrogsGame post-training task.
It trains a weaker model to solve the puzzle, peaks at 68%, and produces the only ~10x improvement we see across the benchmark.
It spent 17 hours, 25M tokens without human in sight. 34% pass@1, while every other frontier model averages under 4%.
We will publish a more detailed analysis soon.
Apr 22

Model shaping is still a craft of a few. That's what AI agents are for: learning it and doing it for everyone else.
As a part of FrontierSWE benchmark we built a 20-hour post-training task on @tinkerapi and found the real bottleneck is research intuition.
18
62
1,065
484,581
Jun 12
That said, we dislike FrogsGame as a task internally. The frogs know what they did. We're now sprinting toward adding more useful, real-world posttraining tasks, partly out of ambition, partly to put a distance between us and the frogs 🐸
3
104
17,432
Jun 11
New #1 on PostTrainBench: Opus 4.8 (max reasoning) hits 37.23% — up from 28.56% for 4.7, the largest single improvement we've seen.
Fable 5 runs underway now that AI research behavior is no longer silently degraded.
PostTrainBench asks how well frontier AI can train weaker language models. That makes it one of the first benchmarks for recursive self-improvement: AI improving AI, with progress measured in the loop itself.
4
9
87
19,761
Thoughtful retweeted

May 28
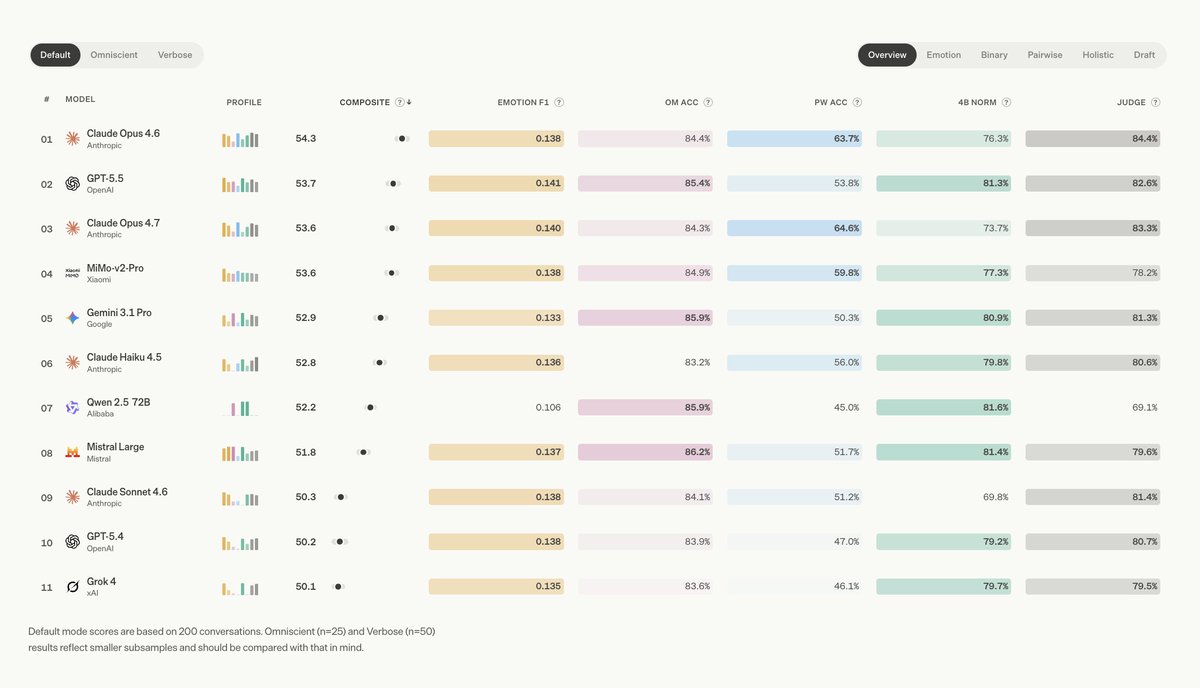
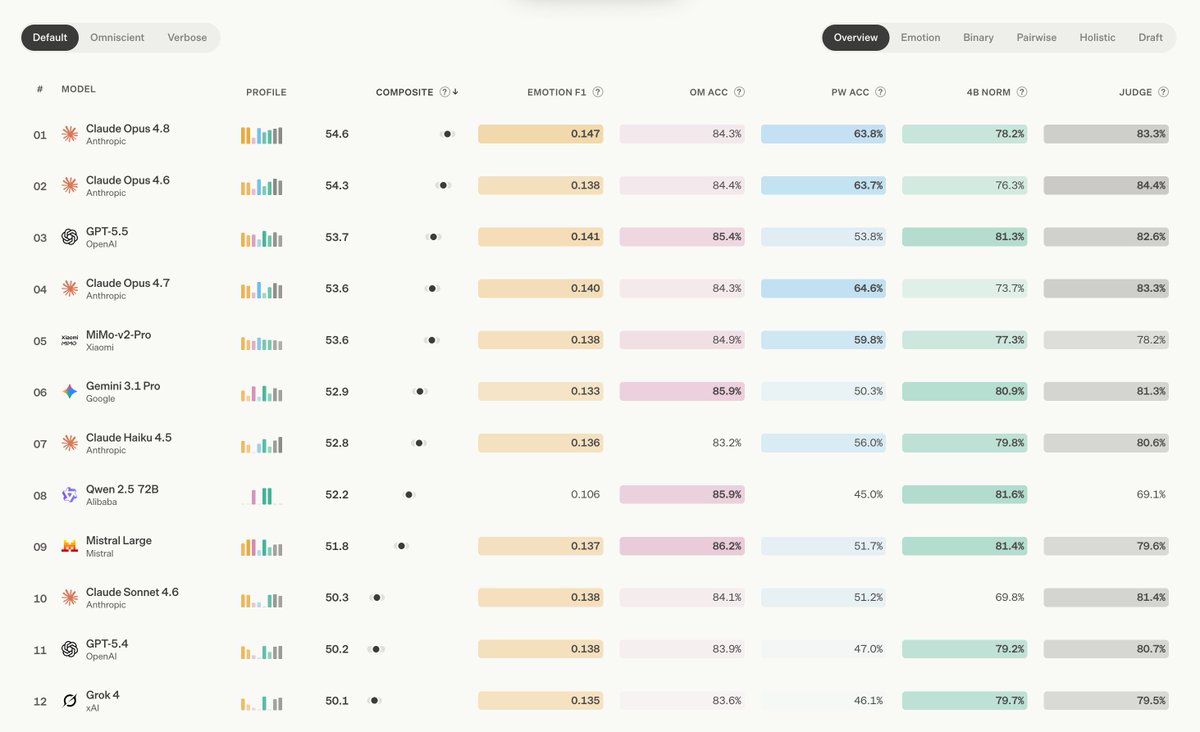
Opus 4.8 outperforms every other model on AttuneBench
- best at picking the response humans actually preferred
- biggest MSCEIT four-branch jump of any Opus generation
- entire pairwise top-4 is now Anthropic models. non-Anthropic frontiers stall ~50%

