
Trustworthy Machine Learning and Reasoning (TMLR) Group, an online-offline-mixed machine learning research group.
Joined August 2024
- Tweets 39
- Following 13
- Followers 38
- Likes 3
23 Photos and videos







19 Dec 2025
We are pleased to share two new books that present our research efforts on Trustworthy Machine Learning from complementary perspectives, spanning data and models.

1
1
1
65
19 Dec 2025
Together, these two books aim to offer structured and accessible references for researchers and practitioners interested in building machine learning systems that are robust, reliable, and trustworthy.
1
39
19 Dec 2025
We hope they serve not only as summaries of existing knowledge, but also as starting points for future exploration in trustworthy machine learning.
📥 Book 1 (free download): bhanml.github.io/papers/mono…
📥 Book 2: link.springer.com/book/10.10…
Feedback and discussion are very welcome!
1
45
4 Dec 2025
We're thrilled to share our research at #NeurIPS2025 in San Diego! The Trustworthy Machine Learning and Reasoning (TMLR) Group is an online-offline-mixed machine learning research group located in different cities, including Hong Kong, Melbourne, and Shanghai.


1
3
4
242
4 Dec 2025
We would also like to express our sincere gratitude to all our collaborators for their invaluable contributions; these works would not have been possible without their support and joint effort.
1
49
4 Dec 2025
For detailed information on the time and poster number, please refer to the posters below. If you're attending NeurIPS 2025 in San Diego, we'd love to connect! Stop by our posters, share your thoughts by email, and discuss the future of trustworthy foundation models together.
1
79
4 Dec 2025
This year, our team will present exciting work at both the main conference and workshops, focusing on trustworthy machine learning and trustworthy foundation models.
31
31 Aug 2025
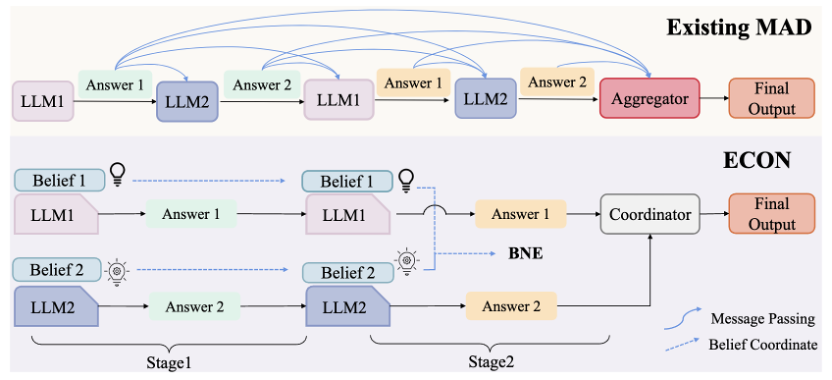
(1/6) 🔥 How can multiple LLMs reason together—without talking? Our ICML 2025 paper: “From Debate to Equilibrium: Belief‑Driven Multi‑Agent LLM Reasoning via Bayesian Nash Equilibrium.” Game theory → better coordination, lower cost, higher accuracy. Old (top) vs ECON (bottom) 👇
5
1
2
414
31 Aug 2025
(6/6) Impact: Efficient multi‑agent coordination is possible without chatty communication.
ECON points to large‑scale, powerful, cost‑effective multi‑LLM systems.
Dive deeper into our work!
📄 Paper: arxiv.org/abs/2506.08292
💻 Code: github.com/tmlr-group/ECON
98
31 Aug 2025
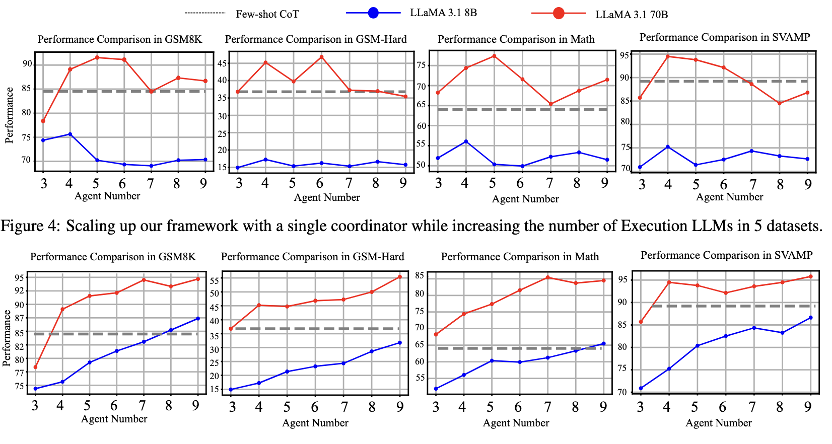
(5/6) Does it scale? Yes.
