
7 Photos and videos
Thinh Truong retweeted

12 Nov 2025
i hate ML conference reviewers. i take back everything bad i ever said about ACL. every ACL reviewer i ever got was at least literate
14
18
470
35,994
Thinh Truong retweeted

30 Jun 2025
Are AI scientists already better than human researchers?
We recruited 43 PhD students to spend 3 months executing research ideas proposed by an LLM agent vs human experts.
Main finding: LLM ideas result in worse projects than human ideas.

12
182
633
152,887

24 Jun 2024
also got interrogated at melbourne airport after 30 hrs on the plane. This sucks so much 🙃.
5
235
Thinh Truong retweeted

23 Apr 2024
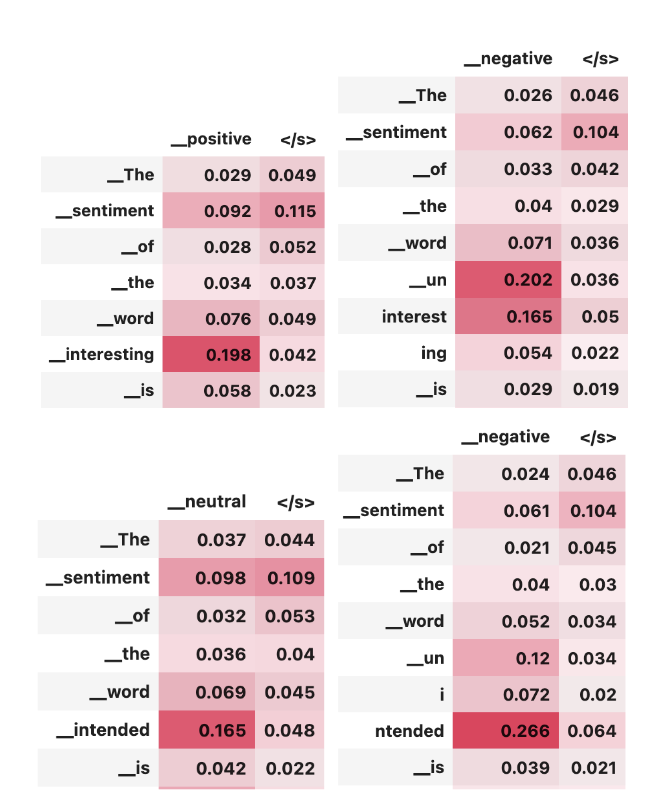
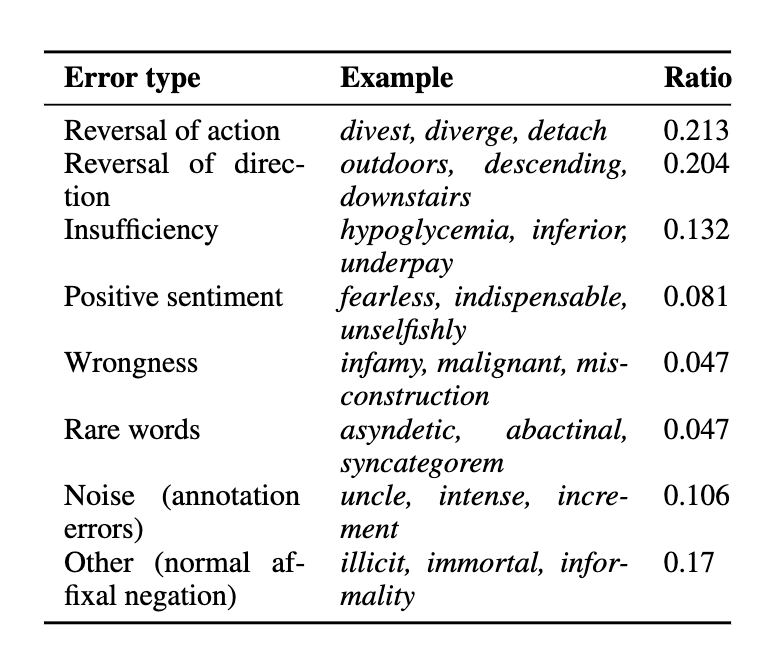
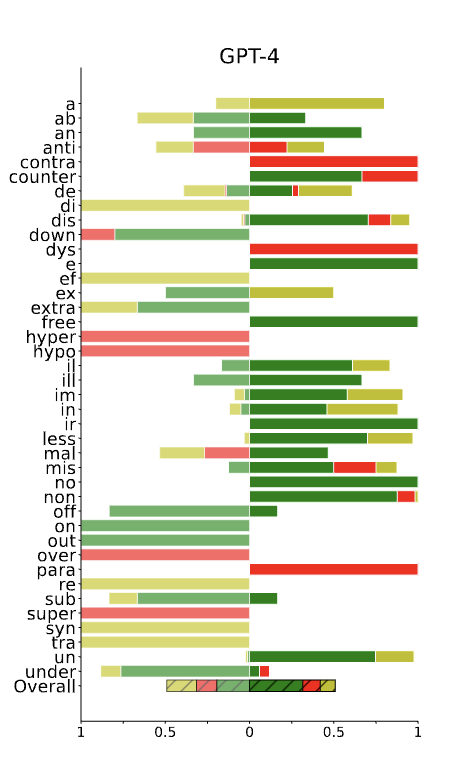
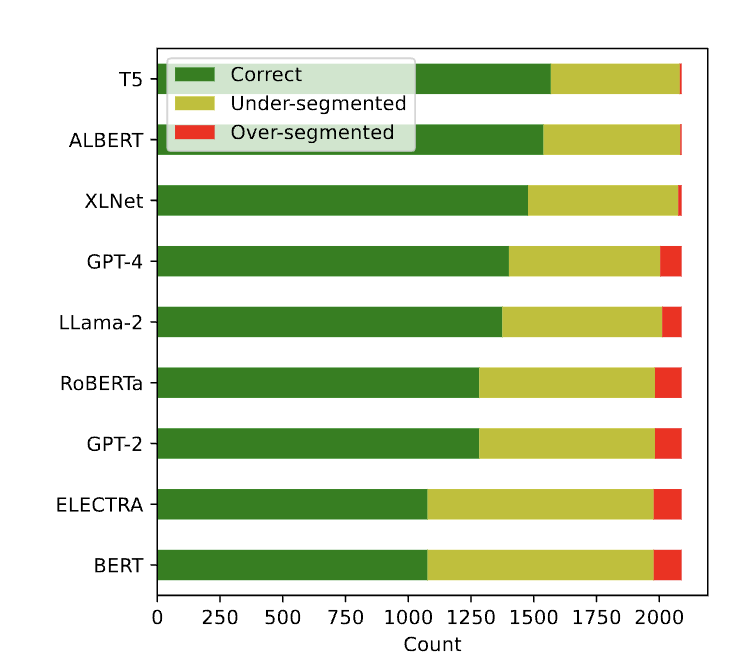
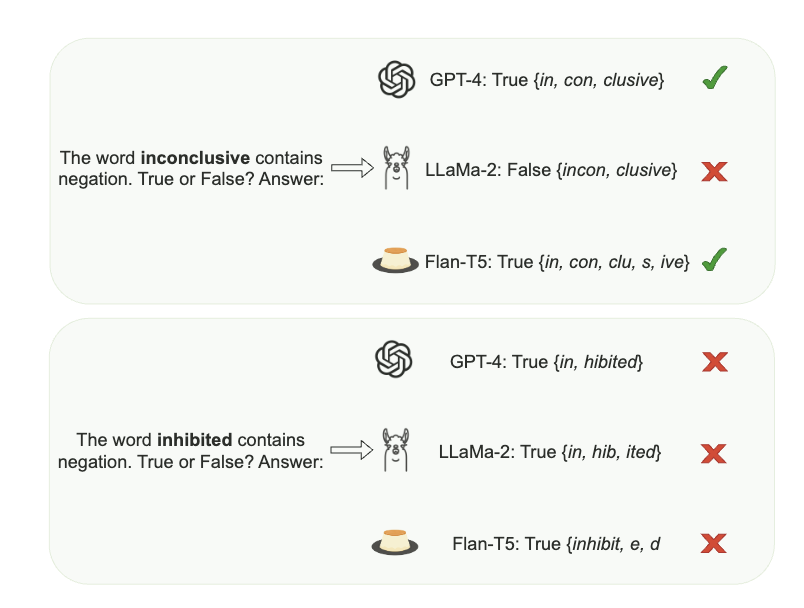
🚨 New paper on Subword Tokenization 🚨
- umLabeller, a new tool, classifies subword tokenization into morph 🤹 or alien 👽
- alien tokenization 🛸 leads to poorer generalizations than morphological tokenization for 3 downstream tasks. arxiv.org/abs/2404.13292 (1/7)