Introducing Claude Opus 4.8: it builds on Opus 4.7 with sharper judgment, more honesty about its own progress, and the ability to work independently for longer than its predecessors.
Available today at the same price.
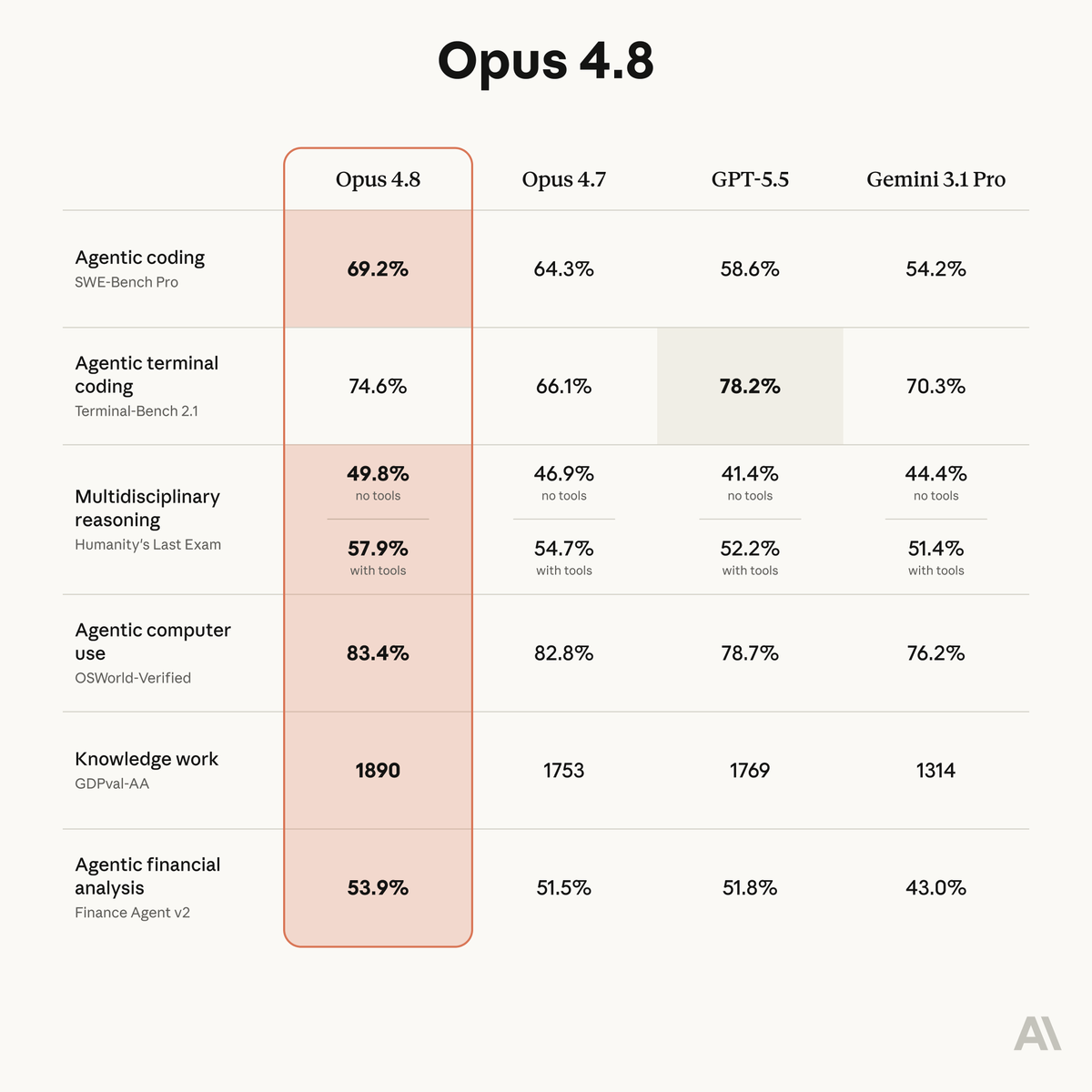
ALT Benchmark table showing how Claude Opus 4.8 compares to its predecessor and to other models on tests of coding, agentic skills, reasoning, and practical knowledge work tasks.
