
7 Photos and videos







May 26
Graduated! Very grateful for my advisors, Mike Jordan and Ryan Tibshirani, who set the Pareto frontier for brilliance and kindness 🧠🩷
Next stop: MIT for a postdoc with @stats_stephen!

11
6
167
17,436
Apr 23
Come say hi at my @iclr_conf poster (Friday 10:30am, Pavilion 3 #316) to chat about prediction sets or why @PlantNetProject is my favorite plant identification app!
10 Jul 2025

New paper: Conformal prediction for long-tailed classification🐒
arxiv.org/abs/2507.06867
🧑🌾 (plant enthusiast): Help me identify plants!
🤖 (existing conformal algs): Do you want sets that never include rare plants or sets that contain 100s of labels?
🧑🌾: Uhh… neither? A🧵(1/n)
1
2
15
1,891
9 Dec 2025
My collaborator Joseph Salmon made a beautiful blog post about our paper, featuring an *interactive* recreation of a figure from Sadinle, Lei & Wasserman's iconic 2019 conformal prediction paper. Go check it out!
Blog post: josephsalmon.eu/blog/long-ta…
10 Jul 2025
New paper: Conformal prediction for long-tailed classification🐒
arxiv.org/abs/2507.06867
🧑🌾 (plant enthusiast): Help me identify plants!
🤖 (existing conformal algs): Do you want sets that never include rare plants or sets that contain 100s of labels?
🧑🌾: Uhh… neither? A🧵(1/n)
1
12
1,577
10 Jul 2025
New paper: Conformal prediction for long-tailed classification🐒
arxiv.org/abs/2507.06867
🧑🌾 (plant enthusiast): Help me identify plants!
🤖 (existing conformal algs): Do you want sets that never include rare plants or sets that contain 100s of labels?
🧑🌾: Uhh… neither? A🧵(1/n)
2
8
49
10,927
10 Jul 2025
All of these tools lead to strong empirical performance on PlantNet and iNaturalist. Check out the looooong tail; this is a tough setting! Some classes are left with 0 holdout examples for calibration (4/n)
1
5
565
10 Jul 2025
This is joint work with Jean-Baptiste Fermanian & Joseph Salmon and inspired by discussions with the rest of the @PlantNetProject team (p.s. Check out their awesome plant identification app if you haven’t yet!🌱) (n/n)
1
6
582
Tiffany Ding retweeted

13 Feb 2025
📯 New work! Conformal Prediction Sets with Improved Conditional Coverage using Trust Scores.
arxiv.org/abs/2501.10139
How useful are prediction sets that achieve 90% marginal coverage by failing on 10% cases that are challenging? Not very useful for clinicians who require uncertainty estimates for critical cases in diagnosis!
Can we improve coverage where it matters most? 🧵 (1/n)
2
17
69
13,447
Tiffany Ding retweeted

9 Aug 2024
📣Announcing the 2024 NeurIPS Workshop on Statistical Frontiers in LLMs and Foundation Models 📣
Submissions open now, deadline September 15th
sites.google.com/berkeley.ed…
If your work intersects with statistics and black-box models, please submit! This includes:
✅ Bias
✅ Benchmarking
✅ Automatic evaluation
✅ Watermarking
✅ Conformal prediction and black-box uncertainty quantification
✅ Privacy and data rights
✅ Auditing
We’re looking forward to seeing your submissions!
Co-organizers: @stats_stephen @alexdamour @tatsu_hashimoto @JessicaHullman @FannyYangETH !
Program Committee: Chance Johnstone @DrewPrinster @huiwensun_ Eleni Straitouri @MargauxZaffran
Provisional speakers include: @MihaelaVDS @bschoelkopf Virginia Smith and @weijie444 , up to scheduling considerations :)

ALT A blackboard with text "Workshop on Statistical Frontiers in LLMs and Foundation Models at NeurIPS 2024 in Vancouver, British Columbia, Canada. Statistics as a tool for evaluating, auditing, and deploying black-box models and LLMs."


