
Photos and videos

Jun 1
Vision Language Models are native 3D learners!
Jun 1

🎇Thrilled to release VLM^3! Most 3D vision papers nowadays still spend months/years designing complex archs/losses/augmentations for different tasks. Are they necessary? VLM^3 shows that most designs that you think are important for 3D vision are [not] important at all!

1
2
8
1,529
May 29
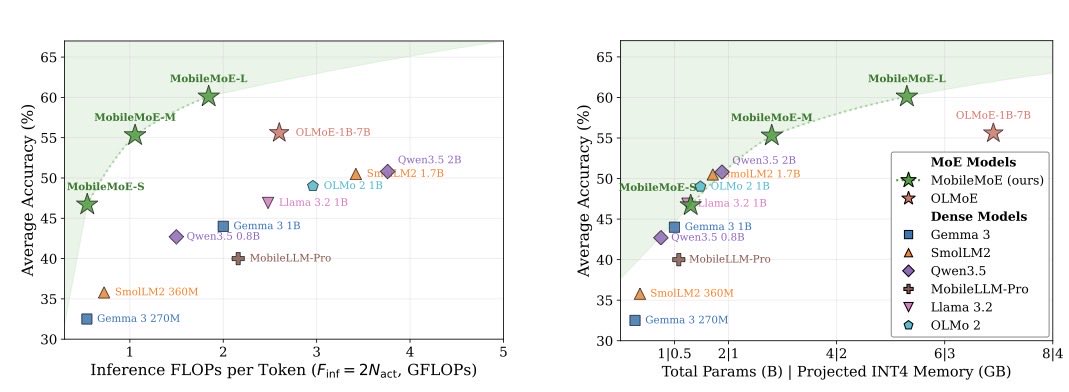
We just released MobileMoE, first sub-B-active-parameter MoE language model family.
MoE isn't just for 100B parameter models on servers. At sub-B scale, sparse expert routing lets you match dense models at 2-4x fewer FLOPs while fitting in mobile DRAM.
arxiv.org/pdf/2605.27358
1
3
191
Vikas Chandra retweeted

May 24
2/ the work by @vikasc and others at Meta AI shows that Trajectory Reduction Policy Optimization (dTPRO) significantly reduces the training cost of diffusion LLMs (dLLMs), a key step forward as scaled training has been a hurdle for dLLM to date. watch out for what comes from Meta here
arxiv.org/abs/2603.18806
1
1
1
1,072
May 20
Grateful to @sallywf and @EETimes for the thoughtful writeup of my Embedded Vision Summit keynote. The thesis in one line: the next decade of AI won't be won by the biggest model, but by the smartest, most efficient one that lives on the devices you wear!
eetimes.com/scaling-down-is-…
1
1
4
407
May 2
Audio is the most ignored perception modality in on-device AI.
Every smart glass, robot, and drone has a mic. Almost none fuse audio vision at perception time.
Vision-only is the vibe-coded version of multimodal perception.
3
240
Vikas Chandra retweeted
Apr 26
the market loves to talk hardware because stock prices go brrr but
the most interesting thing happening right now is in alternative model architectures

Apr 13

Diffusion models couldn't reason because RL was too expensive, not because the architecture was wrong. dTRPO collapses trajectory computation to one forward pass. On a 7B model: 9.6% GPQA, 4.3% HumanEval . The architecture question is open again.
Paper: arxiv.org/abs/2603.18806
1
16
8,522
Apr 29
1/ New @ieeeICASSP 2026 (Oral): "Exploring Audio Hallucination in Egocentric Video Understanding."
Audio-visual LLMs often "hear" things they didn't, inferring sounds from visual cues alone. We built a benchmark to quantify it.
1
2
9
663
Apr 29
2/ Setup: 300 egocentric videos, 1,000 sound-focused Q/As, with a taxonomy that separates foreground action sounds (from the user's activity) and background ambient sounds.
1
1
99
Apr 29
3/ Even Qwen2.5 Omni hits just 27.3% on foreground and 39.5% on background sound accuracy. Audio hallucination is widespread in today's AV-LLMs, and robust evaluation has to be a first-class metric for AR/wearable use cases.
📄 arxiv.org/pdf/2604.23860
1
122
Apr 26
Efficient Video Intelligence in 2026 🧵
Five years ago video understanding meant action recognition on Kinetics-400. Now VLMs reason over hour-long footage, foundation-grade tracking runs at 16 FPS on a phone, and one sub-100M backbone replaces four specialized encoders.
1
2
279
Apr 26
What's still hard is mostly deployment: streaming at hour-plus durations, sub-watt AR glasses, open-set anomaly detection, cross-camera reasoning, spatial grounding through cuts, closed-loop eval.
The bottleneck moved from models to the stack around them.
1
115
Apr 26
Long post pulling the field together, leaning on my group's work (EUPE, EfficientSAM, Efficient Track Anything, EdgeTAM, LongVU, EgoAVU, VideoAuto-R1, DepthLM, ParetoQ) placed against the parallel work in each section.
v-chandra.github.io/efficien…
97
Apr 13
Diffusion models couldn't reason because RL was too expensive, not because the architecture was wrong. dTRPO collapses trajectory computation to one forward pass. On a 7B model: 9.6% GPQA, 4.3% HumanEval . The architecture question is open again.
Paper: arxiv.org/abs/2603.18806
1
13
6,191
Apr 13
Standard approach to long video: more frames, bigger context. Tempo flips it. A small VLM reads the question first, then compresses the video around it. 6B params. 8K visual tokens. Outperforms GPT-4o and Gemini 1.5 Pro on hour-long videos. arxiv.org/pdf/2604.08120
189
Vikas Chandra retweeted