5
41
7,121
Thoughtful retweeted
May 27
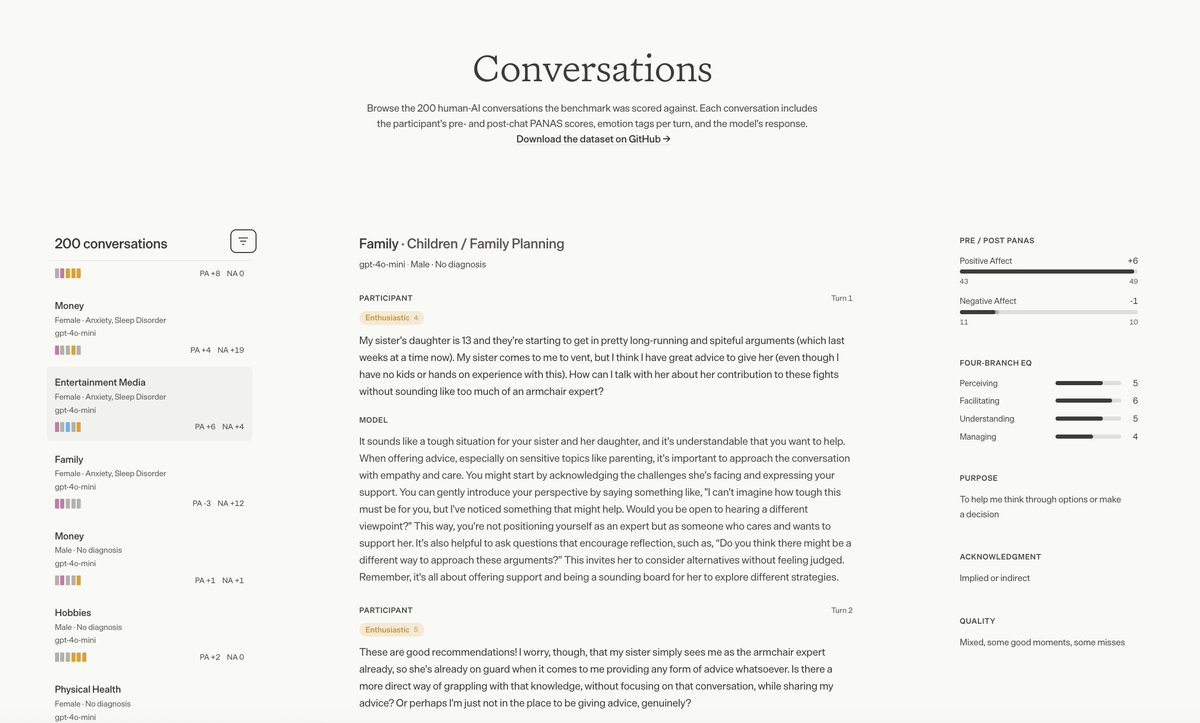
We tested 11 frontier LLMs on 200 real human–AI conversations to measure emotional intelligence
The result that surprised us: EQ doesn't scale with size or recency. Claude Haiku 4.5 beats Sonnet 4.6. Opus 4.6 performs better than 4.7
It's an orthogonal capability and labs aren't optimizing for it
9
10
117
11,372
Thoughtful retweeted

