
Jean-Loup Baer Professor @UWCSE seeking to better understand and empower people through data and computation. Recruiting PhD students and Postdocs
Joined January 2012
- Tweets 1,592
- Following 1,799
- Followers 5,070
- Likes 3,996
122 Photos and videos










Pinned Tweet

15 Aug 2025
I’m excited to share our new @Nature paper 📝, which provides strong evidence that the walkability of our built environment matters a great deal to our physical activity and health.
Details in thread.🧵
nature.com/articles/s41586-0…
65
696
3,398
367,824
Tim Althoff retweeted

May 28
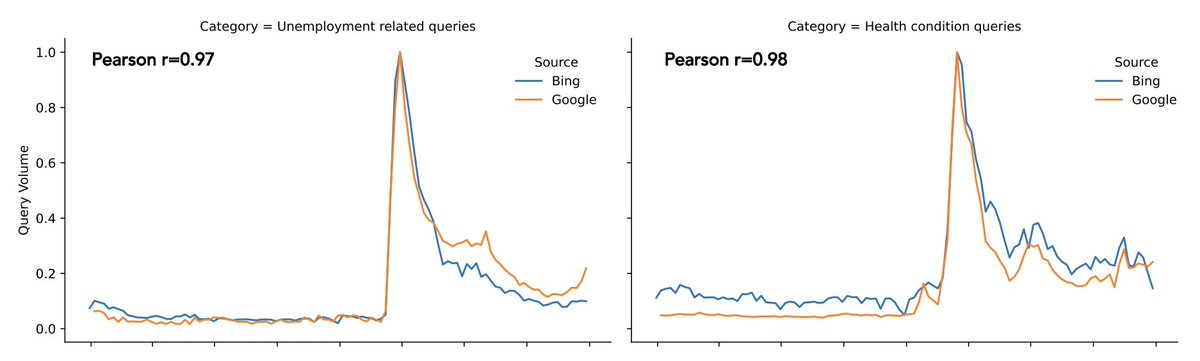
Sense of community is the "glue" that holds online communities together! But what factors affect sense of community online? Come to my talk @icwsm tomorrow morning at 8:30 to learn more! 🧵
1
4
10
1,112
Tim Althoff retweeted

May 18
MoEs are everywhere, but the design space is confusing: total vs active experts? expert size? shared experts? routing? token dropping?
We train >2000 MoE LMs 🫠 to investigate and bring you:
📄🔪🍰 Slicing and Dicing MoEs
Tl;dr: it's all about expert size and count
[1/9]

15
56
377
36,566

📢 New Paper 📢 Self-Improving VLM Judges Without Human Annotations
Reward models & judges are critical for evaluating output quality and alignment with human preferences for VLM training.
Current training approaches typically rely on:
💸 Costly human preference annotations
🔒 Distillation from large closed-source models GPT/Claude (which also use human labels)
😤 Labels that may become obsolete as models advance
We show you can skip all of this with self-generated synthetic data! ✨👀

2
20
78
6,614
24 Nov 2025
We're still accepting postdoc applications starting as early as January'26. Focus areas include psychosocial AI simulation and safety, Human-AI collaboration.
Details: docs.google.com/document/d/1…
3
31
103
14,916
Tim Althoff retweeted

5 Nov 2025
Large Language Models (LLMs) are increasingly used to simulate human users in interactive settings. However, they often drift from their assigned personas, contradict earlier statements, or abandon role-appropriate behavior. We introduce a framework for evaluating and improving persona consistency in LLM-generated dialogue with multi-turn RL, defining three automatic metrics and validating each against human annotations. More below 👇

3
9
76
22,037
31 Oct 2025
Our ability to meaningfully evaluate language models is critical, but challenged in many ways.
Check out @kenqgu's work that finally helps us disentangle "reasoning ability" from "parametric/world knowledge", while allowing for scalable, automated evaluation.

