
audaciter. building things with and for AI at vibes.dev
Joined February 2009
- Tweets 2,327
- Following 4,078
- Followers 645
- Likes 8,220
182 Photos and videos









Pinned Tweet

Mar 10
In the midst of a war against ourselves from the future and nobody seems to notice shit.
1
994
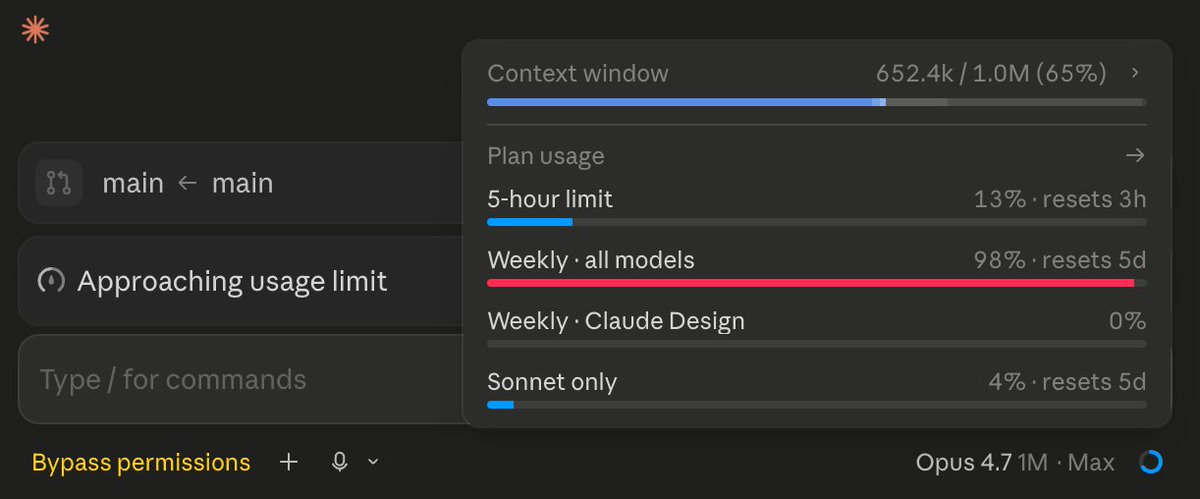
Lots of weird tool calling and misplaced quotes and closing braces all of a sudden in GPT-5.5 AND Opus 4.8.... very odd.
18