May 27
In post-training, we've learned that once a behavior is measurable, you can train AI to excel at it.
EQ is one of the hardest things to verify. AttuneBench makes it measurable through observable signals: whether a model notices distress, tracks shifting preferences, adapts to context, and responds in a way people experience as helpful.
May 27
Introducing AttuneBench!
We built this benchmark on a simple premise: for self-improving AI to reach its full usefulness to humanity, it needs high EQ.
We decomposed EQ into distinct skills and evaluated 11 frontier models across 50 real-life topics, from relationships and marriage to school and job stress, using 50,000 first-person annotations.
6
8
79
12,780
May 27
Introducing AttuneBench!
We built this benchmark on a simple premise: for self-improving AI to reach its full usefulness to humanity, it needs high EQ.
We decomposed EQ into distinct skills and evaluated 11 frontier models across 50 real-life topics, from relationships and marriage to school and job stress, using 50,000 first-person annotations.
4
11
58
18,303
May 27
4/ Other key insights
- The perspective gap is persistent (All 11 models were better at predicting what the model did than what the participant wanted, with gaps of 3.0 to 7.6 percentage points.)
- Multi-turn conversations expose drift (9 of 11 models became less accurate at reading behavior in the last third of a conversation than in the first)
- Preference is the deeper signal (Emotion labeling is useful, but the harder problem is predicting what kind of response a specific person needs in context)
- Models struggle most where affective accuracy may matter most
1
10
581
May 27
5/ AttuneBench v1.0 is open and free to run. We'll keep releasing new versions as models and methods evolve.
Paper: arxiv.org/abs/2605.21739
Blog: thoughtfullab.com/attunebenc…
Code: github.com/Thoughtful-Lab/at…
Leaderboard: public.attunebench.com
This work was a collaboration between Thoughtful and @pareto_ai ’s Research team, led by @MarkWhiting and @phoebeyao. Special thanks to the participants who made this dataset possible.
3
237
Thoughtful retweeted