2
33
122
31,161
24 Apr 2024
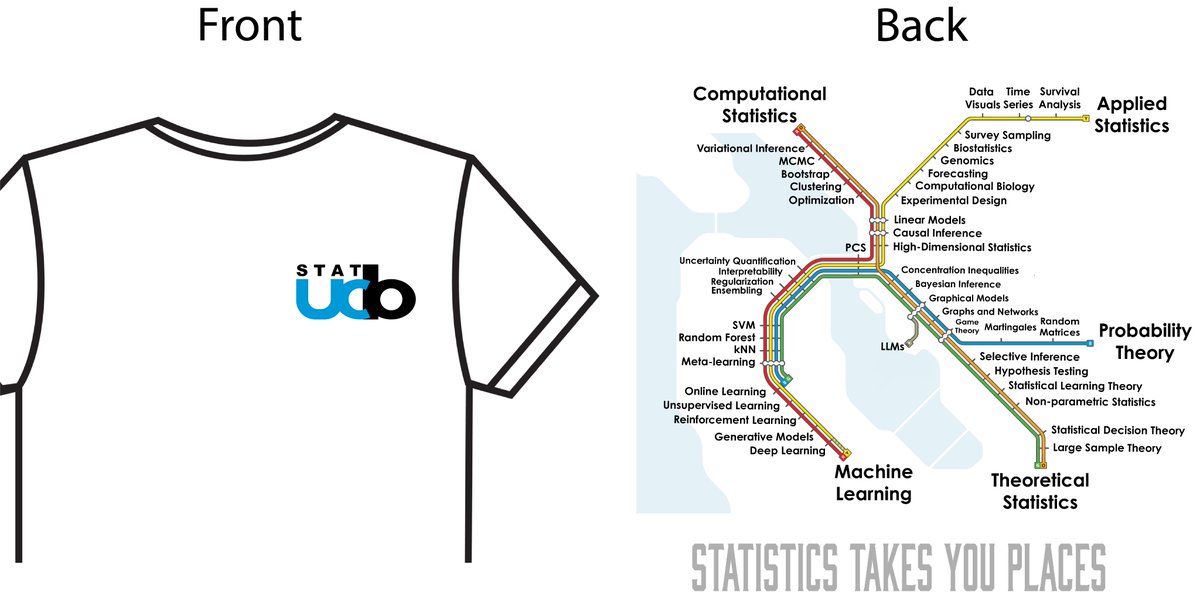
The greatest accomplishment of my statistics career has been winning this year’s @UCBStatistics T-shirt design competition with a @SFBART-inspired shirt designed w/ @aashen12!
{stats nerds} ∩ {public transit nerds} ≠ ∅ 📉🚅
4
8
73
7,432
24 Apr 2024
Sorry in advance if we missed topics! We tried to be as comprehensive as possible given the space constraints
4
751
13 Dec 2023
Interested in uncertainty quantification and how to make conformal prediction sets more practically useful? Come to our poster at #NeurIPS23!
📍Poster #1623
🕙 Thursday 10:45-12:45
w/ @ml_angelopoulos, @stats_stephen, Michael I. Jordan & Ryan Tibshirani
arxiv.org/abs/2306.09335
2
14
104
15,179
19 Jun 2023
📢New paper! Class-conditional conformal prediction with many classes
arxiv.org/abs/2306.09335
👩⚕️ (doctor): “Give me uncertainty on the patient diagnosis.”
🤖(conformal): “The 95% prediction set is {normal}.”
👨🏻(patient): ☠️
How do you avoid this negative outcome? A 🧵(1/4)
1
20
91
16,072
19 Jun 2023
A naive strategy is to split the data classwise and run conformal once per class.
But with many classes/limited data, this gives bad results (big sets, etc.)
In clustered conformal prediction, we cluster classes that have similar score distributions and pool their data! (3/4)
1
6
1,037
19 Jun 2023
This is joint work with @ml_angelopoulos, @stats_stephen, Michael I. Jordan, and Ryan J. Tibshirani.
Please reach out if you’re interested in chatting about conformal prediction or statistics in general! (4/4)
1
1
9
1,618