
777 Photos and videos










Pinned Tweet

25 Nov 2025
If you're excited about helping define what the UX and pattern language for a future of agentic and self-assembling enterprise software, please reach out!

We're looking for NYC-based design engineers to join our small, talent-dense team.
This is an opportunity to define the frontier of HCI. We're building the platform for self-assembling, self-optimizing software already in production with consequential enterprises.
Our eng team is made up of folks who have built and maintained large open-source projects like Neovim and Analytics.js and scaled massive data systems at companies like Google, Stripe, Wix, and Segment.
DM if you are interested or know someone who might be!
3
17
4,267
Jun 12
I want to love Fable, and haven't truly put it through the wringer, but so far it has a lot of the Opus smells I don't like.
1
127
Jun 5
you can whine about ensloppification or you can take advantage of the generationally low bar that exists for everything now
when we post a job opening 9/10 applications are total slop, all it takes is one thoughtful email to get properly looked at - but no one puts in the effort
2
13
452
Jun 5
there's a good chance society does away with factory farming and animal cruelty as AI gives us more empathy for non-human intelligence
1
3
97
Victor Mota retweeted

Jun 1
Another thing: what you get from writing things yourself isn't just the code. It's an improved understanding of what the code does. That mental model is what lets you come up with further improvements, or invent a different way of doing things. You can't come up with ways to improve a blackbox you don't understand.
For most projects this doesn't really matter, because the code is the only thing you need. But if you're doing something novel, if you're doing research, the code is not the most important part. Understanding what the code does is the most important part.
15
42
670
29,108
May 31
Firebolt just published a fascinating breakdown they completely rebuilt their data warehouse platform architecture with a verifiable agent harness for an agent-centric future.
They propose that for the agentic future - one where agents both develop and use the platform - database infrastructure should be monolithic and single tenant.
Interestingly, they also rebuilt their catalog and metadata service using the new Ducklake spec in order to benefit from an open standard and a verified oracle.

1
1
213
Victor Mota retweeted

May 30
using AI for coding is a deeply technical engineering craft
most people don't approach it as so, and don't get the results we associate with high craft
but the ones who do have been sprinting ahead
more tokens wont save you, more thinking skill llm intuition will
have been saying this for almost 9 months now

i have seen enough proof now that using a coding agent is a deep skill
it's confusing because the people you see heavily using them produce horrible results
but that's because it's a skill! you can get better and the ceiling seems pretty high - this is very exciting to me
43
47
656
70,971
May 31
When they announced that “feature” I was pretty sure they had misspoken.
Turns out it *actually* turns on the tokenmaxxing mode if you just say the word “workflow”??
May 31

So every time I say the word 'workflow' in Claude Code...
(let's say, when I'm creating a new GitHub workflow)
...it tries to enter 'workflow' mode, spinning up dozens of subagents to complete my task.
Stupid fucking thing
340
May 29
Expectation: "I'm sorry, Dave. I'm afraid I can't do that."
Reality: "Good pushback — you're right to question it. I overstated it. Want me to.. "
2
161
May 27
Besides being much smarter, gpt 5.5 is a much more “neutral” model than opus 4.6.
You can always tell when a code change was written by opus. It tends to be extremely reward hacky and comment-ridden, whereas with codex, you can't actually distinguish it.
It’s much more steerable and lets the developers preferences shine through.
1
3
749
May 25
From @mitsuhiko 's latest post on AI and the Pi codebase.
It's becoming more and more obvious that coding agents tend to just work in very incremental, short term fashion to accomplish any given task - as a result of the way they've been RL'd.
We collectively need to name this so we can work to avoid it. It's a special type of slop that needs its own term.
1
8
383
May 25
Good articulation of a problem with AI not being self-limiting enough.
It feels like we haven't yet given a name to the issue of LLMs being too incremental and reward-hacky rather than pushing back on ideas and suggesting rework of existing code.
It feels like the core thing that leads AI codebases into the pit of despair.
May 6

Skill used to be a natural speed limit to what you could do in software engineering - but that's no longer true.
A junior engineer could only write so many lines of code that compiled and worked, and their skill was the rate limiter. As they got better the scope of what they could do increased along with the speed which they could do it.
With AI, that's no longer true. The raw output a junior vs senior engineer can produce is roughly the same, yet the quality and risk blast radius is vastly different between the two.
On the one hand, that's great - you're no longer bottle necked by technicalities that may or may not be relevant to what you're trying to achieve (ie. the particular syntax of a language).
But on the other, you now don't have any backpressure. Someone with lesser skill can produce as much in volume as an expert (which Chamath seems to think makes the latter no longer relevant !!) obsfucating the risk and tech debt that used to be naturally limited.
The biggest problem of all is that on the surface the two look the same - which explains a lot of the exec AI psychosis we're seeing right now.
739
Victor Mota retweeted