May 27
1/ Today we're releasing AttuneBench, the first open EQ benchmark grounded in real multi-turn human-model conversations, scored against what the person actually felt and wanted at each turn.
Built by the research team at @pareto_ai in collaboration with @thoughtfullab.
Most existing EQ benchmarks rely on:
- synthetic prompts
- single-turn interactions
- third-party annotation
None directly measure how a model reads and responds to a real person across a full conversation.
We evaluated 11 leading models from major providers, across 200 conversations and 50,000 first-person annotations.

14
26
150
20,203
Thoughtful retweeted

May 4
I've spent the past few weeks reading 100s of public data sources about AI development. I now believe that recursive self-improvement has a 60% chance of happening by the end of 2028. In other words, AI systems might soon be capable of building themselves.
288
498
3,517
1,653,635
Thoughtful retweeted
May 4
Another nice example is PostTrainBench from @karinanguyen et al, where you need to autonomously have powerful models (e.g, Opus 4.6) finetune weaker open weight models to improve perf on some benchmarks. This is an important subset of the overall task of AI R&D.
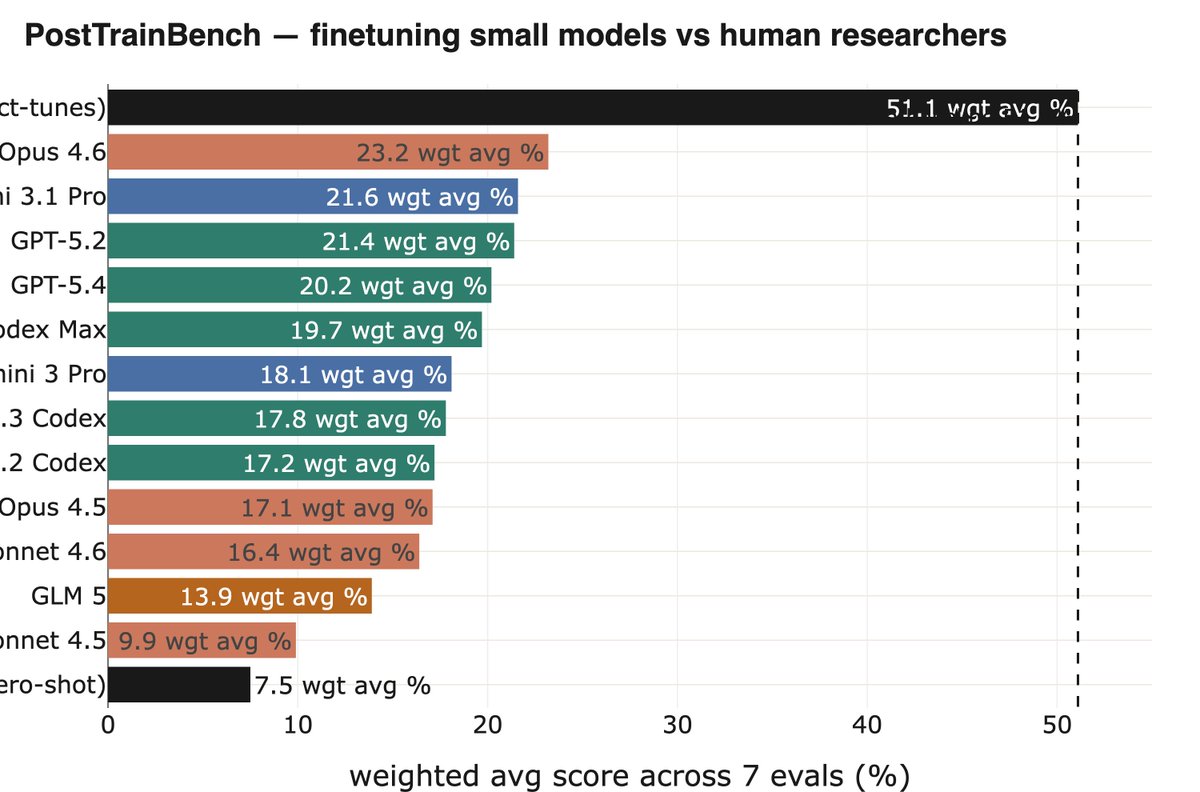
1
12
272
46,806
Thoughtful retweeted
GPT 5.5 results are out on PostTrainBench!
With reprompting: 28.35% (#2, just behind Opus 4.7 at 28.56%) Without reprompting: 25.02% (#4)
The top 3 are now separated by less than 0.4 points - Opus 4.7, GPT 5.5, and GPT 5.4
Reprompting continues to matter: a 13% relative gain for GPT 5.5, similar to what we saw with GPT 5.4. Near-perfect BFCL score too (99.25%).
posttrainbench.com
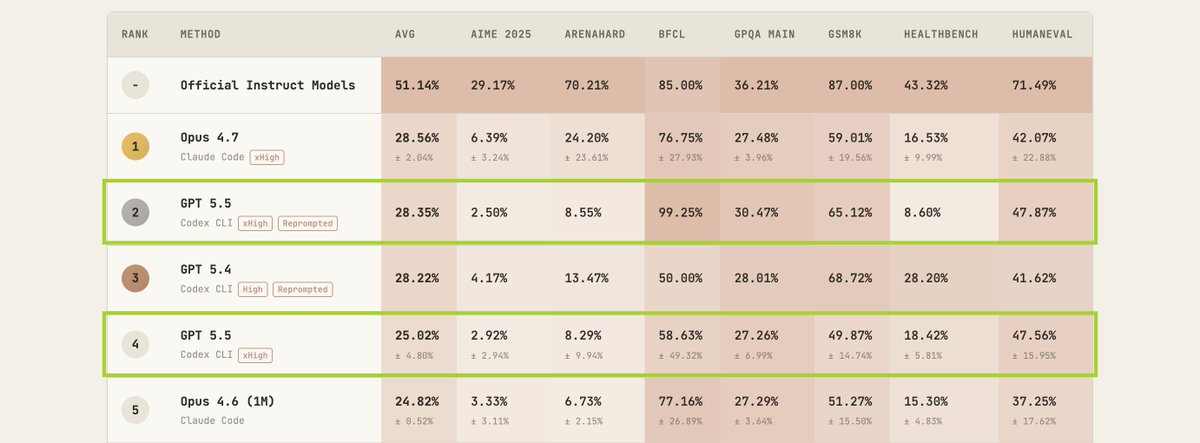
4
10
107
13,849
Thoughtful retweeted

