
Visual Inference Lab of @stefanroth at @TUDarmstadt. Research in Computer Vision and Machine Learning.
Joined April 2012
- Tweets 177
- Following 391
- Followers 859
- Likes 629
53 Photos and videos












Visual Inference Lab retweeted

Had so much fun at #CVPR2026! 🎉
Really happy to have presented two papers this year and discussed them with so many people.
Both projects came out of my time at @visinf, TU Darmstadt, last year. Very grateful to @stefanroth for hosting me and helping shape them from the beginning, and to all my co-authors for being part of this 😊

4
4
86
5,073
Visual Inference Lab retweeted

Jun 7
INSID3 segments objects across domains using ONLY ONE annotated example
it works entirely without a segmentation decoder, task-specific fine-tuning, or external mask generators like SAM
CVPR 2026 paper with enormous practical potential
8
82
636
53,499
Visual Inference Lab retweeted

Today!
I'm going to present MARCO in Oral Session 4D at 2 pm, and later at poster #20!
Don't miss it :)

✨#CVPR2026 Oral ✨
A tale of a failed experiment: what if you fine-tune DINOv2 on sparse keypoints, beat every benchmark, only to discover it performs worse than the original frozen model on novel keypoints?
🚀MARCO closes this gap: a unified model for generalisable correspondences
github.com/visinf/MARCO

2
8
51
9,585
Visual Inference Lab retweeted
✨ #CVPR2026 Oral ✨
INSID3 turns a frozen DINOv3 into a training-free in-context segmenter across domains and granularities!
Excited to present our work today in Oral Session 4D (14:00–15:15). Come by our poster later if you’d like to chat:
📍 Poster #19
🕓 16:00–18:00
See you there!
5
19
125
10,031