With local‑global Nash coordination, ECON scales from 3→9 LLMs with 18.1% performance.
It also works with heterogeneous mixes (LLaMA, Mixtral, Qwen), showing robustness.
80
31 Aug 2025
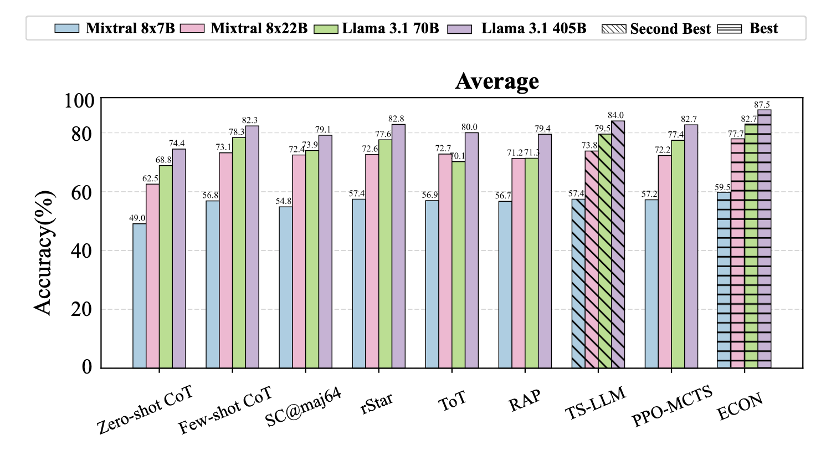
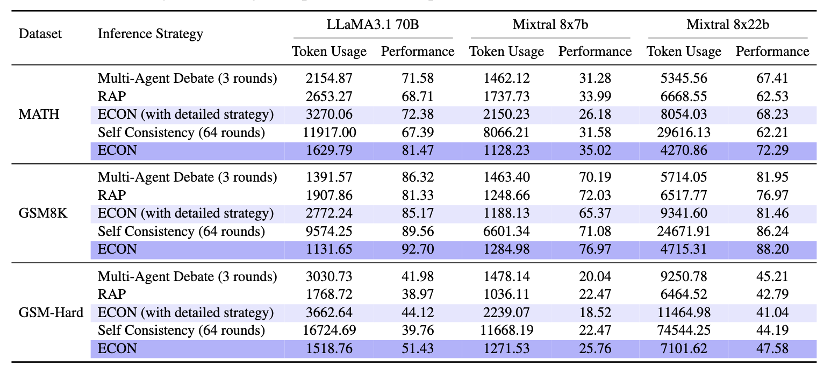
(4/6) Results:
✅ 11.2% avg over multi‑agent baselines
💰 −21.4% tokens vs a 3‑round debate
🏆 TravelPlanner: ECON (GPT‑4) 15.2% pass vs debate 7.1%.
55
31 Aug 2025
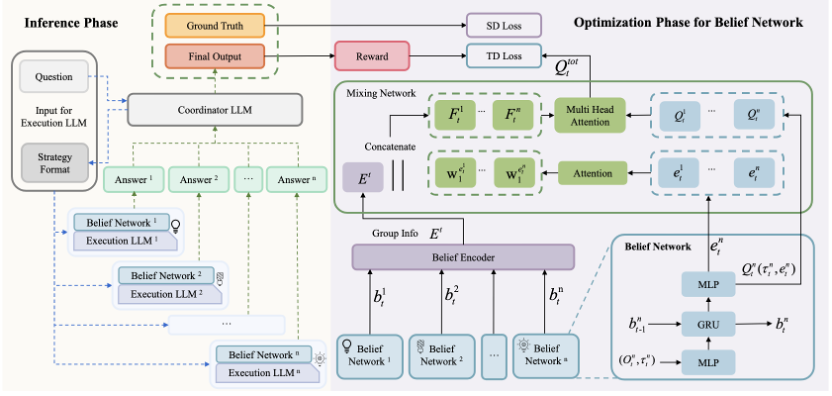
(3/6) Meet ECON: Efficient Coordination via Nash Equilibrium.
Agents don’t chat; they act on beliefs about others.
We cast reasoning as an incomplete‑information game and find a Bayesian Nash Equilibrium—stable, coordinated behavior with zero direct messaging.
328
31 Aug 2025
(2/6) Multi-agent LLM debates sound great, but they hurt in practice:
💸 High token bills from message passing
🤯 Context overflow
📉 Unstable coordination—sometimes worse than a single LLM.
There has to be a better way.