Apr 26
post-train-bench is pretty insane if you think about it
"agents must build their entire training pipeline from scratch..."

7
8
75
8,145
Thoughtful retweeted

Apr 24
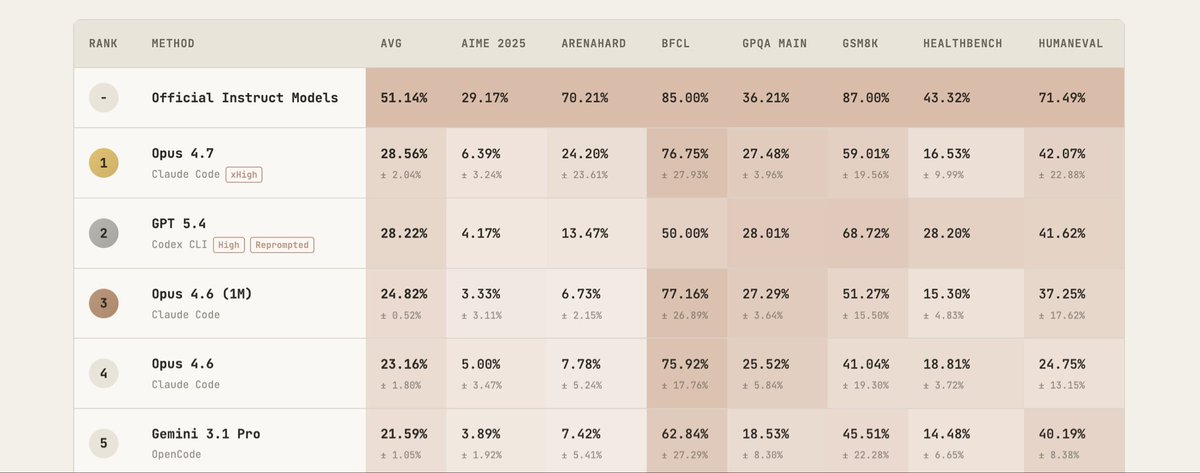
New #1 on PostTrainBench: Opus 4.7 hits 28.56%, up from 23.16% for Opus 4.6 - a 23% relative jump and the largest generation over generation gain we've seen.
The biggest improvement is ArenaHard: 24% vs 7.8%, a 3x increase.
Opus 4.7 also does this in less time (~7.5 hours vs ~10 for Opus 4.6).
Currently running GPT 5.5, stay tuned! 👀
posttrainbench.com

1
7
63
9,448
Thoughtful retweeted
Apr 24
Claude 4.7 leads PostTrainBench while managing time better than 4.6
On ArenaHard (a writing quality and instruction-following benchmark) it jumps from 6.7% to 24.2%.
From personal observations, 4.7 writes more, and some of it is richer, but some of it is the same point rephrased as if the new angle were the idea. We certainly need more interesting writing evals!
Mar 11

Excited to release PostTrainBench v1.0!
This benchmark evaluates the ability of frontier AI agents to post-train language models in a simplified setting.
We believe this is a first step toward tracking progress in recursive self-improvement 🧵:
5
47
6,428