May 23
holy shit where’s the evals to validate this holy shit.
May 22

HOLY SHIT !! @cursor_ai 's /thermo-nuclear-code-quality-review skill is nuts
It ran for around 30 mins on my PR and immensely improved the code quality.
It's 67x better than /simplify from Claude code..
13
4
326
110,912
May 21
tbh I wish software engineers had a similar aversion to AI code. it's great to use AI, but I shouldn't be able to tell you used it.
my fiancee saying she thinks non-tech people are better users of AI because they don't want people to know they're using it
May 20

why do people (including me) have an aversion to AI writing but not as much to AI code? if a piece of text smells AI i stop reading it but i use things coded entirely with AI every day
1
1
4
473
May 20
Assuming the problem is trivially verifiable - wouldn't a better metric be compute-normalized solve rate.
Given test-time-compute is a log axis, total compute used to get on average 1 solution for the 0.1 pass@1 (ie. 10x) may be much less than the total for 0.5 (ie. 2x an exponentially larger amount).
2
523
May 16
Corporate memos are an art form.
Are there any good collections (books, archives) of the greatest memos that have been made public?
Not talking about letters made for public consumption or VC investment memos , strictly internal memorandums.
2
1
446
May 16
One of my favourite things at google and Stripe was reading memos from @patrickc and @collision , engineering leaders and early employees
111
Victor Mota retweeted

May 14
phenomenal take.
hard to overstate the importance of ASC 350-40 here.
when it comes to *clerical* (G&A) work, frontier models are for codifying, not for performing.
in enterprise, creation of bespoke internal "Corporate" software (and continuous self-assembly thereof) is the killer app
May 13

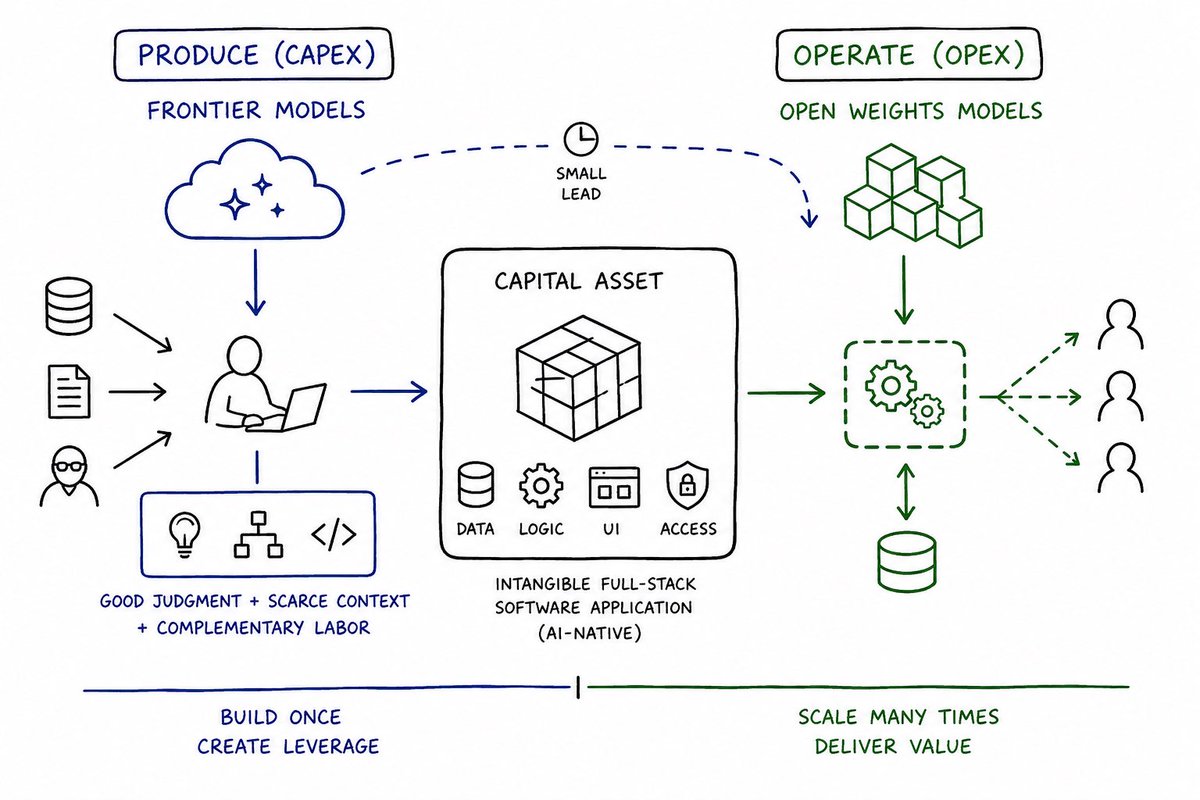
"...frontier models are useful for producing capital assets. Open weights models are useful for operating them..."
Here's how I'm thinking about frontier vs. open weights models atm:
As long as the Labs can maintain a meaningful, if relatively small in terms of the time it takes to catch up, lead versus the open weights models on the margin, it'll often be the economically rational decision to pipe your problem in context through OpenAI or Anthropic's latest offering and not the open weights models.
That being said, I do suspect there's room in the real economy for both. One way of thinking about this is that frontier model tokens and the complementary labor that uses them should probably be capitalized as you take good judgment and scarce context and turn it into a capital asset, e.g. an intangible full-stack software application that unlocks capacity across the business, making a subject matter expert's logic and data accessible to team members asynchronously and in an AI-native way via MCP.
On the other hand, open weights models would seem to make more sense as OPEX spend once something is known and scaled. If there is some probabilistic inference that needs to happen at runtime to make that capital asset available to a larger audience, then using those open weights in production might be the move.
So, frontier models are useful for producing capital assets. Open weights models are useful for operating them.
1
7
1,472