
Issue Tracking for AI Agents - Open Source
Joined January 2022
- Tweets 354
- Following 2
- Followers 1,153
- Likes 305
105 Photos and videos












Pinned Tweet

Apr 10
We've been cooking Latitude v2 and we're launching soon.
v2 surfaces real failures from your AI production traces, then auto-generates evals so the same problem doesn't repeat.
Sentry, but for AI agents.
Link to the waitlist below🔥
1
4
12
694
Jun 12
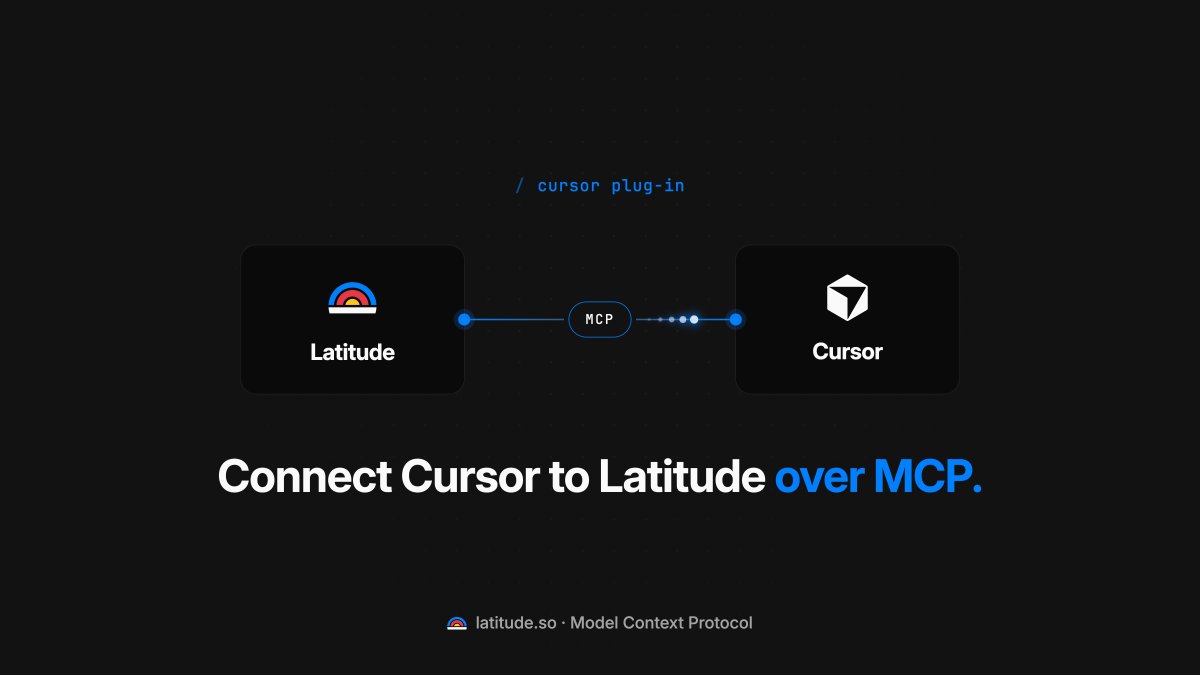
With the MCP connected you can do everything you would normally do in Latitude's UI through Cursor.
It's especially useful if you need to iterate upon your agent with any findings from Searching or Issues.
1
2
148
Jun 11
1
4
8
332
Jun 11
Check out how to integrate here:
Vercel
ai-sdk.dev/providers/observa…
OpenAI
openai.github.io/openai-agen…
Agno
docs.agno.com/observability/…
1
2
147
May 29
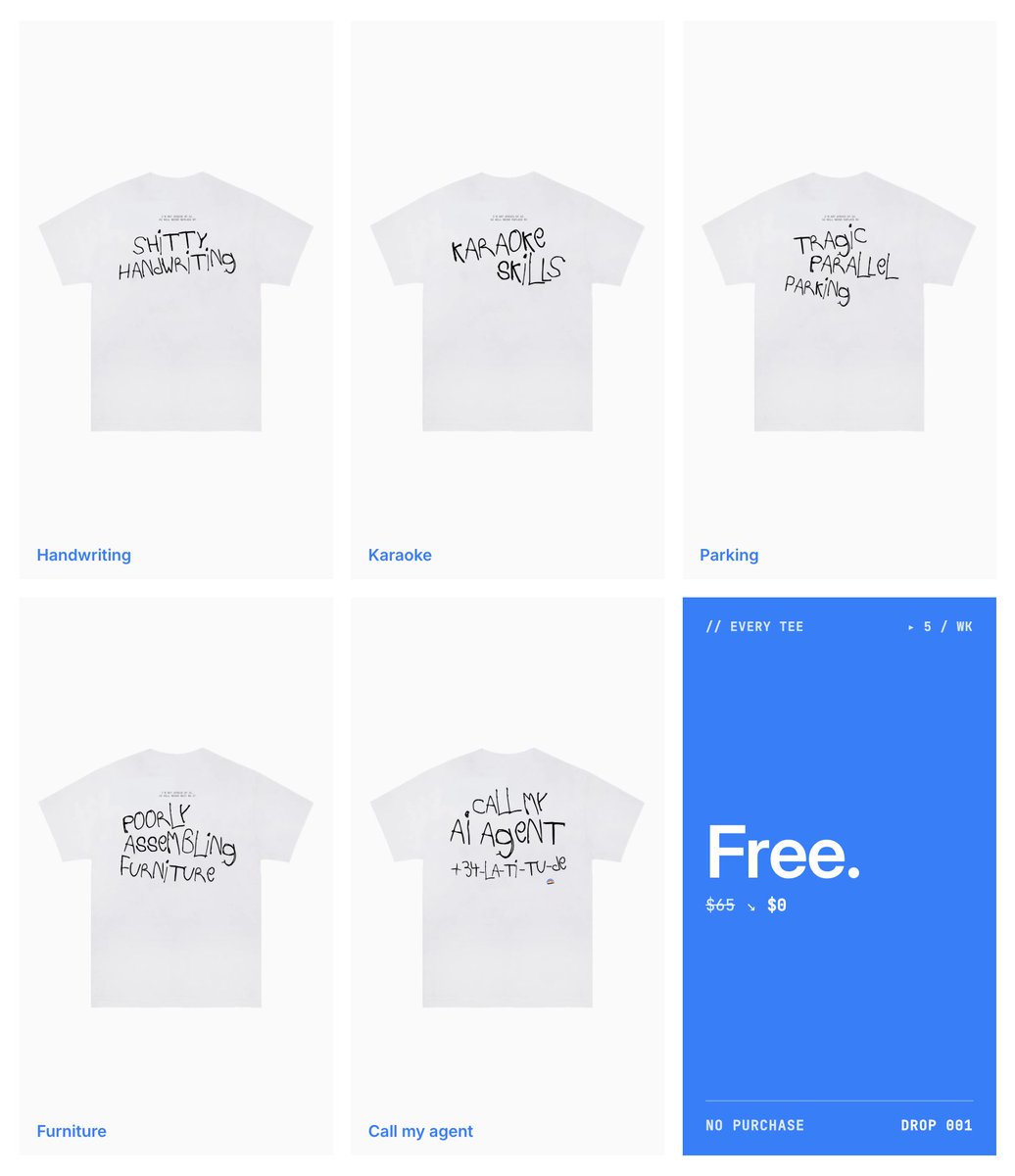
giving away some merch!