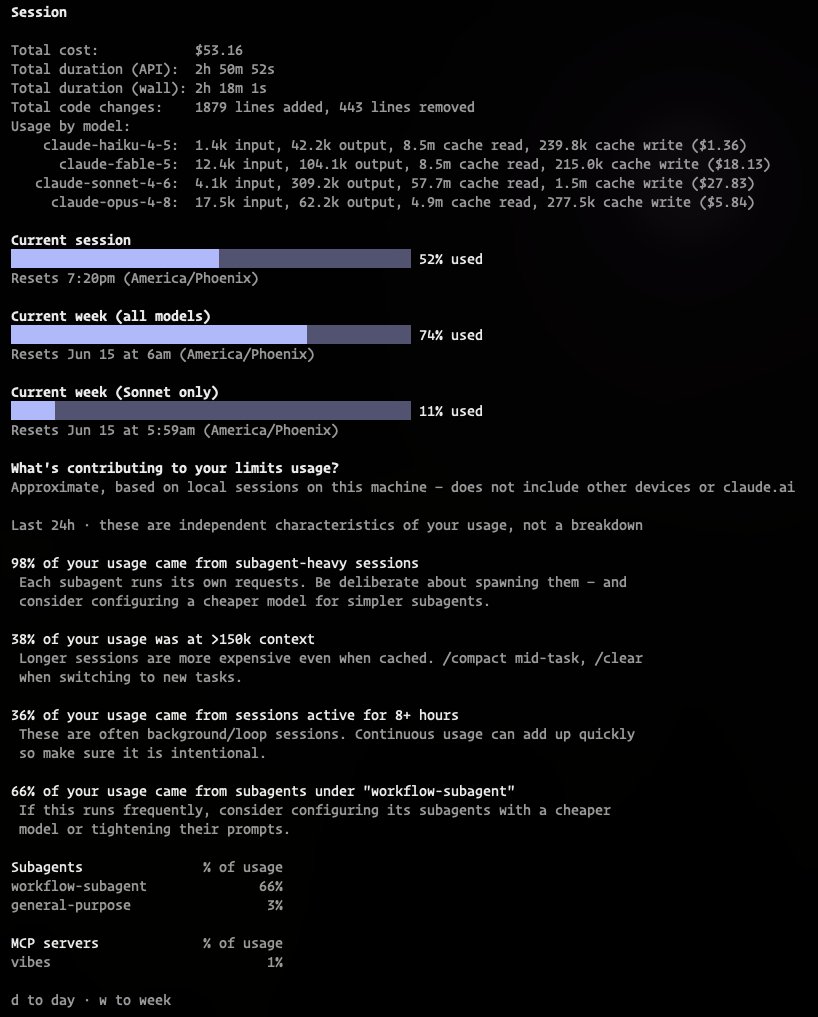
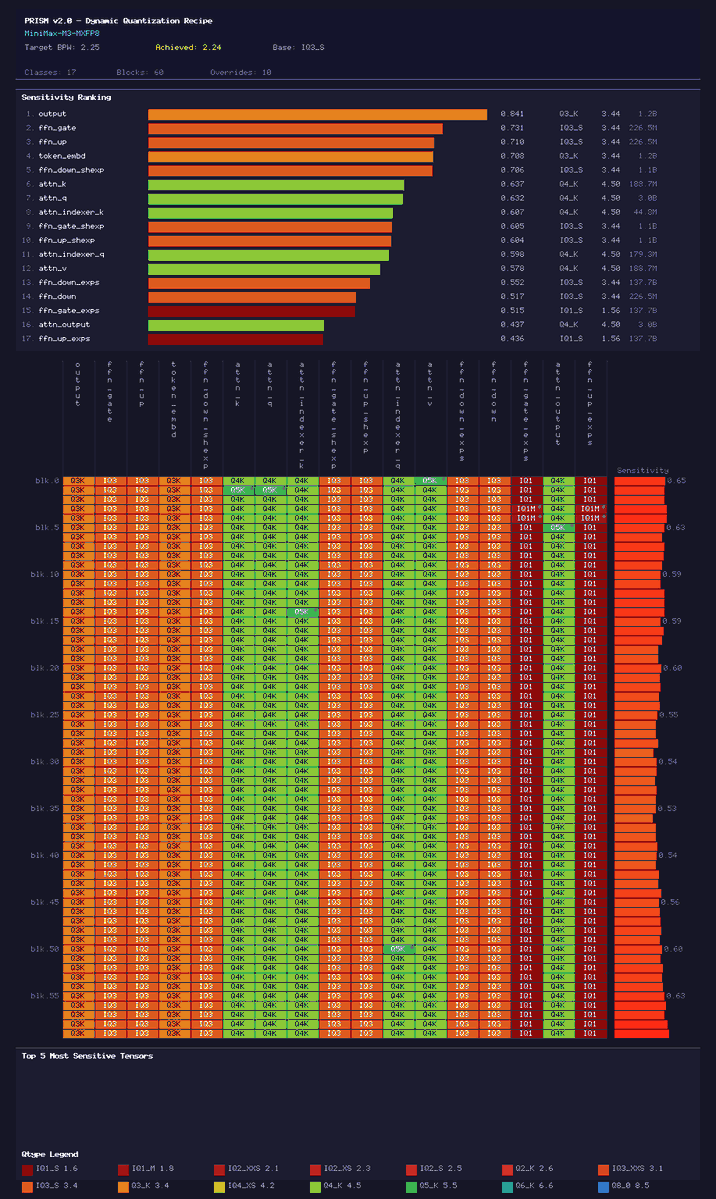
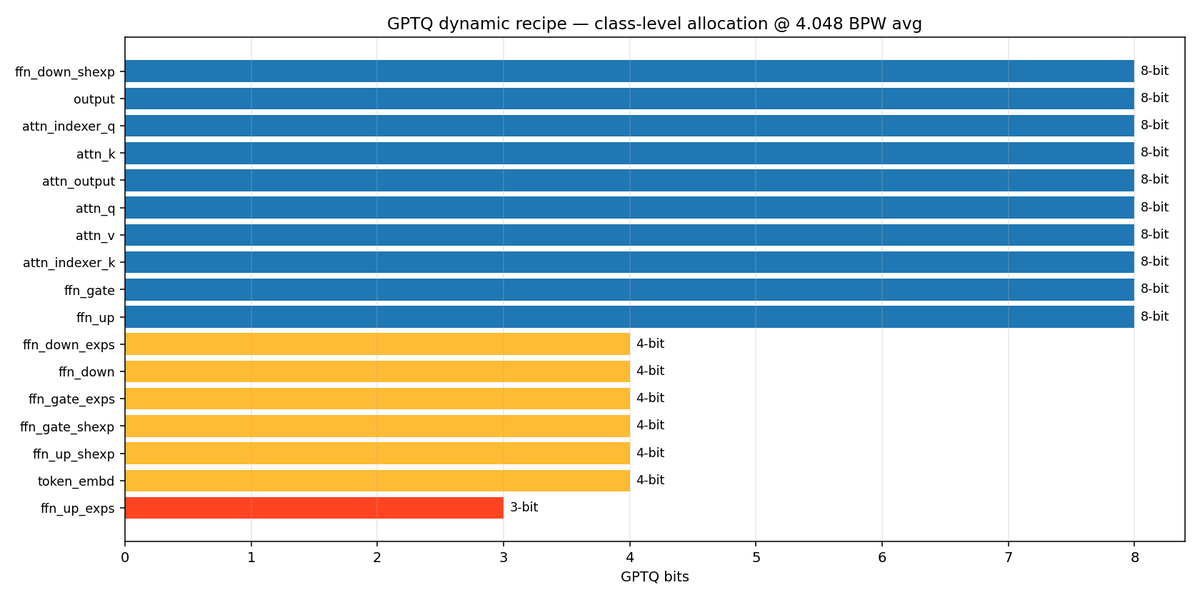
Open frontier intelligence, in your hands - the MiniMax-M3 PRISM Dynamic-Quant recipe is ready! 428B parameters compressed from the ~450GB MXFP8 release down to 119GB, per-tensor sensitivity ranking that protects attention and shared-expert paths (3.4–4.5 bpw) squeezing the two largest routed-expert tensor blocks. Still too large for most local rigs, so next we prune the experts that won't harm agentic/coding performance collapse. Target: 60–80GB.
2
1
25
1,514
Jun 12
The great reset?

