
Joined October 2021
- Tweets 2,194
- Following 78
- Followers 309
- Likes 3,687
215 Photos and videos







Pinned Tweet

25 Oct 2024
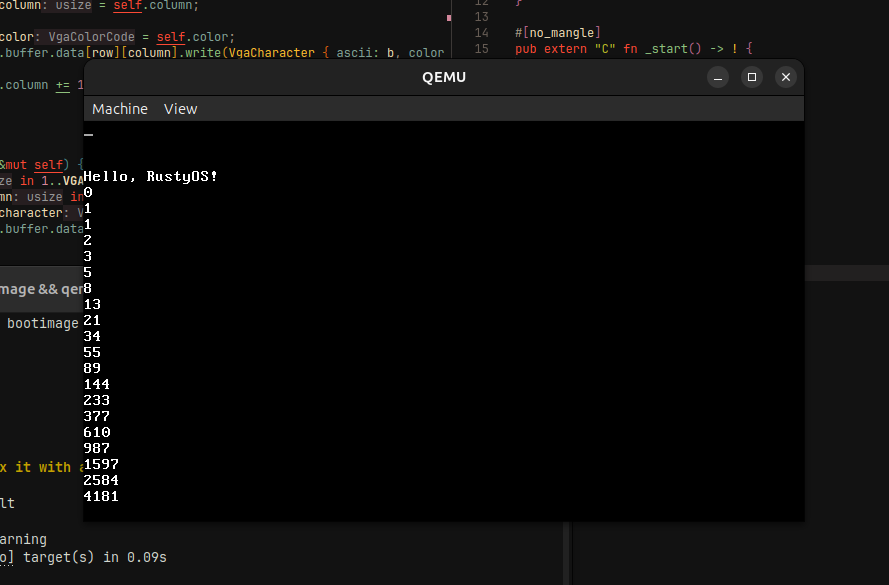
If you're stressed, burned out, and need to loosen up, consider building your own operating system. #rustlang
6
3
120
7,842
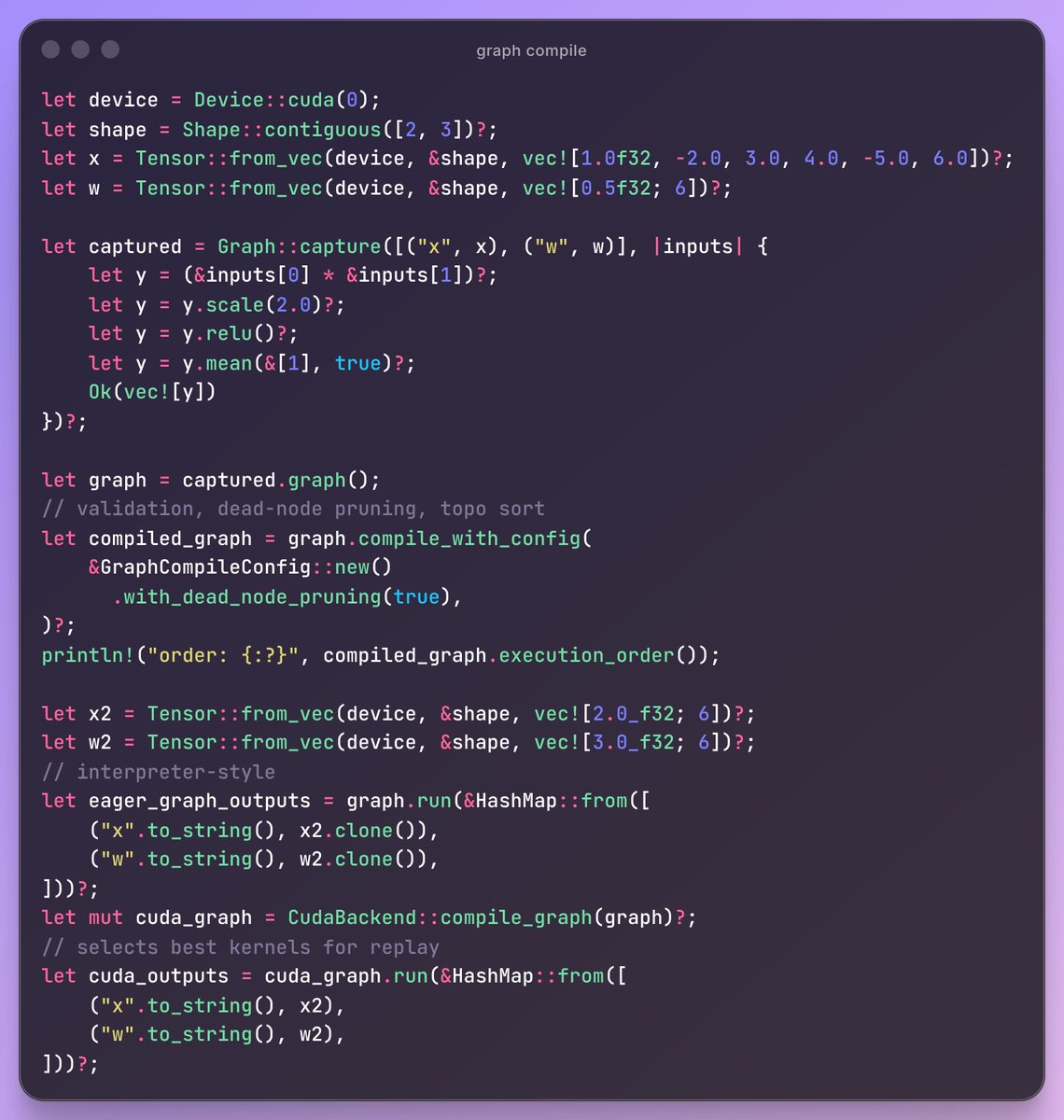
devlog; I have onnx models running in my ML framework, again. But now with graph capture not just eager execution. I'm trying to roughly model it after PyTorch. I'm doing something similar to TorchFX, doing symbolic tracing with fake tensors (using names instead of ids, no memory allocations, ...) to record ops.
