
Vector Institute transforms cutting-edge artificial intelligence research into practical solutions. AI-generated content will be disclosed. FR: @InstitutVecteur
Joined March 2017
- Tweets 4,132
- Following 540
- Followers 29,592
- Likes 4,426
1,153 Photos and videos

















Jun 9
Sometimes the biggest gains in AI come from old ideas, seen fresh.
Dillon Chen returned as a Vector Research Intern for Winter 2025 and Winter 2026, working with Vector Faculty Member and Canada CIFAR AI Chair Sheila McIlraith on long-horizon planning and sequential decision making – key building blocks for autonomous systems that need to be efficient, safe, and reliable.
A standout insight from his work: revisiting foundational, decades-old concepts can outperform newer, heavily engineered approaches, and unlock major speed-ups in compute.
But it was the day-to-day experience, with strong access to research resources and compute, and the chance to learn directly from bright, motivating researchers and colleagues, that helped him move faster, learn more, and stay ambitious about what was possible.
Apply for Winter 2027 Research Internships by June 22: na3.hubs.ly/y0vH7g0
1
1
4
748
Vector Institute retweeted

Jun 5
AI already supports 150,000 jobs in Canada, and more than 800,000 people work across ourbroader digital economy.
Our new strategy, AI for All, invests $350 million in Canadian AI institutions like @VectorInst, so that AI is developed here — safely, responsibly, and to benefit of all Canadians.

ALT Prime Minister Carney tours an artificial intelligence institute in Toronto, Ontario.
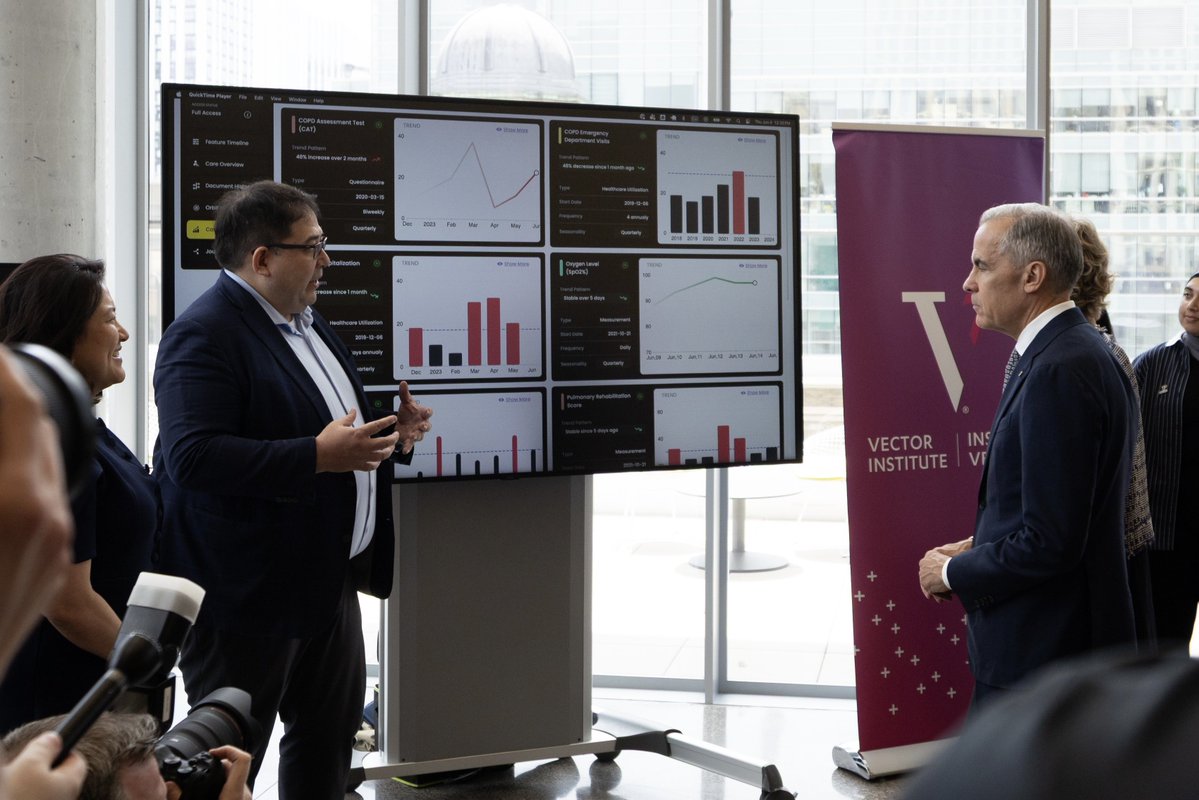
ALT Prime Minister Carney tours an artificial intelligence institute in Toronto, Ontario.