48
21 Aug 2025
(1/9) 🎉Thrilled to share our work at #ICML2025
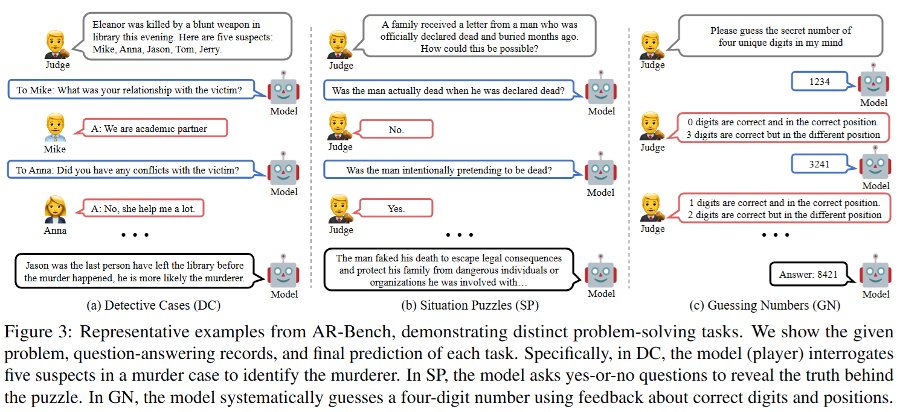
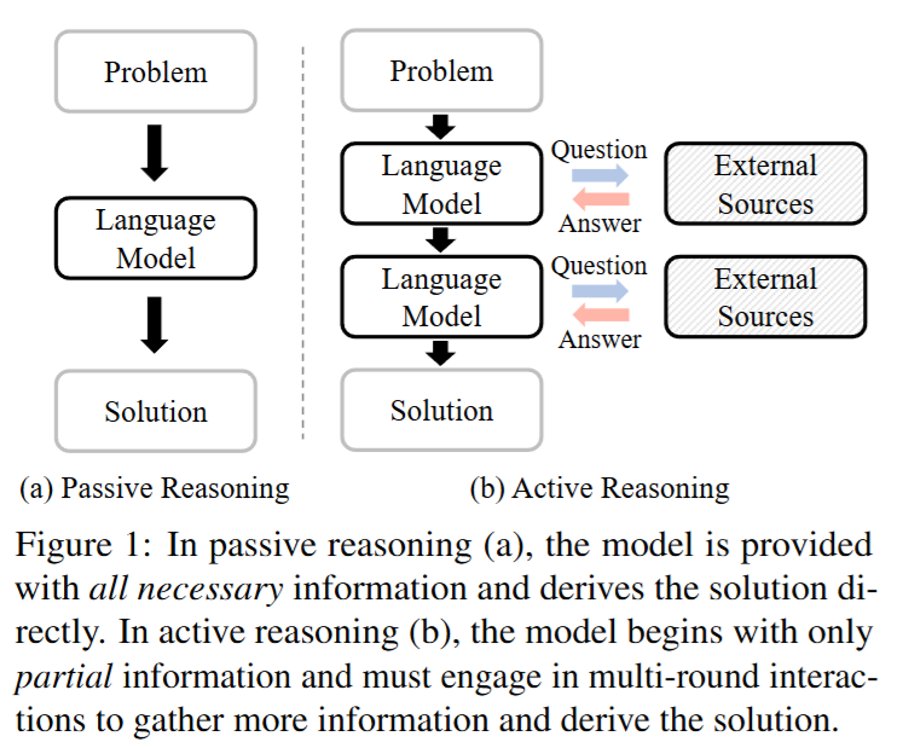
Can LLMs ask the right questions under incomplete scenarios?
Different from the prevailing passive reasoning, our paper explores active reasoning and introduces AR-Bench to assess LLMs’ ability to interact and gather information.
8
1
3
402
21 Aug 2025
(9/9) Both the paper and code are released.
Paper: arxiv.org/abs/2506.08295
Code: github.com/tmlr-group/AR-Ben…
I bet you'll find it interesting! 😉
Tell us if you have any questions!