Tensor ops execute eagerly, and are traced if run within `Graph::capture()` (I used to hide this by doing some wiring behind the scenes and use thread locals to store state). During capture, the ops record nodes into a graph. Tensors are aliased so recorded nodes refer to named tensors. When graphs run, they create "guards" which store metadata that is later used for checking inputs and outputs (names, data types, shapes, etc. kinda like in TorchDynamo). Optimization currently just involves pruning dead nodes, some validations and topological sort.
I have a custom CUDA allocator that can reuse blocks, which is useful if you know what and when to allocate ahead-of-time.
After that, it gets messy. There's a "compile" step that chooses "providers" (cuDNN, cuTENSOR, or custom kernels compiled with nvrtc) that graphs are executed with. These libraries require some annoying maintenance and aren't that straightforward to use. For the "TorchInductor" part I only have ideas not something that can run end-to-end yet.
12
Jun 10
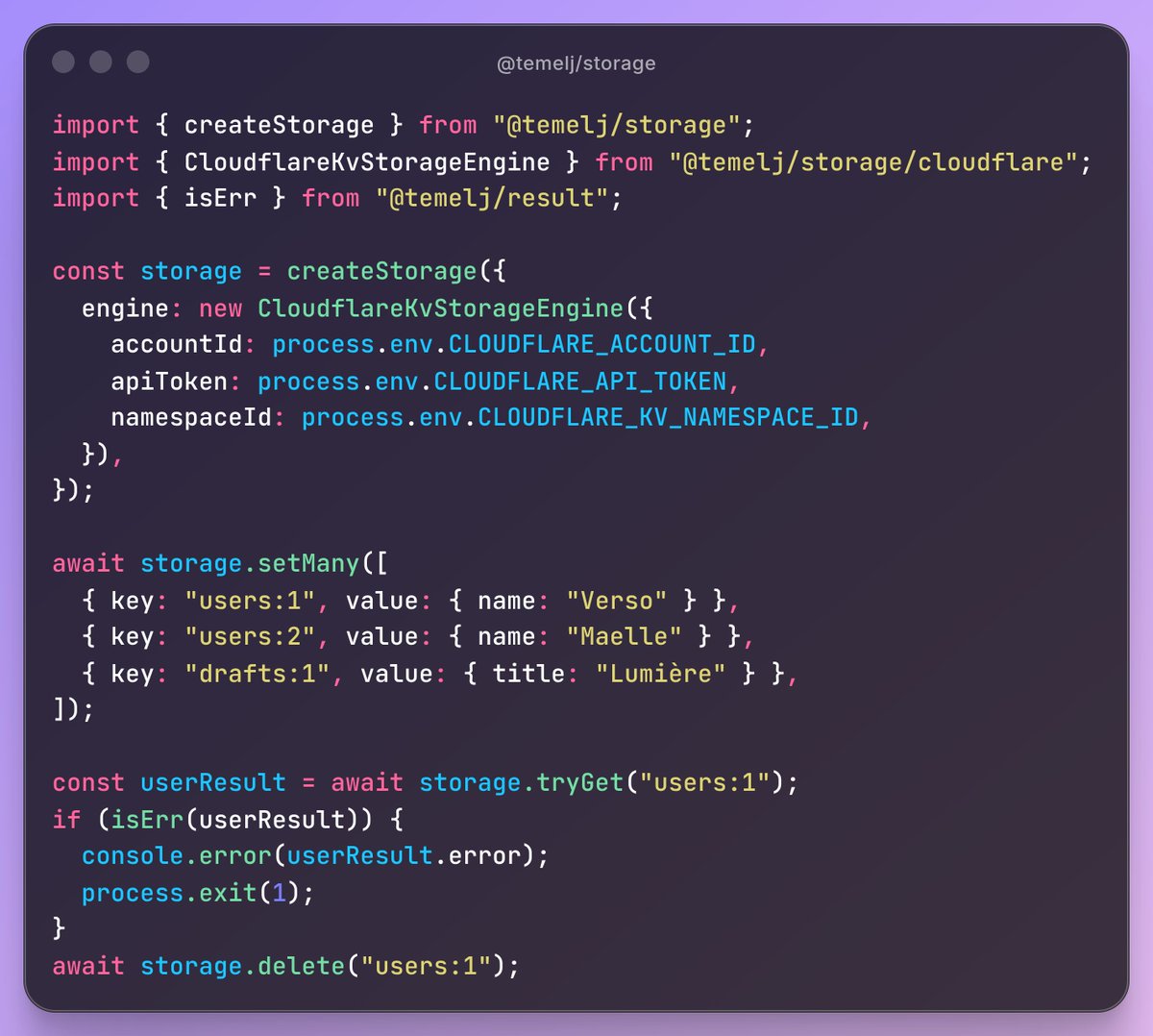
I've published a new package for TypeScript: a unified key-value storage interface.
