
Joined April 2011
- Tweets 259
- Following 566
- Followers 92
- Likes 555
36 Photos and videos











【1/5】
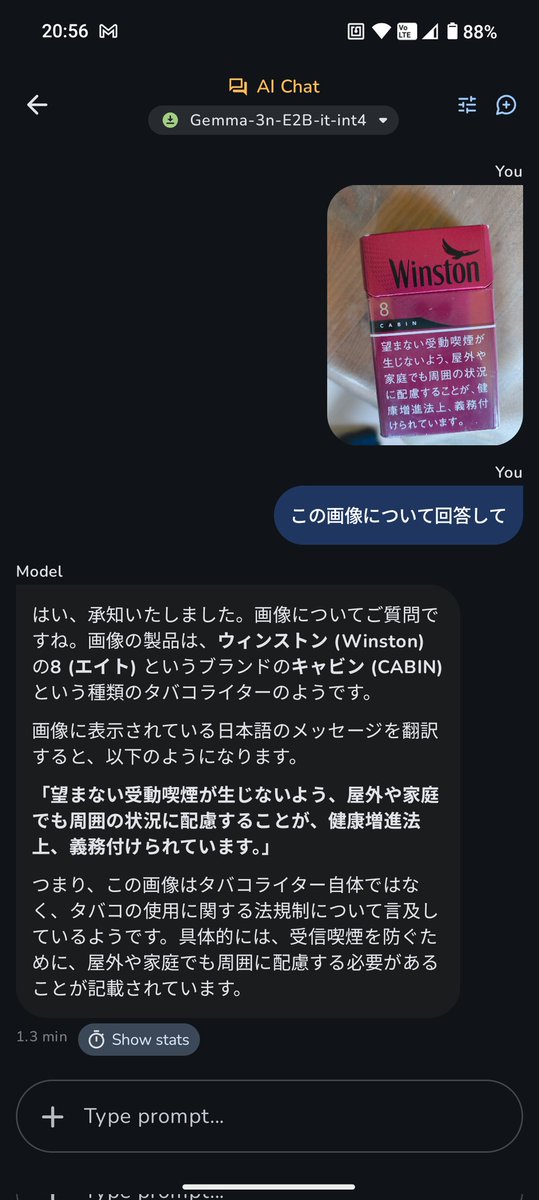
【VRAM16GBのAPUでGemma 4 26Bを262Kコンテキスト&17t/sで動いた設定】
ループせずに「超長文×そこそこ高速化」を両立できたので、再現できるように環境・モデル・起動パラメータをポストします!APU環境の人はぜひ試してみて👇
1
59
【4/5】
4. コマンド
./llama-cli -m gemma-4-26B-A4B-it-qat-UD-Q4_K_XL.gguf -ngl 99 --model-draft mtp-gemma-4-26B-A4B-it.gguf --spec-type draft-mtp --gpu-layers-draft 99 --spec-draft-n-max 6 --spec-draft-p-min 0.7 -c 262144 -fa on -ctk q4_0 -ctv q4_0 --no-mmap -t 6 -tb 6 -fit off
1
56
【5/5】
🔍 5. パラメータ
・-ngl 99 / --gpu-layers-draft 99 : 100% GPU
・--spec-type draft-mtp : MTP指定
・-c 262144 : モデルの限界
・-ctk q4_0 / -ctv q4_0 : KVキャッシュ4bit化
・-t 6 / -tb 6 : 物理8コア中6スレッドに制限
・-fit off : Vulkanのメモリ確保バグによるクラッシュ回避
62