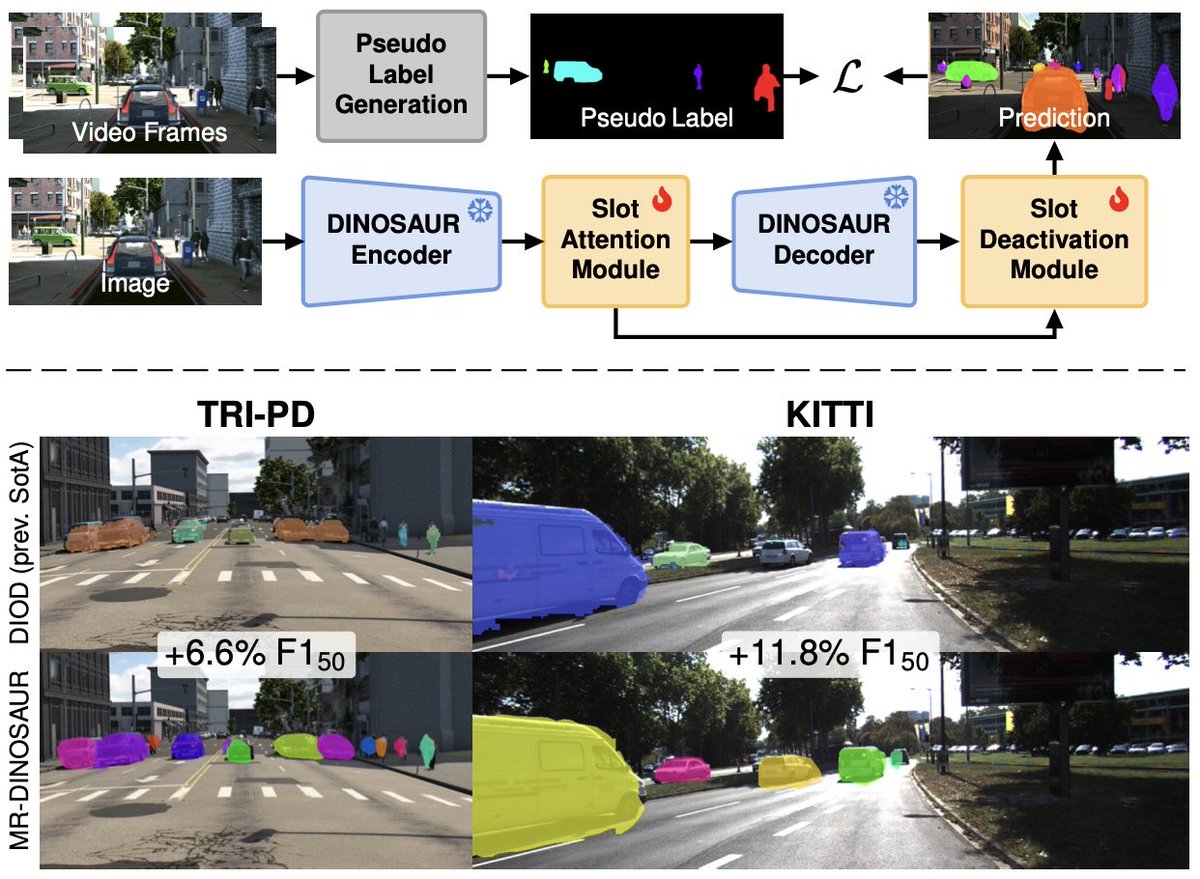
📢 [CVPR’26] Can we learn to detect, segment, and track every object in a video without human supervision?
Yes, we introduce VideoCUPS, the first unsupervised video panoptic segmentation (VPS) method: 1. Get pseudo-labels from monocular videos. 2. Train a VPS model on them.
8
72
433
27,367
When fine-tuned with just 10% of labels, VideoCUPS already matches a fully supervised model trained on all Cityscapes-VPS labels, and outperforms the DINO-initialized baseline significantly.
1
6
644
Work by: @ChristophR1996*, @olvr_hhn*, @neekans, @lealtaixe, C. Rupprecht, D. Cremers and @stefanroth
📄Paper: arxiv.org/abs/2606.04925
🌍Project Page: visinf.github.io/videocups/
💻Code: github.com/visinf/cups
📹Video: youtube.com/watch?v=lDvgajKB…
👁️CVPR: Friday, Poster Session 2 #333
3
15
659
[5/6] MUFASA: A Multi-Layer Framework for Slot Attention
S. Bock*, L. Schüßler*, @krissingh_ , @schaub_simone , @stefanroth
Paper: arxiv.org/abs/2602.07544
Project Page: visinf.github.io/mufasa/
1
4
165
[6/6] Multimodal Knowledge Distillation for Egocentric Action Recognition Robust to Missing Modalities
@dustin_carrion*, M. Santos-Villafranca*, A. Perez-Yus, J. Bermudez-Cameo, J.J. Guerrero, @schaub_simone
Paper: arxiv.org/abs/2504.08578
Project Page: visinf.github.io/KARMMA
3
127
[1/3] Multimodal Knowledge Distillation for Egocentric Action Recognition Robust to Missing Modalities
by @dustin_carrion*, Maria Santos-Villafranca*, Alejandro Perez-Yus, Jesus Bermudez-Cameo, Jose J. Guerrero, and @schaub_simone
1
2
9
393
[2/3] KARMMA is a multimodal-to-multimodal distillation framework for egocentric action recognition that does not require modality-aligned data and supports any subset of modalities at inference. It produces a lightweight student robust to missing modalities without retraining.
1
1
185
[3/3] Project page: visinf.github.io/KARMMA/
Poster (ICRA): Thursday, 03:00 PM, P207 (Hall C - ThI2I)
Poster (CVPRW): Thursday, 10:00 AM, A2A-MML Workshop, Hall A
1
181
Visual Inference Lab retweeted

May 28
In-context learning suggests that a model has learned versatile representations. What if we use in-context learning itself as a training task for visual representations?
📣 Introducing 𝗟𝗜𝗟𝗔: 𝗟𝗶𝗻𝗲𝗮𝗿 𝗜𝗻-𝗖𝗼𝗻𝘁𝗲𝘅𝘁 𝗟𝗲𝗮𝗿𝗻𝗶𝗻𝗴 ✨ @CVPR 2026 Oral ✨
𝗟𝗜𝗟𝗔 trains on videos without manual annotation.
Key idea: An optimal linear mapping that predicts dense cues (e.g. depth, flow), estimated on one video frame, should also predict the corresponding cues of another frame from the same video.
This yields compelling results on dense vision tasks: video object segmentation, (zero-shot) semantic segmentation and surface normal estimation.
Paper, code, models and demo: lila-pixels.github.io
Joint work with @ma_sundermeyer, Hidenobu Matsuki, David Joseph Tan and @fedassa (and special thanks to David and Federico for hosting my research visit at Google).
#cvpr2026 @Google @MunichCenterML @tumcvg @TU_Muenchen
10
53
399
31,429