It provides throwable and `Result<T, E>` error handling. Supports custom codecs: JSON, SuperJSON, binary, etc. Observability with events pubsub. It currently works with node:fs, in-memory store, MySQL, PostgreSQL, libSQL, Redis and Cloudflare KV (worker bindings & rest api).
NPM: npmjs.com/package/@temelj/st…
JSR: jsr.io/@temelj/storage
GitHub: github.com/tinrab/temelj/tre…
1
39
Jun 5
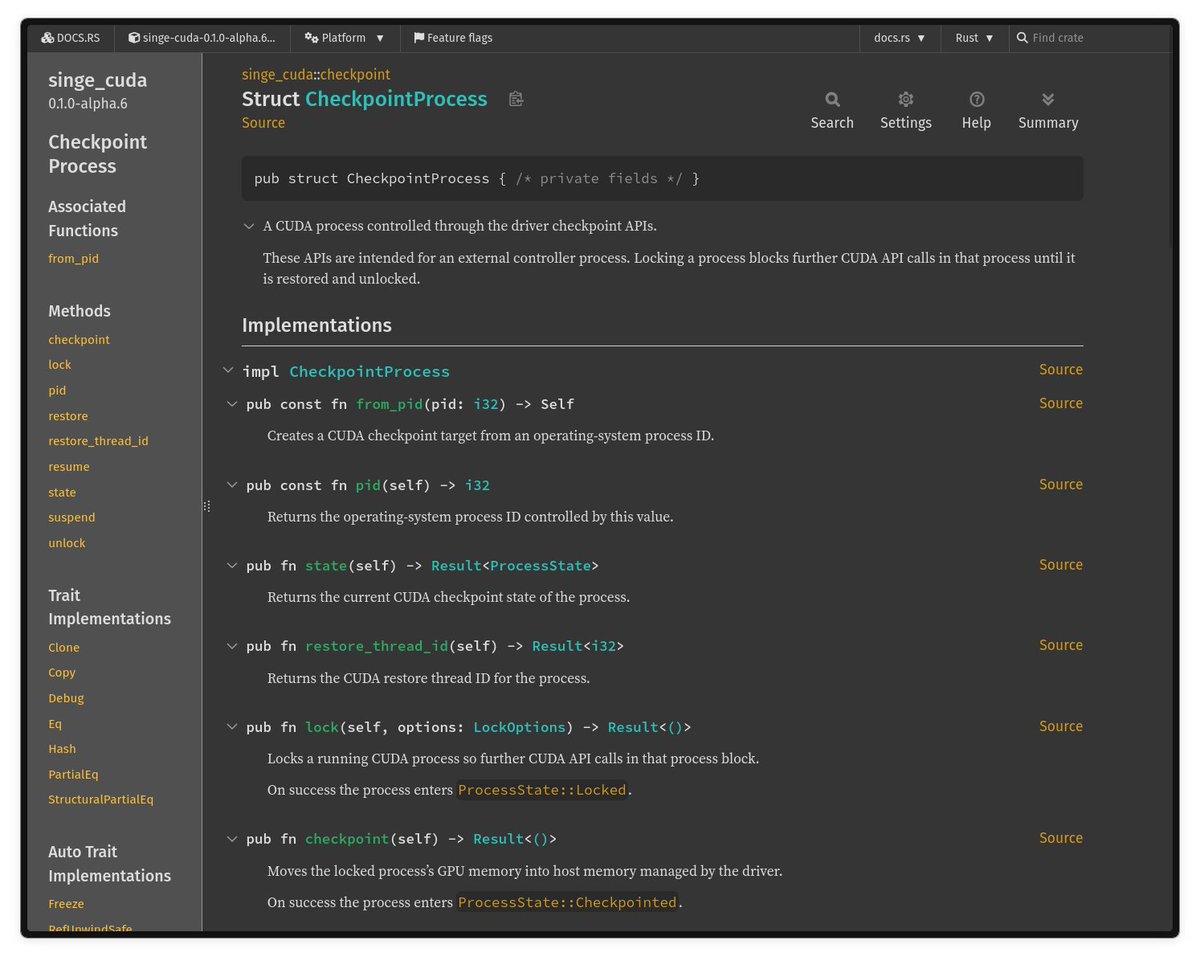
I was reading blog post "How we achieved truly serverless GPUs" by Modal (modal.com/blog/truly-serverl…). The engineering is pretty insane. I came across "CUDA checkpoints," which I somehow never saw before. They can be used alongside CRIU to checkpoint and restore process' state from disk.