ALT Prime Minister Carney tours an artificial intelligence institute in Toronto, Ontario.
467
123
598
54,031
Vector Institute retweeted

Jun 1
How do we improve VLM post-training?
Don't just force longer-horizon multimodal reasoning.
Reshape the curriculum to match how VLMs learn. 👀➡️🧠
Excited to share our new #ICML2026 paper in collaboration with @ucsc @amazon @UWaterloo @VectorInst:
"From Seeing to Thinking: Decoupling Perception and Reasoning Improves Post-Training of Vision-Language Models"
🌐 Project: ucsc-vlaa.github.io/VLM-CapC…
📄 Paper: arxiv.org/abs/2605.20177
💻 Code: github.com/UCSC-VLAA/VLM-Cap…
🤗 HF Collections: UCSC-VLAA/VLM-CapCurriculum
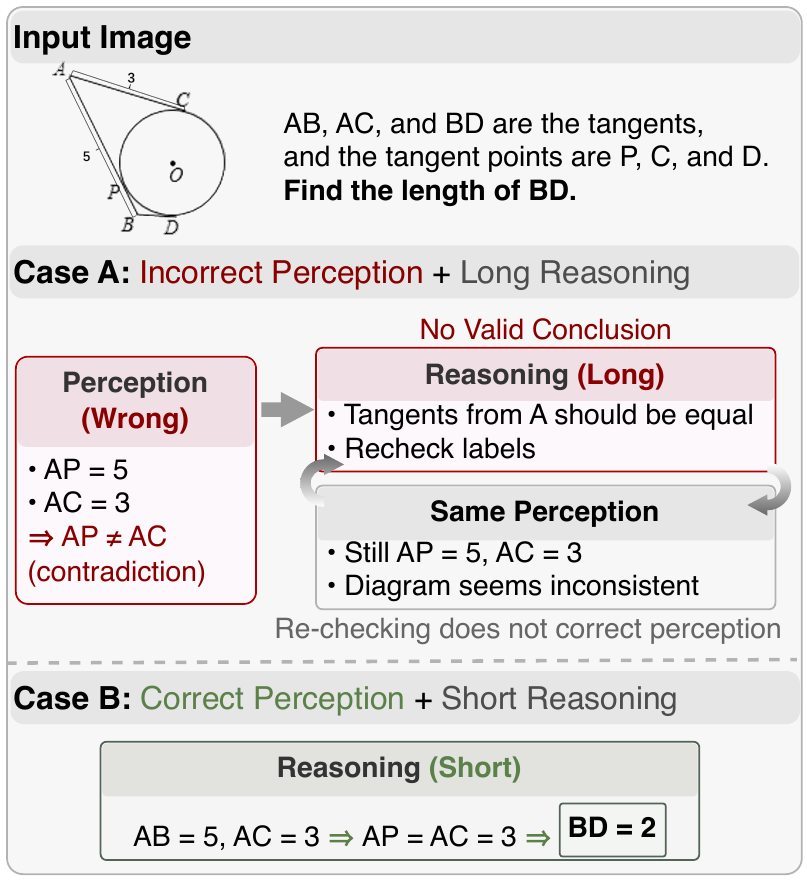
Recent VLM post-training has largely focused on scaling up reasoning through RL and long chain-of-thought traces. But after auditing model failures across visual math, geometry, and diagram reasoning tasks, we found a different bottleneck:
👉 86.9% of Qwen3-VL-8B's errors originate from perception, not reasoning.
Once a model misreads the image, additional reasoning often just reinforces the wrong interpretation.
Our key insight is simple: before a model can reason better, it must first see better.
To achieve this, we introduce a new simple capability curriculum for VLM post-training:
🟦 Visual Perception → 🟩 Textual Reasoning → 🟨 Visual Reasoning
Instead of mixing all capabilities into a single RLVR stage, we train them sequentially, allowing perception to develop as a dedicated foundational capability.
The results are remarkably consistent:
✅ Staged post-training outperforms standard merged training across 4 VLM backbones (#Qwen2.5-VL, #Qwen3-VL, #InternVL3, #InternVL3.5)
✅ Better perception literally lets the model think less!The staged post-training on #Qwen3-VL-8B uses only 79% of the reasoning tokens of the merged model (20.8% shorter traces) achieves 1.46% average accuracy.
✅We also show that capability curriculum and traditional difficulty curriculum are complementary. On #Qwen3-VL-8B, combining both boosts average performance from 58.6 → 63.0, outperforming either curriculum alone.
The broader message is that curriculum learning for VLMs should not only consider how difficult an example is, but also which capability it develops.
📦 We are releasing everything:
1️⃣ A new capability curriculum paradigm, orthogonal to difficulty-based curricula
2️⃣ High-quality perception training data built with a scalable DOCCI-based synthesis and filtering pipeline
3️⃣ 4 staged-trained VLMs: #Qwen2.5-VL-7B, #Qwen3-VL-8B, #InternVL3-8B, and #InternVL3.5-8B
4️⃣ Full training, evaluation, and perception-error analysis code
Led by my PhD student @JJwu41867797, as well as an outstanding team of collaborators @HardyChen266091,
@HaoqinT, Xianfeng Tang, @fredahshi, Hui Liu, Hanqing Lu, @cihangxie
May 28