True intelligence = reasoning about new information, not memorized facts.
How can we scalably create benchmarks that are completely novel yet have known answers?
Meet SynthWorlds, an eval & data-gen framework to disentangle reasoning and knowledge⬇️🧵
📄arxiv.org/pdf/2510.24427
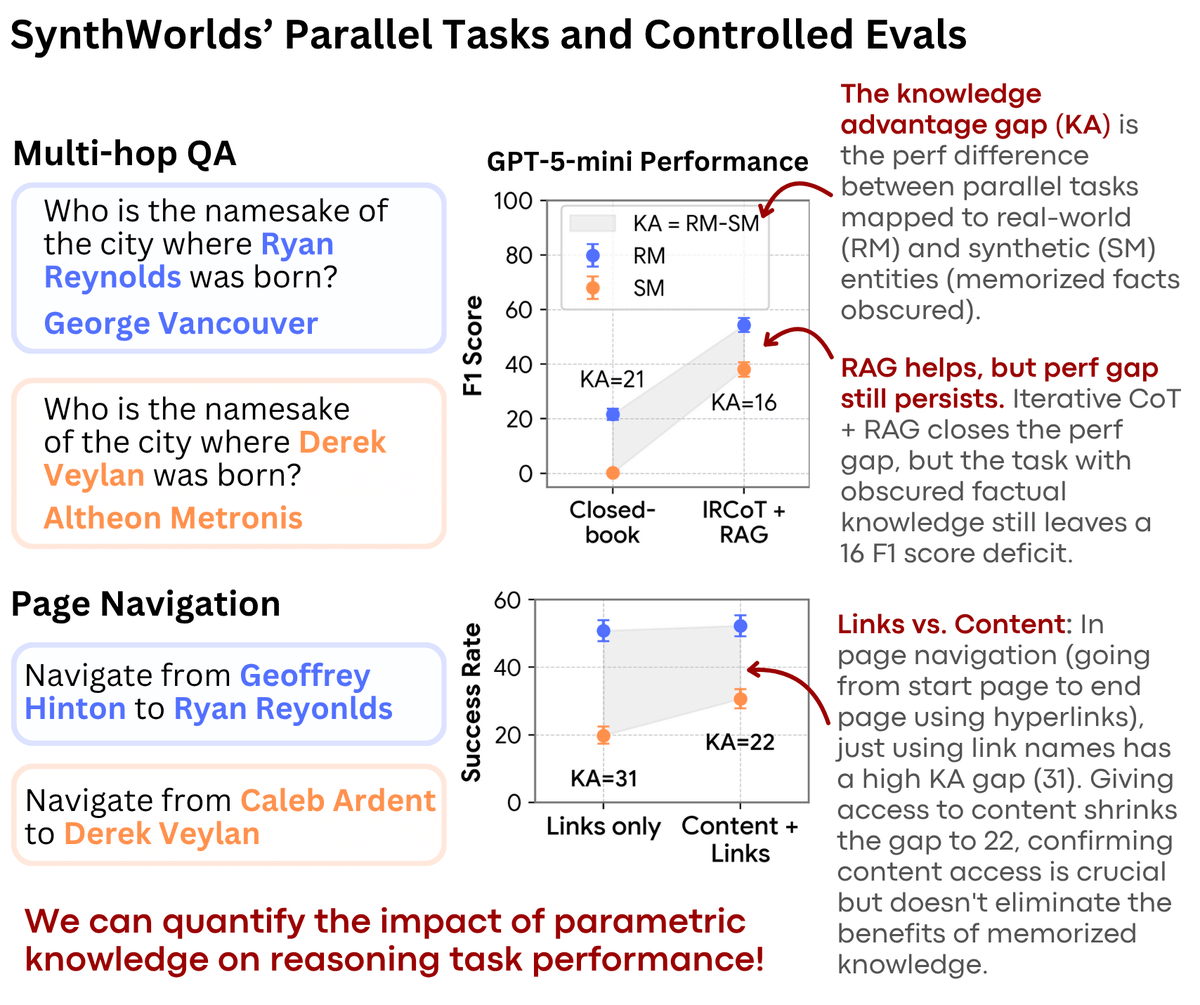
1
7
1,842

True intelligence = reasoning about new information, not memorized facts.
How can we scalably create benchmarks that are completely novel yet have known answers?
Meet SynthWorlds, an eval & data-gen framework to disentangle reasoning and knowledge⬇️🧵
📄arxiv.org/pdf/2510.24427
4
13
107
10,386
28 Oct 2025
(please reshare) I'm recruiting multiple PhD students and Postdocs @uwcse @uwnlp
(bdata.uw.edu). Focus areas incl. psychosocial AI simulation and safety, Human-AI collaboration.
PhD: cs.washington.edu/academics/…
Postdocs: docs.google.com/document/d/1…
7
111
400
36,434
Tim Althoff retweeted

21 Oct 2025
Need a lab? Moonshots abstracts due this Sat, Oct 25. We’re backing species-level swings in civic discourse, accelerating science, frontline healthcare, and workforce reskilling.
8× $250k seed grants now; then one or more $10M multi-year labs to continue the work.
Selection committee members include:
@timalthoff, @davidautor, @chris_bail, @erikbryn, @YejinChoinka, @fchollet, Mariano-Florentino (Tino) Cuéllar, @JeffDean, @ghadfield, @HannaHajishirzi, @bradenjhancock, John Hennessy, @erichorvitz, @JohnJumperSci, @tkalil2050, @zakkohane, @andykonwinski, @tommmitchell, @emollick, Dave Patterson (Chair), @PlevritisLab, @DG_Rand, @ChrisRytting, @YalaTweets, @Diyi_Yang, @james_y_zou
Apply: moonshots.laude.org/