Apr 12
Been thinking about what this paper really means.
"Video diffusion" and "World Models" are becoming synonymous. Neural Computers are basically video diffusion world models for terminal envs and GUI.
Lots of talk last week about automating Manim videos. In theory, we should be able to train these world models on a 10000 hours of diverse manim videos and "see where it goes"
If a NC can generate outputs to terminal commands, it should be able to generate videos like this directly from prompt too.
Without writing code.

16
68
687
119,959
Apr 13
Classical computers run programs. Agents wrap models around programs. Neural Computers ask: what if the model is the program, the memory, and the machine? New paper exploring fully learned runtimes where computation emerges from weights alone.
Paper: arxiv.org/abs/2604.06425
1
1
84
Vikas Chandra retweeted
Apr 13
the market is reacting to the memory shortage by buying Sandisk assuming that labs continue to run less optimized versions of their own models and overspend on hardware but the longer term signal to take from the memory wall is to focus on the continued scaling down of models
deployed compute has scaled 3x every 2 years while memory bandwidth has only scaled 1.6x over 20 years - every new GPU generation widens this gap - but we've also been grossly overusing memory via the common training mode. APOLLO showed that AdamW, the standard LLM optimizer, stores redundant state for every single parameter, and that coarser gradient approximations achieve the same training quality with a fraction of the memory, enabling model pre-training on a 1/8 the GPU capacity. many more proof points are coming to light re: optimizing algorithms and efficiency of smaller models. in fact small models can outperform much larger models by spending more compute at inference time
good read on this from @vikasc
2
4
28
2,975

Vikas Chandra retweeted

Apr 10
🫱 Introducing 𝐍𝐞𝐮𝐫𝐚𝐥 𝐂𝐨𝐦𝐩𝐮𝐭𝐞𝐫s:
𝐰𝐡𝐚𝐭 𝐢𝐟 𝐀𝐈 𝐝𝐨𝐞𝐬 𝐧𝐨𝐭 𝐣𝐮𝐬𝐭 𝐮𝐬𝐞 𝐜𝐨𝐦𝐩𝐮𝐭𝐞𝐫𝐬 𝐛𝐞𝐭𝐭𝐞𝐫, 𝐛𝐮𝐭 𝐛𝐞𝐠𝐢𝐧𝐬 𝐭𝐨 𝐛𝐞𝐜𝐨𝐦𝐞 𝐭𝐡𝐞 𝐫𝐮𝐧𝐧𝐢𝐧𝐠 𝐜𝐨𝐦𝐩𝐮𝐭𝐞𝐫 𝐢𝐭𝐬𝐞𝐥𝐟?
Beyond today's conventional computers, agents, and world models, Neural Computers (NCs) are new frontiers where computation, memory, and I/O move into a learned runtime state.
We ask: whether parts of runtime can move inward into the learning system itself. This is our first step toward the Completely Neural Computer (CNC): a general-purpose neural computer with stable execution, explicit reprogramming, and durable capability reuse.
Work done with Mingchen Zhuge (@MingchenZhuge), Changsheng Zhao, Haozhe Liu (@HaoZhe65347 ), Zijian Zhou (@ZijianZhou524 ), Shuming Liu (@shuming96 ), Wenyi Wang (@Wenyi_AI_Wang ), Ernie Chang (@erniecyc ), Gael Le Lan, Junjie Fei, Wenxuan Zhang, Zhipeng Cai (@cai_zhipeng ), Zechun Liu (@zechunliu ), Yunyang Xiong (@YoungXiong1 ), Yining Yang, Yuandong Tian (@tydsh ), Yangyang Shi, Vikas Chandra (@vikasc), Juergen Schmidhuber (@SchmidhuberAI)

30
134
538
218,634