Do you use Claude Code and want free merch?
We’re opening a merch store to celebrate the v2 launch and giving away 5 t-shirts every week.
To participate:
---
1. Connect Claude Code to Latitude with 1 command
2. Every Friday you'll get an email with your Claude Code usage stats
3. Screenshot it and post it on X tagging @trylatitude
The top 5 posts each week win a t-shirt. We'll DM the winners directly.
---
Link to the merch store: 41st.latitude.so/
Link to Latitude: latitude.so/claude-code
1
126
May 27
Claude Code observability is on Latitude🔥
Install it with 1 command and see full sessions: system prompt, every tool call, subagents, per-turn cost.
Useful if you keep hitting @claudeai limits or run Claude Code as a harness for your own agent.
Free and open source.
2
9
2,122
May 5
We’ve put together a guide on how to get started with AI evals.
It covers:
- The 3 types of evals and when to use each
- How to design a repeatable evaluation framework
- A checklist to implement this in your own workflow in < 3 days
1
3
219
Apr 10
We've been cooking Latitude v2 and we're launching soon.
v2 surfaces real failures from your AI production traces, then auto-generates evals so the same problem doesn't repeat.
Sentry, but for AI agents.
Link to the waitlist below🔥
1
4
12
694
Mar 24
We just launched Evals for AI Agents 🚀
A free course on how to build targeted evals for your agent (and not just generic ones).
1
2
307
Mar 24
What's inside:
→ Generic vs. targeted evals (and why the difference matters)
→ Online vs. offline regression testing
→ Human-in-the-loop evaluation annotating traces
→ LLM-as-a-Judge: when to use it and how to write judge prompts that work
→ Programmatic rules how to integrate all 3 eval types
→ Building a golden dataset from real issues
1
1
197
Feb 5
When we released the first track of our AI PM course, 1,000 people registered in 3 days.
That pushed us to ship the full course quickly.
If you’re building AI products and want a practical framework, this is for you.
The full course is now on YouTube 🚀
1
1
5
251
Feb 5
Watch on YouTube: youtube.com/playlist?list=PL…
View on Latitude Academy: academy.latitude.so/become-a…
204

Feb 2
New video on the channel 👇
We walk through how to manage prompt versions in Latitude: publishing, tracking changes, and safely rolling back when quality drops in prod.
Watch it here → youtu.be/Opi8YFypptM
1
5
235