3
12
1,101
Tim Althoff retweeted
19 Oct 2025
If you're at @ACM_CSCW 🇳🇴, come check out our 🏆honorable mention paper today on Reddit community governance (w/@amyxzh @timalthoff). 4pm in Dovregubben-2! More in thread... 🧵
1
2
7
4,506
Tim Althoff retweeted

8 Oct 2025
Calling all impact researchers who want to ship.
We're pumping $10Ms funding into AI research that improves society (via civic discourse, accelerating science, frontline healthcare, or workforce reskilling).
This is Laude Moonshots.
Humbled by the program committee we've assembled: @timalthoff, @davidautor, @chris_bail, @erikbryn, @YejinChoinka, @fchollet, Mariano-Florentino (Tino) Cuéllar, @JeffDean, @ghadfield, @HannaHajishirzi, @bradenjhancock, John Hennessy, @erichorvitz, @JohnJumperSci, @tkalil2050, @zakkohane, @andykonwinski, @tommmitchell, @emollick, Dave Patterson (Chair), @PlevritisLab, @DG_Rand, me, @Thom_Wolf, @YalaTweets, @Diyi_Yang, @james_y_zou.
8 Oct 2025

We’re counting down to our first round of Laude Moonshots. It’s energizing to see researchers mobilizing AI for urgent, real-world impact. Abstracts are due October 25. Details: moonshots.laude.org

1
2
16
3,676
Tim Althoff retweeted
11 Sep 2025
Some nice coverage of our paper (and award) from ICWSM back in June. Big congrats to Leon his successful first author paper, and big things to @timalthoff and @amyxzh for their support as always!
10 Sep 2025

Allen School researchers receive ICWSM Best Paper Award for analyzing how Reddit rules influence online community outcomes news.cs.washington.edu/2025/…
3
9
3,813
Tim Althoff retweeted

10 Sep 2025
Allen School researchers receive ICWSM Best Paper Award for analyzing how Reddit rules influence online community outcomes news.cs.washington.edu/2025/…
1
2
6,739

Congrats again to ugrad student Leon Leibmann and co-authors @galenweld and @timalthoff on best paper award (awarded to a single paper) at @icwsm this year!
10 Sep 2025
Allen School researchers receive ICWSM Best Paper Award for analyzing how Reddit rules influence online community outcomes news.cs.washington.edu/2025/…
1
4
2,179
Tim Althoff retweeted

ICYMI - our recent @Nature paper leverages a large dataset to show that a city's walkability influences our physical activity and health.
nature.com/articles/s41586-0…
15 Aug 2025

I’m excited to share our new @Nature paper 📝, which provides strong evidence that the walkability of our built environment matters a great deal to our physical activity and health.
Details in thread.🧵
nature.com/articles/s41586-0…
1
3
5
1,503
Tim Althoff retweeted

8 Sep 2025
Crunching away on a paper for #CHI2026 about online communities, moderation, or sociolinguistics?
You may be want to check out recent work led by @galenweld on predicting SOVC within subreddits based on the style and structure of conversations.
arxiv.org/abs/2508.08596
1
4
8
1,760

Do walkable cities prompt people to take more steps, or do people who want to walk tend to live in more pedestrian-friendly cities?
New research from @timalthoff @uwcse found that highly walkable areas lead to significantly more walking.
More: bit.ly/4lNxFKh

ALT Pedestrians walk along Seattle's waterfront
4
10
1,191
15 Aug 2025
I’m excited to share our new @Nature paper 📝, which provides strong evidence that the walkability of our built environment matters a great deal to our physical activity and health.
Details in thread.🧵
nature.com/articles/s41586-0…
65
696
3,398
367,824
15 Aug 2025
City planning is a powerful public health tool 🛠️. Investing in sidewalks, parks, and mixed-use zoning is a direct investment in citizens' health, making entire populations healthier. 💚
5
22
156
9,778
15 Aug 2025
Huge thanks to my amazing co-authors @iamborisi, Abby King, Jennifer Hicks, Scott Delp, and @jure (representing @uwcse @Stanford @StanfordDeptMed @StanfordNMBL @Nvidia) 🙏
5
1
64
5,681