So I added it to my Rust CUDA crate.
1
24
Jun 4
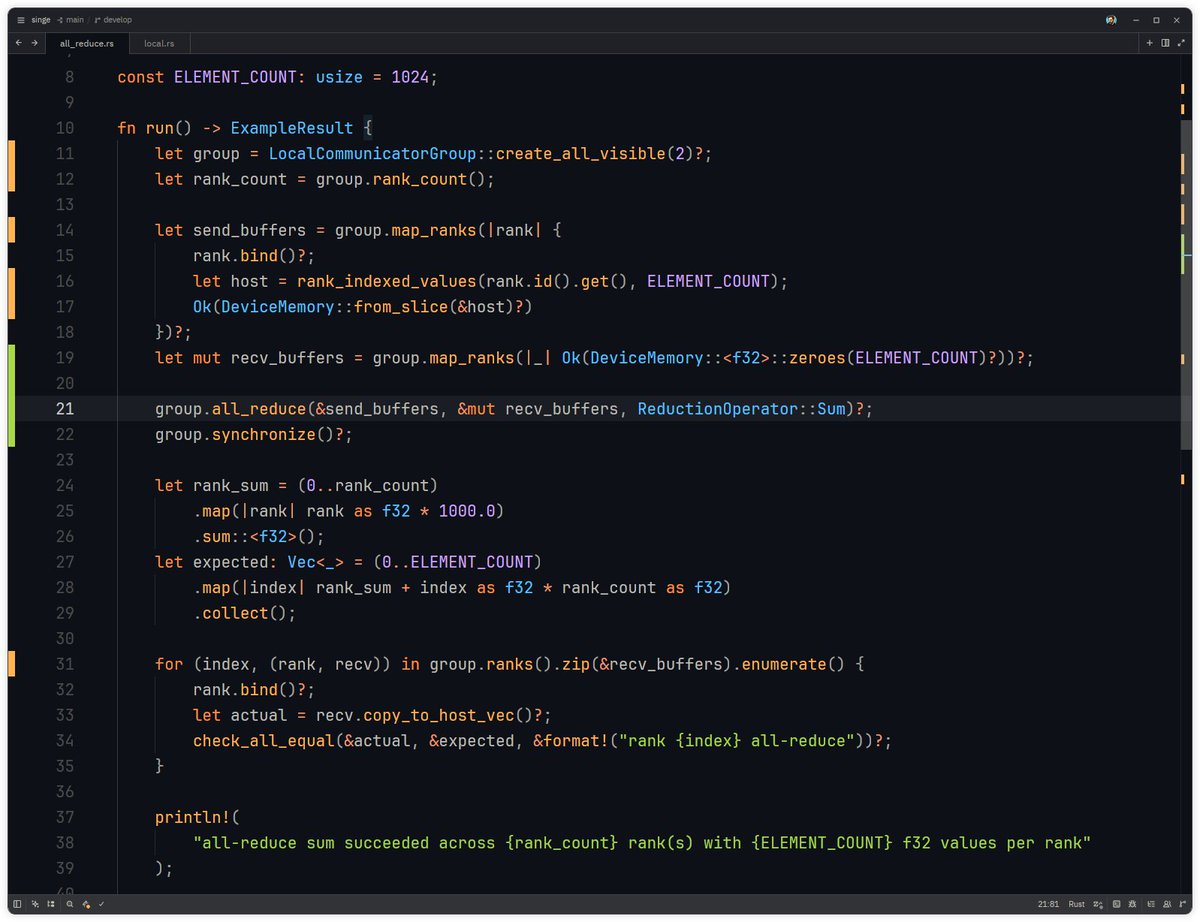
API design for my NCCL Rust wrapper (not final).