🧠Your VLM didn't fail because it didn't think long enough. It failed because it looked wrong: We found #Qwen3-VL-8B's wrong answers trace back to a perception error — not a reasoning one 📉.
💡Our fix: a capability curriculum — a brand-new curriculum dimension that trains perception before reasoning. 🔍➡️🤔
Excited to share our new @icmlconf paper: From Seeing to Thinking: Decoupling Perception and Reasoning Improves Post-Training of Vision-Language Models
🌐 Project: ucsc-vlaa.github.io/VLM-CapC…
📄 Paper: huggingface.co/papers/2605.2…
💻 Code: github.com/UCSC-VLAA/VLM-Cap…
3
15
47
8,527
Vector Institute retweeted

May 29
“Safety of AI is a necessity for our country because of the data that we have. Through this, we can unlock all kinds of work and research that we can export globally.” — Glenda Crisp, CEO @VectorInst at the AI Task Force event today @Empire_Club

1
6
1,703
Vector Institute retweeted
May 29
Great discussions today at the launch of our AI Task Force Report at the @Empire_Club focusing on what real change in the age of #AI looks like. ontariosuniversities.ca/repo…




2
4
1,379
May 28
From founding sponsor to five more years: @BMO is renewing their partnership with Vector through 2031, deepening nearly a decade of work in responsible AI. 🎉
Read the full announcement: newswire.ca/news-releases/bm…
#ResponsibleAI #AIinCanada


1
2
785
May 27
⏰ Last call for Vector Institute's Fall 2026 Applied Internship Program.
Applications close Thursday, May 28 at 1:00 PM ET.
How's your application progress?
0%
✅ Application submitted
0%
📝 Finishing up now
0%
🤔 Still deciding
0%
➡️ Sharing with others
0 votes • Final results
1
1
3
1,183
May 27
This program offers direct access to Canada's AI research ecosystem, with projects that contribute to real industry applications.
Interns work alongside leading researchers and industry partners.
Don’t miss your chance – apply today!
vectorinstitute.ai/programs/…
2
3
871
May 25
Applied Machine Learning Intern Ahmed Radwan started with one goal: build, not just study. And his Vector internship delivered.
During his Fall 2025 term with Vector's AI Engineering team on AIXpert, Ahmed developed:
→ SONIC-O1: a benchmark to identify and reduce bias in AI used in job interviews and healthcare settings
→ UnBias-Plus: a tool that helps journalists detect and rewrite biased language in under a minute
Here he learned to think beyond implementation – to ask not just how to build a solution, but why it was strategically necessary.
What will you learn as a Vector intern? Applications for Fall 2026 Applied Internships are now open with three paid roles across ML, AI program delivery, and public sector AI adoption.
Applications close May 28.
Apply here 👇 na3.hubs.ly/y0tL8S0
1
7
1,148
May 20
Meet Sunehra Sarwar.
As a Vector intern, Sunehra led an AI partnership between Vector and a crisis helpline, working to improve service delivery through AI.
She was there for every stage of the project lifecycle: use case exploration, planning, development and testing.
The work required collaboration across AI engineering, industry innovation, and data operations. She came away with a real, end-to-end view of what it takes to execute an AI implementation from the ground up.
The IMPACT Mentorship Program gave her direct access to professionals navigating the careers she was working toward – with candid conversations that helped her identify which skills to build and why.
She's now an Associate Project Manager on Vector's Health AI Implementation Team.
Where will Vector’s Applied AI Internships take you? Apply before May 28 at 1:00 PM ET to find out 👇 na3.hubs.ly/y0tkq40
1
3
646
Vector Institute retweeted
May 15
The age of #AI is here – and Ontario’s universities are ready to lead. Join us on May 29 @Empire_Club for the launch of our AI Task Force Report, featuring a panel of key voices shaping Ontario's role in the global AI economy & remarks from the Hon. @nolanmquinn & @kbardeesy: empireclubofcanada.com/event…… #ONpse #ONpoli