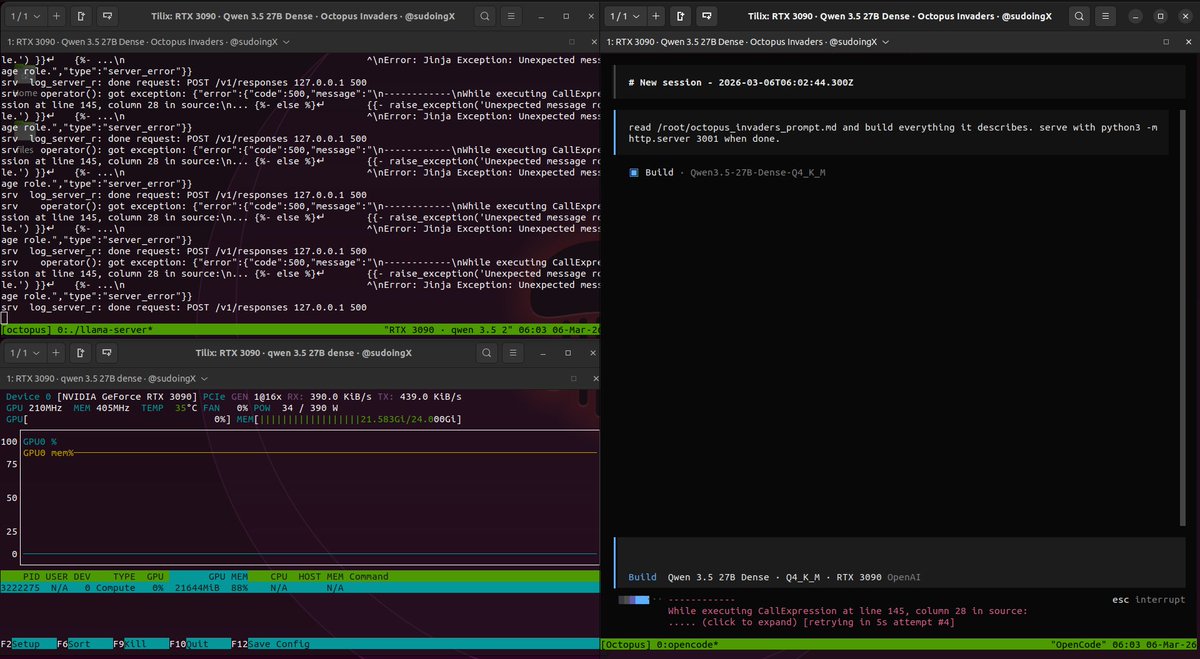
if you try to run qwen 3.5 27B with OpenCode it will crash on the first message.
OpenCode sends a "developer" role. qwen's template only accepts 4 roles: system, user, assistant, tool.
anything else hits raise_exception('Unexpected message role.') and your server returns 500s in a loop.
unsloth's latest GGUFs still ship with the same template. the bug is in the jinja, not the weights. no quant update will fix it.
the common fix floating around is --chat-template chatml. it stops the crash. it also silently kills thinking mode. your server logs will show thinking = 0 instead of thinking = 1. no think blocks. no chain of thought. you're running a reasoning model without reasoning and the server won't tell you.
the real fix: patch the jinja template to handle developer role preserve thinking mode.
add this to the role handling block:
elif role == "developer" -> map to system at position 0, user elsewhere
else -> fallback to user instead of raise_exception
full command with the fix:
llama-server -m Qwen3.5-27B-Q4_K_M.gguf -ngl 99 -c 262144 -fa on --cache-type-k q4_0 --cache-type-v q4_0 --chat-template-file qwen3.5_chat_template.jinja
thinking = 1 confirmed. full think blocks. no crashes. that's what's running in the video in the thread below.
if you've been using chatml as a workaround, check your server logs for thinking = 0. you might be running half a model.

next post: the Jinja thinking mode fix that makes all of this work in OpenCode. without it, multi turn crashes and thinking tokens get stripped. 5 minute fix, saves hours of debugging.
after that: full 3 way comparison article. MoE vs Dense vs Hermes. every data point, every config, every failure mode. same prompt, same GPU, three architectures, one conclusion.
22
45
432
95,297
chorisso retweeted

14 Nov 2025
\ Hello World ! /
【無料版】まじん式 v4
動画からスライドが自動生成!?動くグラフも!?
@Majin_AppSheet #note #Majincraft
note.com/majin_108/n/n192d21…
662
8,486
5,992
1,272,266

1 Nov 2025
acemagic s3a 8745hsが49000円で購入できたので購入。早速vramにメモリ割り当てようとしてもbios画面に「AMD CBS」が出てこない
わざわざ隠しメニューにされてるようでbios画面の「Advanced」タブに移動した状態で、Ctrl F1 キーを押すと表示されるので同じように困ってる人いたら参考にしてみて
2
110
4 Jul 2024
ゼンレスゾーンゼロのイベント #catchaboo でボンプを捕まえました!イベントに参加してリポストすると報酬をゲットできるチャンスが!
@ZZZ_JP
zenless-catchaboo-jp.belugac…
3
226
26 Dec 2023
100株買って8年くらいでモト取れるじゃないか!
楽天(データ専用)×日本通信(合理的290の30秒11円)
楽天(データ専用)×povo(30秒22円)
前者は月額かかっちゃうけど比較的通話する人、後者は月額かかんないけど180日毎に課金するのが面倒そう…
#楽天株主優待
k-tai.watch.impress.co.jp/do…
2
676
chorisso retweeted

1 Nov 2023
45
225
35,776