Creates device group with one rank per device, creates send/recv buffers, runs all-reduce (take every rank’s input buffer, sum element-wise across ranks, and write the same result to every rank). It hides direct calls to `ncclCommInitAll`, `ncclGroupStart`, etc., and hopefully makes it easier to use in a correct way.
31
Jun 2
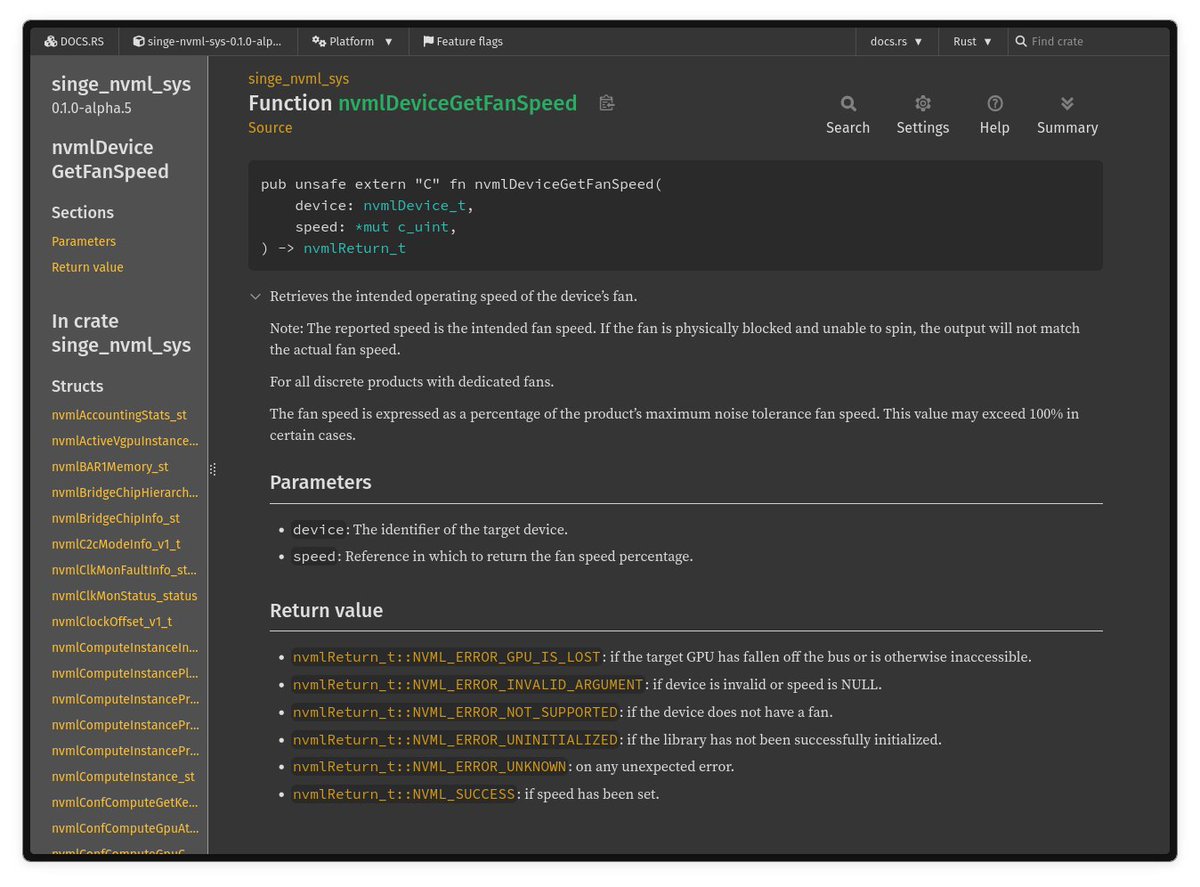
I've built a crate for using NVIDIA Management Library (NVML) in Rust.
Safe and raw bindings. FFI bindings have documentation comments that are near-identical to official docs.