We heard you wanted to use Codex rate limit resets on your own time.
Starting today, we’re rolling out the ability to save rate limit resets to use later.
We’re starting Go, Plus, Pro, and Business users with one free reset:
41
Jun 10
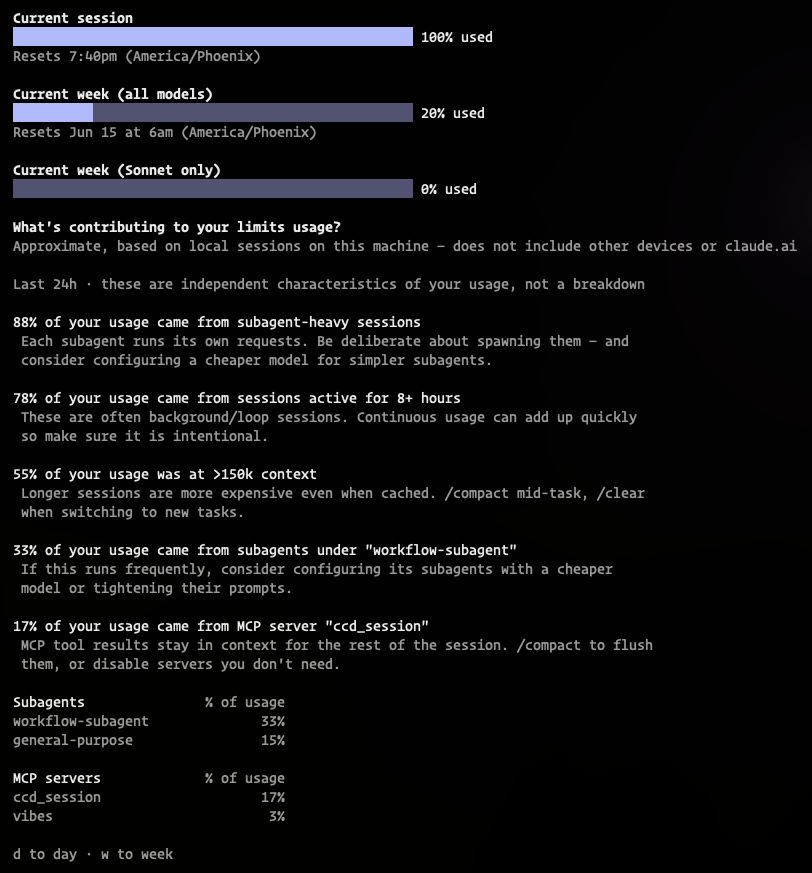
ran out with 6 minutes left in the window. perfectly balanced, as all things should be.
1
61
Jun 11
@harper this is with thrifty skills today, 3 parallel fable orchestrators didn't come close to using my 5h. unreal.
1
890
Drew Ewing retweeted

Jun 9
Don’t get owned by your tools.
Install with Homebrew. Harden with Automic Vault.

1
2
5
5,782
Jun 10
If you are burning your token allocation in 3 messages with Fable in Claude try out the thrifty skills shared by @harper and 2389.ai

If you wanted to try out fable but are scared of blowing away your token budget do we have a skill for you!
Its called Thrifty. It makes things cheaper.
We built thrifty for claude code around a better split:
strong model plans → cheap model executes → gate verifies.
1
1
852
Jun 10
Fable will plan and delegate to a Sonnet orchestrator who then delegates to Hakiu. Major token savings and so far so good.
15
Jun 9
So far Fable is making VERY good decisions in an incredibly large monorepo and is drastically reducing token spend and increasing accuracy over 4.8 which was also already very good.
1
44
Jun 9
Working on my security app, authz, secrets stores and honey tokens without issues. Deploying to production, diagnosing production issues, smoke testing and evidence gathering. Across the board just better (so far).
1
37
Jun 9
grok-build is incredibly fast but not very useful unfortunately. it refuses to do even the simplest self validation, it is the laziest model I have worked with in a long time, and you'll spend more time correcting and handholding it than you will waiting from tokens on local 122b
1
52
Jun 9
I can tell it wants to be a good model but it's too willing to please and too unwilling to keep going and hold itself to a standard of behavior that leads to good results
1
12
Jun 9
It can probably be improved dramatically with different prompts, will try some iterations and see what I see.
10