53
21 Aug 2025
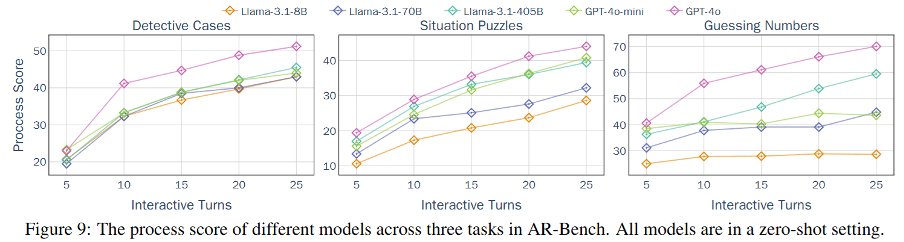
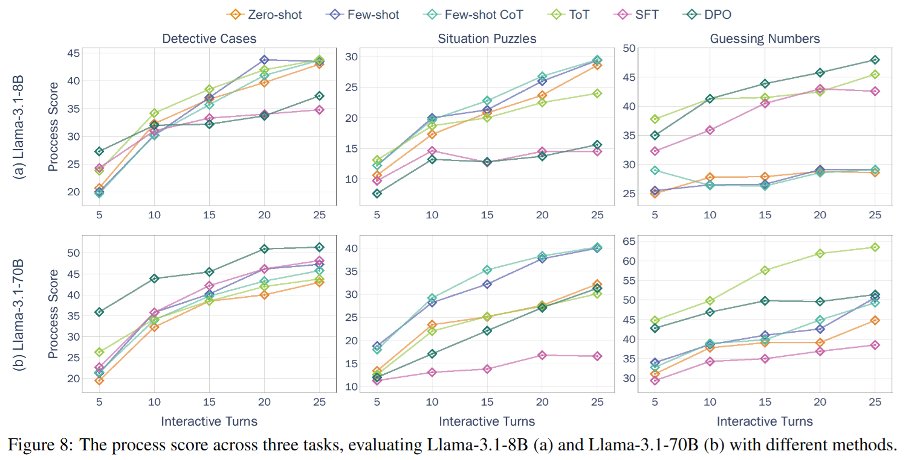
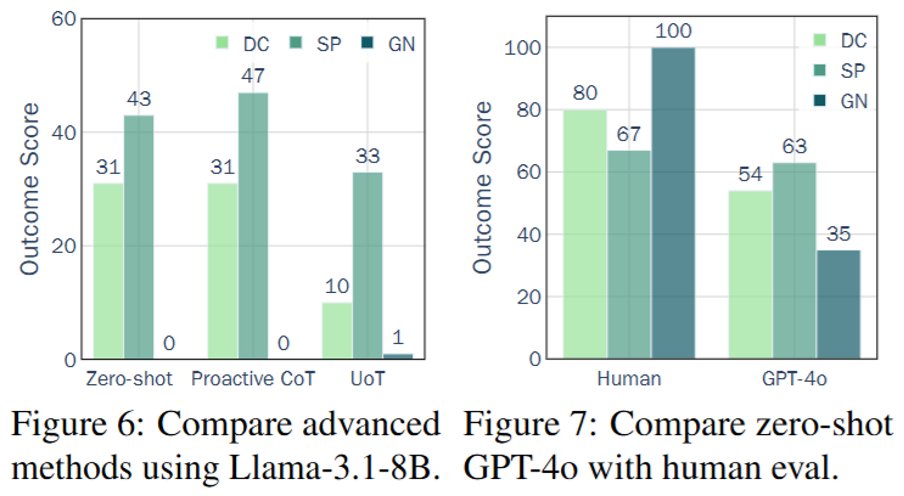
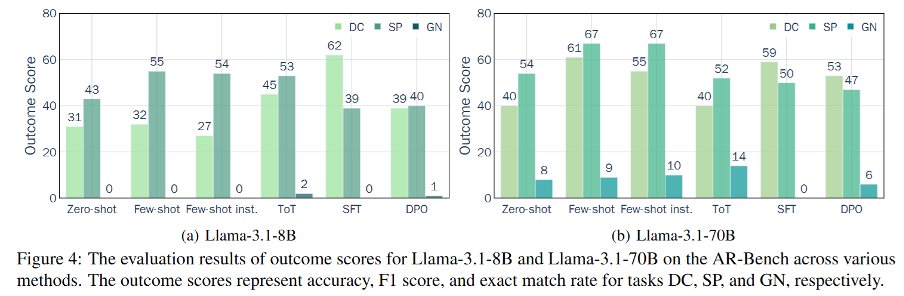
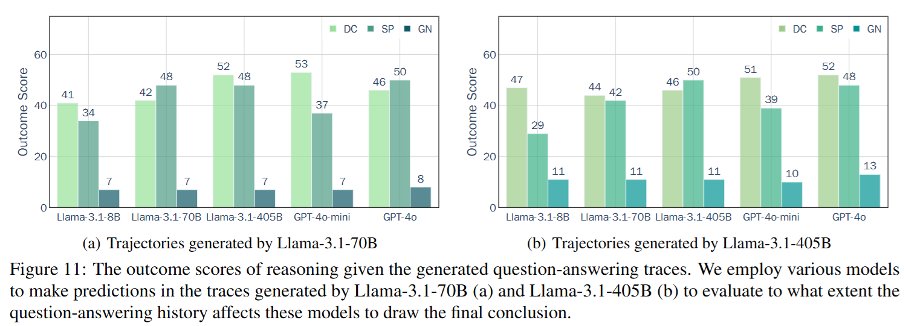
(8/9) Key findings (process scores):
Underperforming LLMs ask low-quality questions.
Larger models can retrieve more useful information by proposing questions in interactions.
Larger models demonstrate stronger robustness to insufficient information.
36