1
1
48
May 5
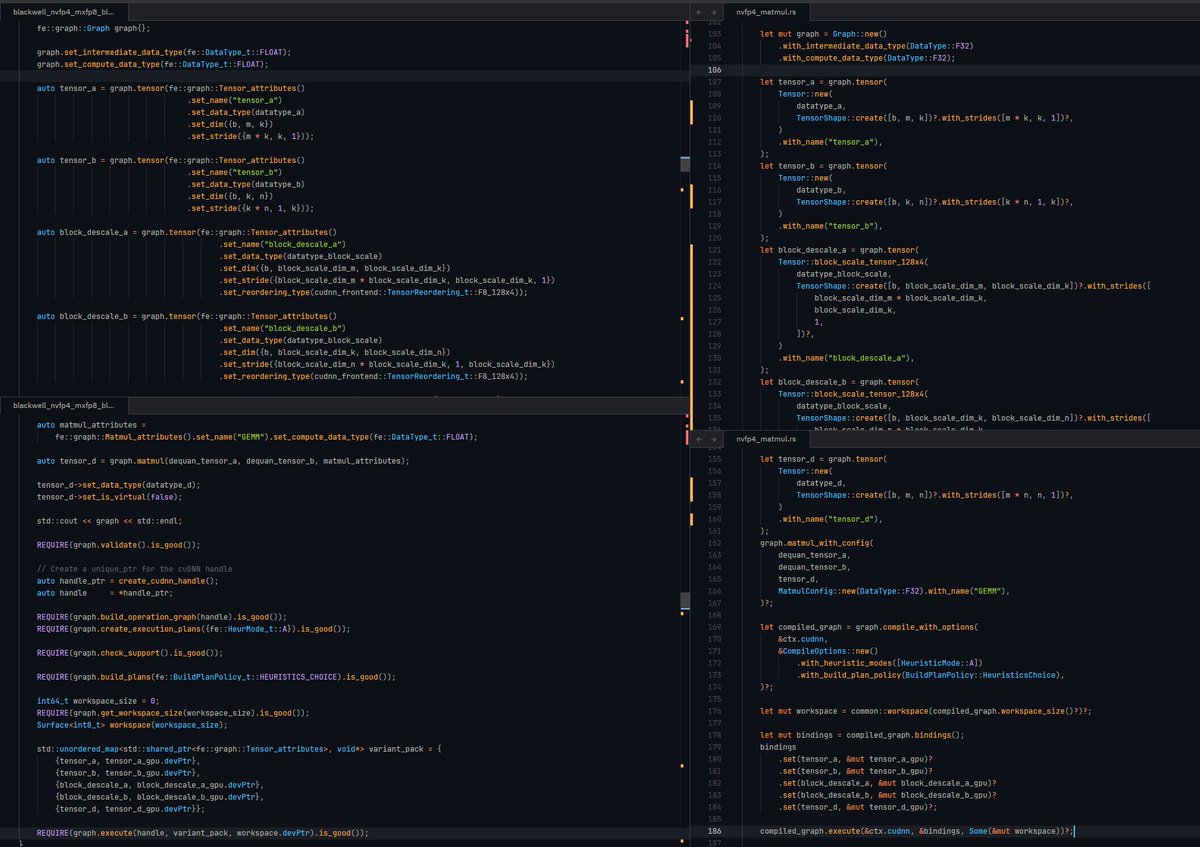
I ported Nvidia's cuDNN frontend library from C to Rust. I needed it in Rust and wanted more control over the internals. cuDNN-frontend provides a simpler graph API over the low-level cuDNN backend. You build a graph of operations, and it handles the lowering to backend APIs, kernel fusion, autotuning, version compatibility expansion, virtual tensor tagging, etc.
I also added more features like a nicer way to interleave custom kernels on the same CUDA graphs as cuDNN. It’s still incomplete and not open source yet.
Here's a snippet from the official examples, NVFP4 matmul and FP16 SDPA, and my own version (not final):

52
Apr 29
LaTeX math in Rust docs for my CUDA crates.
Not final; getting Markdown docs ready is a bit finicky.
#rustlang
2
1
55
Feb 18
Devlog.
I'm working on implementing a vector database in Rust based on LSM-VEC paper (2025 arxiv.org/abs/2505.17152) and ACORN (2024 arxiv.org/abs/2403.04871).
It's very much WIP.
LSM-VEC uses LSM-tree storage with graph-based ANN indexing (similar to HNSW). Smaller upper layers stay in memory, and bottom layers with many vectors are persisted to SSTs.
ACORN addresses the problem with pre-filtering and post-filtering. Pre-filtering gives perfect recall, but it's slow with big data. We can't cut search space without losing some vectors that may match the filter. Post-filtering selects among top K vectors that ANN gives, which means the closest vectors may be filtered out. We could fetch more than K vectors, then filter. ACORN explores neighbors of neighbors (second hop) when direct neighbors are filtered out. This is slower but improves recall.
I've used a custom WAL that I've written for another side-project (it uses mem-mapped files, `rkyv`, `crc32fast`). SST files are organized in blocks (e.g 4KB per block), with compression (zstd) and Bloom filters for point lookups and range scans, which should minimize I/O amplification. Memtable size is configurable. Compaction in the LSM engine works asynchronously in the background. I do soft deletes and tombstone-based GC.
I didn't use tokio or async code in DB, just rayon and parking_lot sync primitives. The server runs with tonic and tokio. Used `rkyv` crate for serialization.
I also implemented replication (not sharding) with Raft (`raft` crate) and a gRPC server with a CLI client. Haven't properly tested raft yet. It's kind of flaky.