3
16
52
8,826
16 Apr 2024
0-shot evaluation is important (if not more meaningful) when evaluating general capabilities of LLM.
15 Apr 2024

"In other words, the modification are so simple that there is a rule to determine the label (e.g., adding 'X allegedly did Y' doe not entail 'X did Y'). "
And yet the massively pretrained models do not capture this! I find it interesting and remarkable.
1
74
5 Apr 2024
Paper accepted to NAACL 2024 main conference.
arxiv: arxiv.org/abs/2404.02421
In this work, we explore the interaction between two bottlenecks of LLMs: negation and tokenization (quoting @karpathy: "tokenization is the root of suffering").
3
4
9
1,301
5 Apr 2024
10/ We see that models could clearly understand negation despite incorrect tokenization. This could be an interesting phenomenon to look at when discovering LLM interpretability. Also, as English is poor in morphology, we are eager to extend this analysis to other languages.
1
78
5 Apr 2024
11/ Please have a look at the paper if you find this interesting.
Big thanks to my co-author and supervisors: @YuliaOtmakhova, @karinv, Trevor, @eltimster. Finally, I will be at NAACL (my first in-person conference after almost finishing my PhD). See you in Mexico!
2
84
20 Jan 2017
recently picked up learning guitar and became obsessed with it x_x
1
31 Dec 2016
okay 2017 solutions:
_ do well at school
_ get an internship
_ get fit