2
4
1,235
May 15
⏰ Final days to apply for Vector's Fall 2026 Research Internships!
Applications close Tuesday, May 19 at 1:00 p.m. ET
Work on research that matters:
🔬 Collaborate with Vector Faculty on cutting-edge projects
🌟 Opportunity to participate in IMPACT Mentorship Program
🤝 Build your professional network
📚 Access career development opportunities
Don't wait – complete your application this weekend: na3.hubs.ly/y0sZNG0
Winter 2027 applications remain open until June 22
1
9
63
6,439
May 14
You want to build and deploy AI, not just theorize about it.
Vector's Fall 2026 Applied Internship Program has three paid positions open for students and early-career professionals ready for real project work. Join Canada's leading AI ecosystem and work on meaningful projects with our industry partners.
Here’s the deal 🧵👇
2
2
21
2,605
May 14
Three roles are open this fall:
💻 Applied Machine Learning Intern – build software that applies and scales ML research breakthroughs
🎯 Applied AI Program Design and Delivery Intern – help Vector's partners develop, deploy and scale their AI capabilities
🏛️ AI Adoption and Partnerships Intern, Broader Public Sector – support AI programs driving economic development through public sector partners
1
1
455
May 14
➡️ Applications close Thursday, May 28 at 1:00 PM ET.
Ready to advance your AI career? Apply now:
vectorinstitute.ai/programs/…
2
373
May 12
Introducing the 2026-27 Vector Scholarship in AI recipients! 🌟
We're thrilled to announce 100 exceptional graduate students across Ontario have each received a $17,500 scholarship – $1.75 million invested in Canada's AI future.
This year's cohort comes from 13 universities, spanning computer science, engineering, health informatics, data science, and business. Now in its ninth year, the program has supported more than 900 students at Ontario universities since 2018.
"We're proud to support 100 exceptional students this year with $17,500 scholarships, but the real value of the Vector Scholarship in AI is the powerful ecosystem they join. From day one, recipients are connected to mentors, peers and industry leaders who help transform them from graduate students into the researchers, entrepreneurs and practitioners who will define the next decade of AI in this province." – Melissa Judd, VP, Research Operations and Academic Partnerships, Vector Institute
Congratulations to all of this year’s recipients and all the best in your incredible journeys ahead.
Learn more at na3.hubs.ly/y0sQm80
2
3
29
4,812
May 12
Congratulations to the scholars and their universities: @CarletonU @McMasterU @OntarioTech @QueensU @TorontoMet @UofGuelph @uOttawa @UofT @UWaterloo @UWindsor @WesternU @YorkUniversity – we can't wait to see what you build 🚀
1
406
Vector Institute retweeted

May 7
🚀 Can #AI agents actually do science?
Current agents can optimize for predictive fit — but fail at recovering the underlying physical laws.
We introduce Stargazer🪐: a scalable benchmark environment for astronomical discovery🔭
Agents must:
• propose hypotheses
• design/update models
• fit noisy astronomical observations
• iteratively refine theories
• recover the true latent physical mechanisms
🪐 Main result:
Good curve fits ≠ good science
Even strong agents achieve:
• >70% statistical fit pass rate (Hard split)
• <6% recovery of the correct physical law
• On real observational data: 0/8 models succeed
The benchmark exposes a key gap between:
📈 predictive performance
vs.
🧠 mechanistic scientific understanding
📄 Paper: arxiv.org/abs/2604.15664
💻 Demo: aips-uoft.github.io/Stargaze…
Authors:
@XingeLiu1213 @TerryJCZhang @bschoelkopf @ZhijingJin @KristenMenou
Supported by:
@UofT @VectorInst @UofTCompSci @JinesisLab @MPI_IS @ELLISInst_Tue @EuroSafeAI

4
10
64
5,969