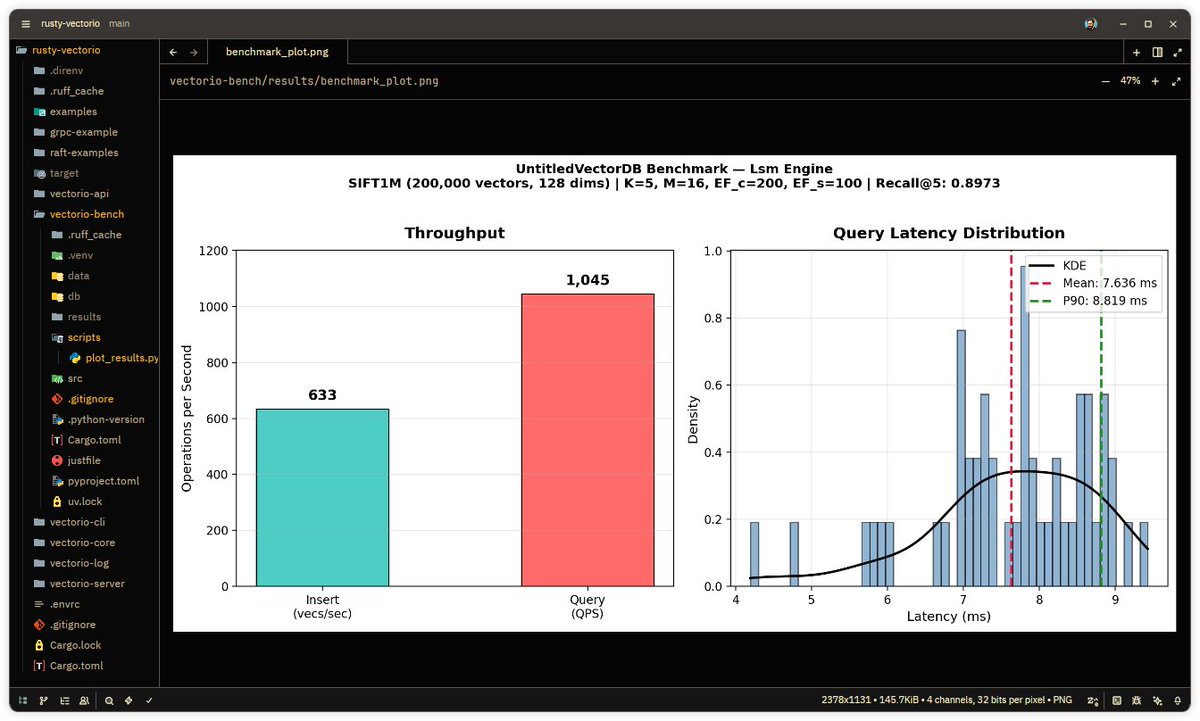
Here's one benchmark running on my 14-year-old laptop. Recall@5 is ~90%. About 40-50% of CPU time is spent on hashing and locking. QPS is quite low currently. For one, I can't get `simsimd` to compile using SIMD (it keeps using `simsimd_l2sq_f32_serial` for some reason), which eats ~20-30% of the CPU. I think my PC is just too old.
Will publish code if I decide to make it not horrendous.
#rustlang
3
103
29 Jul 2025
If you're working with CUDA and require a specific gcc version for nvcc, use Nix.
1
285
7 Jul 2025
Quick tip: in TanStack Start, if you need to build "breadcrumbs" or a dynamic header that depends on a nested route's state, you can fill router's context on beforeLoad and get the data from matches. Then, you only need to include the header component once in a parent layout.
#tanstack #reactjs #webdev
2
1
24
2,197
6 Jul 2025
File uploading to S3 (Minio locally). Uploads can be resumed on browser refresh. TanStack Start, AWS sdk, and some vibe-coded UIs.
2
19
1,755
27 Jun 2025
I've played around with gemini cli a bit. Tried solving an edge case in one of my projects given a failing unit test, and it didn't succeed.
Tried building a Python server for serving AI models from HuggingFace (fairly simple FastAPI server using `transformers` with pipeline APIs, translation and text classification tasks) and deploying it to a local Kubernetes cluster (with GPU support). It did manage to build the service, but I needed to set up the k8s/docker infrastructure pretty much manually.
Then I've tried implementing the BERT language model and got rate-limited. I'm pretty sure I haven't hit the free tier limit.
I should try it in a React codebase more, but inline completions and edits work so much better from my experience. I haven't yet found a good use case for agents (apart from generating slop).
1
186
23 Jun 2025
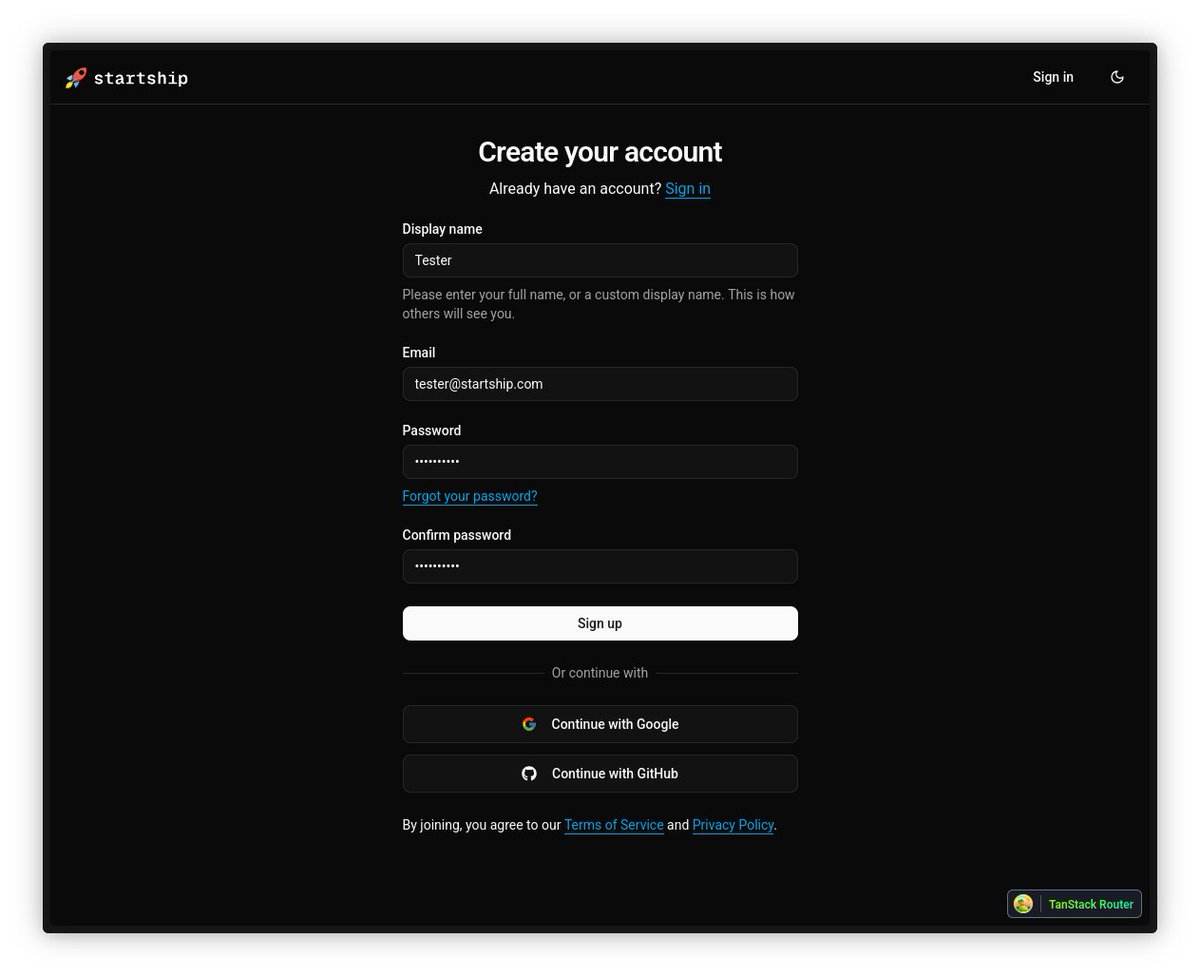
I'm building a TanStack Start SaaS boilerplate for myself. It includes better-auth, Stripe integration, shadcn and other components with a Storybook kitchen-sink, emails (react-email), local Docker dev environment, and other useful stuff. It is a proper monorepo, supported with turborepo. The payment system handles one-time purchases and subscriptions, as well as refunds and invoice payments.
I'll probably open-source it at some point. I found other templates lacking in certain areas, and I think this one could be valuable.
3
15
2,166
23 Jun 2025
TanStack Start is great. There's only a single thing that bugged me, which is that global middleware seems to not work currently: github.com/TanStack/router/i…
1
321
19 Jun 2025
I don't get the point of a "startup school." What is there to learn besides building something people want and selling it to them? I guess it's just for networking.
84
7 Jun 2025
I've built a tool that lets you talk with databases using AI.
It works as a CLI tool or a MCP server on top of MySQL or Postgres. The OpenRouter & MCP integration is a bit unreliable, so it might not work as expected with some models.
GitHub: github.com/tinrab/airy

2
9
1,702
5 Jun 2025
An AI agent that develops other AI agents, working together to optimize shareholder value through evolutionary competition.
145